一、上次课回顾
- https://blog.csdn.net/SparkOnYarn/article/details/105430370
- 主要讲了ERP的一些模块(基础信息维护、采购、销售、零售流程维护),仓库阈值、仓库盘点;一堆数据集合,挖掘有效价值,提供企业决策;设计大数据项目架构要考虑上游来的数据类型(log类型、DB类型);报表和实时大屏,底层存储数据一般只存储最小粒度的多维汇总数据;静态报表和动态报表的相辅相成;
- 离线的数仓分层,ODS(operation data store) --> DWD(data warehouse detail) --> DWS(data warehouse service) --> ADS(application data store)
二、场景(业务表补updatetime字段)
MySQL中的建表规范中有一个createtime和updatetime,MySQL业务表由于开发水平参差不齐,未加updatetime字段的话;MySQL --> Hive,存在数据:
| MySQL | Hive |
|---|---|
| id、value、createtime | id、value、createtime |
| 1 100 2019-12-10 10:00:00 | 1 100 2019-12-10 10:00:00 |
-
这条数据是在12-10号发生的,但是我们在12-11号早上10点的时候对这条数据进行变更如下:1 200 2019-12-10 10:00:00,问题就出现了:
在12号零点的时候抽取的就是11号整天的数据,根据createtime抽取的话无法抽取到我们在12月11号修改的这条在12月10号产生的数据;在12号抽取不到这条数据了。 -
SQL语句如下:(select * from t where createtime>=‘2019-12-10 00:00:00’ and createtime < ‘2019-12-11 00:00:00’),代表着的是从12月10号零点到12月11号零点之间的数据;
T+1模式:一天卡一天,11号只抽10号的数据,12号只抽11号的数据,其实就是一个sql把数据查出来。
小结:
updatetime字段:不影响业务,是数据库自己做,不需要上游代码sql做任何变更:
SQL如下:
-
alter table xxx
add column updatetime timestamp not null default current_timestamp on update current_timestamp; -
生动的理解:
| id | value | createtime | updatetime |
|---|---|---|---|
| 1 | 100 | 2019-12-10 00:00:00 | 2019-12-10 00:00:00 |
