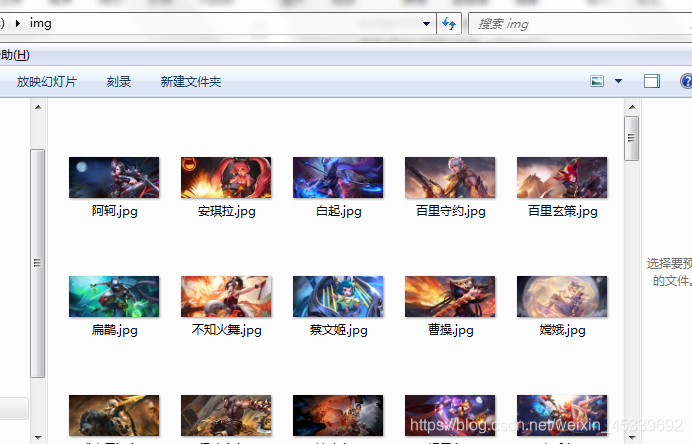
package bug;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.*;
import java.net.MalformedURLException;
import java.net.URL;
/**
- 爬虫:从王者荣耀官网上爬取图片
- jsoup jar包
- 爬虫必备技能:
-
web前端:学会HTML+CSS+JS -
Jsoup:Java爬虫工具包,HttpClient -
JavaSE 核心: 集合,IO流,线程 - 爬虫下载流程 1:找到视频网站打开;2:点击视频图片,按f12 获取网址
/
//GetImg 获取图片
public class GetImg爬虫 {
static String url =“https://pvp.qq.com/web201605/herolist.shtml”;
//下载后存放地址 写在上面容易查找
static String path = “d://img/”;
/*
*根据网络地址获取对应网络地址上的图片
* @param url
*/
//url链接
public static void getImgs(String url){
//加载对应网址上的html代码
try {
Document document = Jsoup.connect(url).userAgent(“Mozilla/4.0(Comparable;MSIE 9.0;widnows NT 6.1;Tridfent/5.0)”).get();
System.out.println(document);
//获取显示图片的ul吧标签;select查询
Elements selectUL = document.select("[class=herolist clearfix]");
//在ul中查找li标签
Elements selectLI = selectUL.select(“li”);
//遍历所有的li标签 获取详情页的地址及图像;
//forEach循环 从数组里面逐个获取每一个值 Element元素(标签);代表着html中显示内容标签
for (Element e:selectLI){
//找到英雄详情页的地址
String heroURL = e.select(“a”).attr(“href”);
//获取英雄名称 text()获取标签中的文本内容
String heroName = e.select(“a”).text();
//System.out.println(heroURL);
//System.out.println(heroName);
//拼接详情页的地址
String detailUr1 = "https://pvp.qq.com/web201605/"+heroURL;
//获取详情页的thml代码
Document doc = Jsoup.connect(detailUr1).userAgent("Mozilla/4.0(Comparable;MSIE 9.0;widnows NT 6.1;Tridfent/5.0)").get();
//找到显示背景的div标签
Elements div = doc.select("[class=zk-con1 zk-con]");
//获取显示的背景
String bg = div.attr("style");
System.out.println(bg);
//拆分字符串;拆出英雄图片的地址;substring(起始位置,终止位置)
//表示从[start,end]范围内拆分出子字符串
String heroImgUr1 = bg.substring(16,bg.length()-11);
System.out.println("开始下载"+heroImgUr1);
//下载后存放地址 写在上面容易查找
//String path = "d://";
//han 随意的起名
String han = path+heroName+".jpg";
//下载图片 download下载 因为我们下载的没有http 所以要加上
download("http:"+heroImgUr1,han);
}
} catch (IOException e) {
e.printStackTrace();
}
}
//下载指定路径下的图片
public static void download(String imgUrl,String path){
//构建URL链接
try {
URL url = new URL(imgUrl);
//IO流 相对于自来水管道 先把图片变成流(类似水),通过管道输出
DataInputStream dataInputStream = new DataInputStream(url.openStream());
//输出流
FileOutputStream outputStream = new FileOutputStream(path);
ByteArrayOutputStream output = new ByteArrayOutputStream();
byte[] buffer = new byte[1024];
int length = 0;
while ((length=dataInputStream.read(buffer))!=-1){
output.write(buffer,0,length);
}
outputStream.write(output.toByteArray());
outputStream.close();
dataInputStream.close();
output.close();
} catch (Exception e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
//获取系统当前开始下载图片的时间 毫秒数
long start = System.currentTimeMillis();
//爬取图片
getImgs(url);
//获取系统当前的时间毫秒数
long end = System.currentTimeMillis();
System.out.println("图片下载完毕,一共耗时:"+(end-start)/1000.0);
}
}