一、项目结构
下面是一个典型的Scrapy项目结构,它主要包含了几个组成部分:
- scrapy.cfg:整个项目的配置文件,在实际编写爬虫项目的时候基本不需要编辑;
- qiushi:保存项目源码的文件夹,也可以称为包或者模块,此文件夹内的文件在引用模块时以此文件夹作为根目录;
- items.py:定义我们需要的数据项,爬取的各种内容将作为数据项的属性,这个文件在实际编写爬虫时是最先定义的!
- pipelines.py:数据处理管道,定义爬取数据项以后,如何处理每个数据项,比如保存到文本、数据库种,这个文件在定义spider之后才编写;
- settings.py:设置文件,用来配置爬虫用到的各个模块、类、方法使其生效,比如设置数据处理管道、配置用户代理、设置Proxy等,这个文件基本是最后编辑的;
- spiders:此目录下定义用于解析网页内容的爬虫,会用到
xpath的知识,一般编写完items.py之后编写这个文件; - middlewares:此目录中定义用到的代理,如用户代理(浏览器的headers),Proxy等。
C:\USERS\YENMA\DESKTOP\SCRAPYPROJECT\QIUSHI
│ scrapy.cfg
│
└───qiushi
│ items.py
│ middlewares.py
│ pipelines.py
│ settings.py
│ __init__.py
│
├───middlewares
│ customMiddlewares.py
│ __init__.py
│
└───spiders
qiushiSpider.py
__init__.py
二、编写步骤
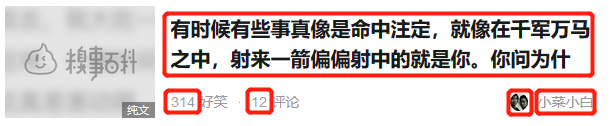
我们用一个例子来具体说明Scrapy项目的编写步骤。在这个例子种,我们爬取糗事百科首页推荐列表中每一个笑话条目中的【内容,好笑数,评论数,作者头像,作者】。
1.定义数据项
从项目需求我们已经知道,我们的每个数据项包含了【内容,好笑数,评论数,作者头像,作者】,我们很快就能写出类似下面的items.py:
import scrapy
class QiushiItem(scrapy.Item):
content = scrapy.Field()
funNum = scrapy.Field()
talkNum = scrapy.Field()
author = scrapy.Field()
img = scrapy.Field()
2.定义爬虫
这时候,我们需要打开糗事百科的首页,我们会发现所有的数据内容都被包含在一个class为recmd-right的div标签中,我们借助xpath首先从response中匹配它;然后我们从获得的div列表中逐个取出div标签,根据各项内容与div标签的相对位置关系,构造出对应的xpath表达式,准确的定位到各项数据内容,进而提取出来。
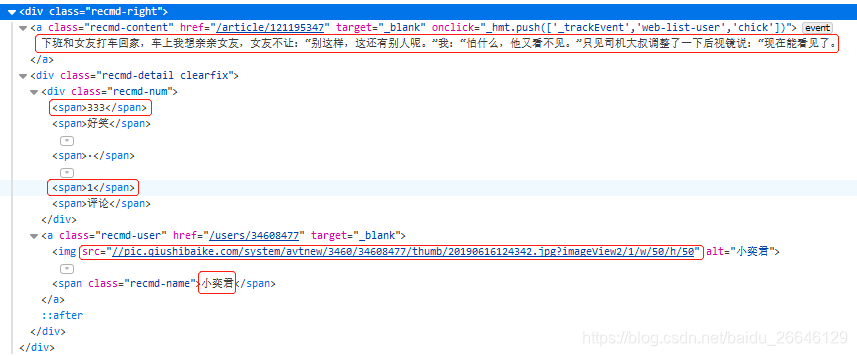
查看所有笑话条目,我们会发现,有些条目没有评论数这一项内容,这会导致爬虫爬取过程中报错,我们需要采取合理方式规避这一情况,也就是使用try...except为内容为空的数据项赋值为0。完整的qiushiSpider.py如下所示:
# -*- coding: utf-8 -*-
import scrapy
from qiushi.items import QiushiItem
class QiushispiderSpider(scrapy.Spider):
name = 'qiushiSpider'
allowed_domains = ['qiushibaike.com']
start_urls = ['https://www.qiushibaike.com/']
def parse(self, response):
subSelector = response.xpath("//div[@class='recmd-right']")
items = []
for sub in subSelector:
item = QiushiItem()
item['author'] = sub.xpath('./div/a/span/text()').extract()[0]
item['content'] = sub.xpath("./a/text()").extract()[0]
item['img'] = sub.xpath('./div/a/img/@src').extract()[0]
try:
item['funNum'] = sub.xpath("./div/div/span[1]/text()").extract()[0]
except:
item['funNum'] = '0'
try:
item['talkNum'] = sub.xpath("./div/div/span[4]/text()").extract()[0]
except:
item['talkNum'] = '0'
items.append(item)