| 1 | 200 | 2019-12-10 00:00:00 | 2019-12-11 10:00:00 |
所以生产上要使用updatetime字段进行抽取:
1、QA环境中测试使用一段时间再推到生产上;
2、生产上MySQL是主从架构部署:主节点 --> 写 从节点 --> 读 --> 再申请一个MySQL从从节点上加上updatetime字段;
3、如果第一、第二步都做不到的话,就需要每次sqoop抽取数据前先把Hive中的数据删除,全量拉取;
4、MySQL中有一个binlog二进制文件 --> canal、maxwell --> Kafka --> flume --> hive/hdfs (伪实时)
–> Spark/Flink --> hive/hbase (实时)
删除数据怎么办?
delete from t where id = 100; 物理删除(思考MySQL中使用物理删除的时候在Hive中应该怎么删除???)
update t set delflag=1 where id = 100; 逻辑删除
2.1、数据建模-星型模型
本质其实就是建立表结构:商品 --> SKU,如果在上游表设计时很规范(主表、明细表、商品表、供应商表、商品类别表),下游就很轻松了;
维度建模:包含三种模型:
1、星型模型:
一个fact事实表,多个dim表
J总公司还存在变态版星型模型
2、雪花模型:
3、星座模型:
1、星型模型如下:
- depotitem单据事实表:这张表就是ruozedata_depotitem;规范:一个fact事实表,多个dim表(维度表)
- fact表:订单事实产生的(事实产生的),dim表:时间维表(数据不会发生变化的表,createtime一旦生成就是永远不会发生变化)、供应商维表(缓慢变化的表,比如供应商的名称,供应商银行卡号发生变化,供应商联系方式也发生变化)、仓库维表
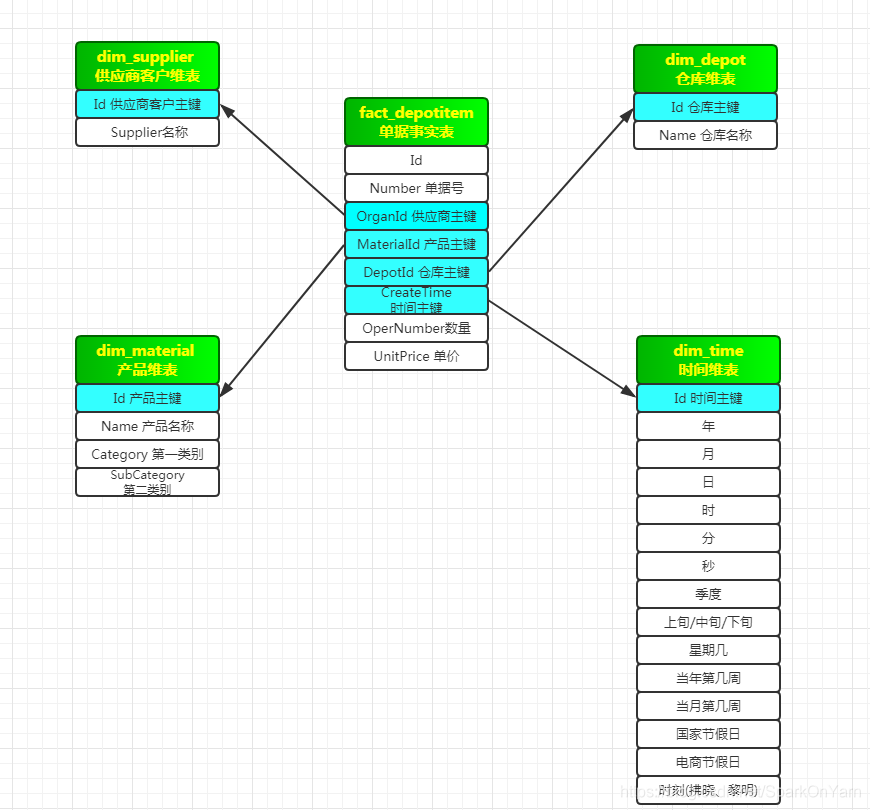
变态版星型模型:
fact_depotitem单据事实表:head主表+item明细表 --> fact_depotitems,是两张表join之后的一张表。
2.2、数据建模-雪花模型
- 仍然是一个事实表,多个dim表,是星型模型的扩展,不同的是维度表被规范化,进一步分解到附加表里;类比到erp数据库表:ruozedata_material和ruozedata_materialcategory表;

维度表设计符合3NF,规范化,有效降低数据冗余,但是性能相对肯定差了,同时也复杂,并行度低。
2.3、数据建模-星座模型
- 星座模型是星型模型的延伸,是基于多个事实表,而且共享维度信息。
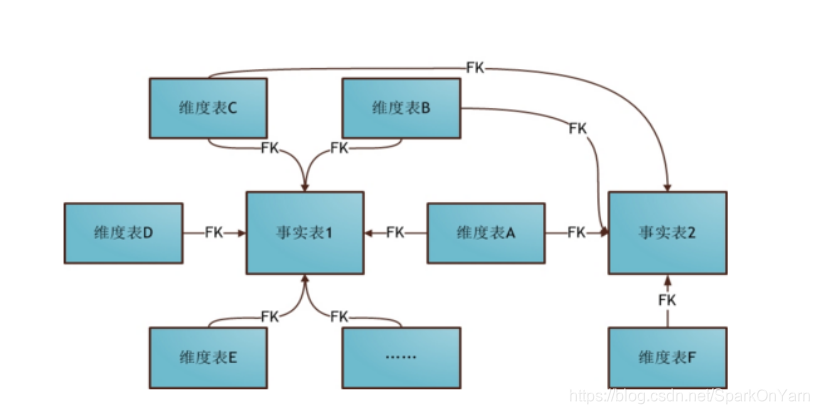
星型模型不符合3NF设计,反规范化,不存在渐变维度,数据是有冗余的以存储空间为代价,降低维度表连接数,提高性能。。比如地域表,存在数据:
商品名称 第一类别 第二类别
新鲜水果 热带水果 芒果
新鲜水果 热带水果 火龙果
此处的数据冗余指的是:第一类别、第二类别存储了两次,虽然此处冗余但是性能最好;
商品名称 类别ID
芒果 25
火龙果 25
这张表在MySQL中相当于是自己join自己,子父表:
| 类别ID | 名称 | 父ID |
|---|---|---|
| 25 | 热带水果 | 18 |
| 25 | 热带水果 | 18 |
| 18 | 新鲜水果 | -1 |
| 18 | 新鲜水果 | -1 |
星座模型也是不符合3NF,业务复杂,开发也复杂,性能不高。
降维:商品+商品类别表 --> 商品表 没有用,数仓的理论知识在实战中基本是没有用的;
三、ERP项目架构
存储多维度的最小粒度汇总
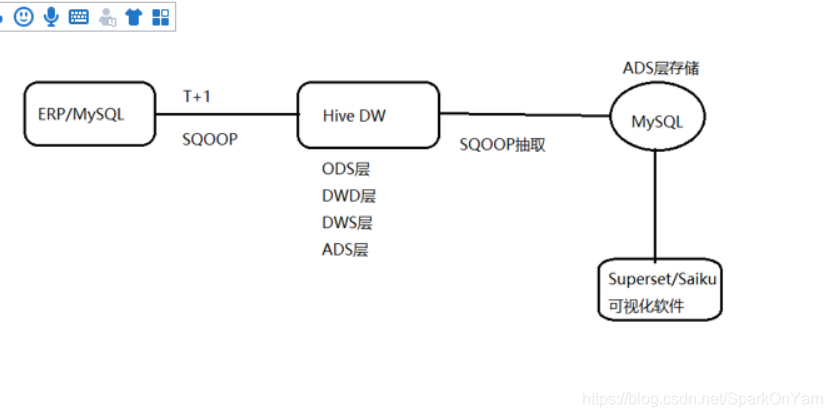
3.1、数仓分层流程图
ods商品表+ods商品类别表 --> dwd_sku(两张表合为一张表,降维),一般不用,是因为性能提升不了多少。
关于共性字段怎么找,运营、qa人员经常使用哪些表的哪些字段;做数仓是给别人使用的,提前沟通好即可;
事实表也分为明细事实表和聚合事实表:
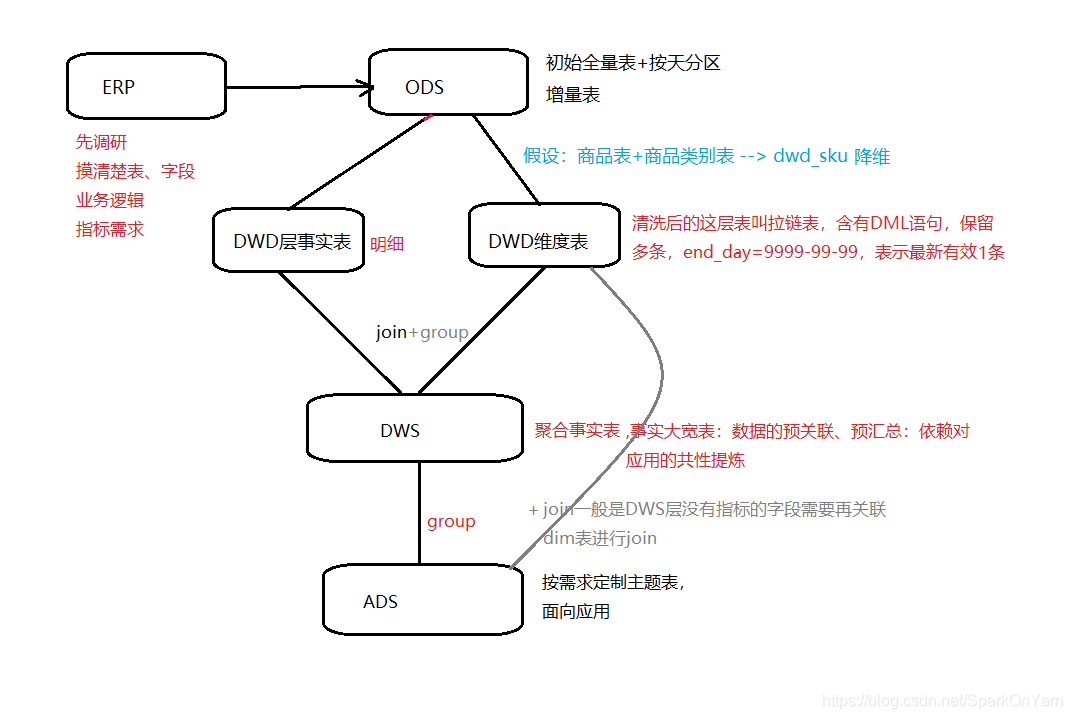
正常DWS层的数据直接做group by到ADS层,但存在一些需求DWS层没有指标的字段需要再关联dim维表进行join;
MySQL能做TopN,行转列,列转行,window下函数;这些MySQL中都能做,为什么要引进大数据框架呢?
上游的数据查询不动或者单点计算不出来,ERP mysql:一串sql join group by
Hive:join --> group by
还是上次课程中说的问题:直接ODS层出结果,写到ADS层?
- 数据仓库的分层也不是越多越好,合理的层次设计,以及计算成本,和人力成本的平衡,是一个好的数仓架构表现:
举例:ODS层的数据:5min的力度是200~300G,这种情况数据再流转到DWD层的话就吃不消;ODS层数据–》DWD–》DWS层是3份数据,如果乘以3副本的数,就相当于是9份数据;数据量大的话分层不仅占用空间,计算也会来不及跟上去;比如:快手、懂车帝、省卫视的直播数据确实是有这么大的。
比如数据在ODS层1T,–>DWD层 --> 再到DWS层数据就是9T;三副本的情况,每层存储3份;
所以我们需要评估上游现在的总数据量是多少G,评估一年增长多少?
如何评估:取字段最多最大的一张表:根据createtime字段取出2019年的总条数,取出其中一条字段大小,总条数X一条数据的大小;比如估算出来一张表1G,有100张表,再乘以一个系数:1G1003倍=300g