return items
3 定义数据处理管道
第二步定义的爬虫已经能顺利解析得到数据项内容,接着我们要对爬取到的内容做后处理。这个后处理主要包括数据的再加工、资源获取和数据的持久化。
数据再加工:按照实际需求,对数据项中的属性进行编辑、格式化,构造出我们想要的数据。比如我们可以在爬取到的好笑数前加上英文字符串fun-,可以将爬取的英文字符串做大小写转换等。
资源获取:可以在这个阶段请求图片地址,并将图片保存在指定文件夹/数据库中
数据的持久化:爬取的内容需要保存下来,一般的文本内容我们会选择使用文本文件TXT保存,如果对内容结构化要求高或者便于程序处理可以选择JSON格式,如果数据量特大且想要更加规范并且要求有更高的检索效率,放在MySQL数据库是一个很不错的选择。
在我们的示例项目中,我们将爬取的内容保存到文本文件中,然后请求保存的图片路径下载图片并保存到指定文件夹,完整的pipelines.py如下所示:
# -*- coding: utf-8 -*-
import os
import time
import urllib
class QiushiPipeline(object):
def process_item(self, item, spider):
today = time.strftime("%Y%m%d", time.localtime())
fileName = today + 'qiubai.txt'
imgDir = 'IMG'
if os.path.isdir(imgDir):
pass
else:
os.mkdir(imgDir)
with open(fileName, 'a') as fp:
fp.write('-' * 50 + '\n' + '*' * 50 + '\n')
fp.write("author: \t %s\n" % (item['author']))
fp.write("content: \t %s\n" % (item['content']))
try:
imgUrl = 'http:' + item['img']
except IndexError:
pass
else:
imgName = os.path.basename(imgUrl) + '.jpg' # basename
fp.write("img:\t %s\n" % (imgName))
imgPathName = imgDir + os.sep + imgName
with open(imgPathName, 'wb') as fp1:
response = urllib.request.urlopen(imgUrl) # 下载图片
fp1.write(response.read())
fp.write("fun: %s\t talk: %s\n" % (item['funNum'], item['talkNum']))
fp.write('-' * 50 + '\n' + '*' * 50 + '\n' * 10)
return item
4 修改设置文件
在完成以上三项工作后万事就具备了,这个时候我们需要修改配置文件settings.py来使得我们的定义生效。在前面的内容中,我们主要定义了一个数据处理管道,这个部分是需要在设置文件中声明的,完整的settings.py如下所示:
# -*- coding: utf-8 -*-
BOT_NAME = 'qiushi'
SPIDER_MODULES = ['qiushi.spiders']
NEWSPIDER_MODULE = 'qiushi.spiders'
# Obey robots.txt rules
ROBOTSTXT_OBEY = True
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'qiushi.pipelines.QiushiPipeline': 10,
}
5.1 修改浏览器标识
对于一般网站,到4为止的几个步骤已经完全能hold住了,but…凡是最怕个但是,如果你要爬取数据的网站使用了反爬虫手段,你的小虫子可能还没爬到人家墙上就被拍死了。反爬虫手段有很多,最常见的一个就是检查浏览器标识(User-Agent)。Scrapy项目默认的User-Agent和实际浏览器的User-Agent是不一样的,我们需要在爬取之前,定义一个假冒的User-Agent来蒙混过关。我们把定义的这个User-Agent包装成一个中间件(Middleware)保存在middlewares文件夹中。我们定义的一个中间件customMiddlewares.py如下:
#-*- coding: utf-8 -*-
from scrapy.downloadermiddlewares.useragent import UserAgentMiddleware
class CustomUserAgent(UserAgentMiddleware):
def process_request(self, request, spider):
ua = "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3"
request.headers.setdefault('User-Agent', ua)
如果想让我们的定义中间件成功生效,我们还需要做什么工作呢?你猜对了,我们要修改settings.py文件!修改后的settings.py文件如下所示,你可以尝试和之前的做一些对比:
# -*- coding: utf-8 -*-
BOT_NAME = 'qiushi'
SPIDER_MODULES = ['qiushi.spiders']
NEWSPIDER_MODULE = 'qiushi.spiders'
# Obey robots.txt rules
ROBOTSTXT_OBEY = True
DOWNLOADER_MIDDLEWARES = {
'qiushi.middlewares.customMiddlewares.CustomUserAgent': 30,
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': None,
}
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'qiushi.pipelines.QiushiPipeline': 10,
}
是的,我们增加了DOWNLOADER_MIDDLEWARES项,并且将我们自定义的用户代理中间件优先设置为30,而将框架默认的用户代理中间件设置为None使其失效,以保证自定义User-Agent生效。
5.2 使用代理
另一个常见的反爬虫手段即封锁IP。网站管理员发现你的IP一直在高频率地访问网站,很可疑把你毙了。这种情况下我们要使用代理也就是借用IP来继续访问对象网站。如何获取、检验IP代理这里不做详细说明,本节主要说明在爬虫项目中如果使用IP代理。
与5.1类似,我们也需要将使用IP代理的源码封装成一个中间件,然后再settings.py修改设置使之生效。下面是修改之后的customMiddlewares.py文件和settings.py文件:
#-*- coding: utf-8 -*-
from scrapy.downloadermiddlewares.useragent import UserAgentMiddleware
class CustomUserAgent(UserAgentMiddleware):
def process_request(self, request, spider):
ua = "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3"
request.headers.setdefault('User-Agent', ua)
class CustomProxy(object):
def process_request(self, request, spider):
request.meta['proxy'] = 'http://123.163.21.221:808'
注意,需要让CustomProxy在HttpProxyMiddleware之前执行!
# -*- coding: utf-8 -*-
BOT_NAME = 'qiushi'
SPIDER_MODULES = ['qiushi.spiders']
NEWSPIDER_MODULE = 'qiushi.spiders'
# Obey robots.txt rules
ROBOTSTXT_OBEY = True
DOWNLOADER_MIDDLEWARES = {
'qiushi.middlewares.customMiddlewares.CustomProxy': 10,
'qiushi.middlewares.customMiddlewares.CustomUserAgent': 30,
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': None,
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware': 20,
}
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'qiushi.pipelines.QiushiPipeline': 10,
}
三、完整的爬虫源码
为了对项目有完整的更加直观的了解,把本文介绍的小项目附在下方供下载参考。爬虫执行的代码也一同附上。如果爬取顺利的话,您在将qiushi目录下看到新增一个20190903qishi.txt文本文件和一个IMG文件夹,他们分别保存的是爬取的文本内容及保存的用户头像图片。
源码地址:https://download.csdn.net/download/baidu_26646129/11662449
# 如何启动爬虫
pip install scrapy
cd qiushi
scrapy crawl qishiSpider
