协同过滤算法在推荐算法领域应用十分广泛,主要有基于用户(UserCF)和基于物品(ItemCF)两种不同的类型:
- 基于用户的推荐算法:它是一种发现兴趣相似的用户的算法,假如你正在建设的是一个学习资源共享平台,你的用户群体有着大致稳定的专业与相对固定的阅读、学习爱好。当用户A(即登录用户)需要个性化推荐的时候,可以先找到和他兴趣相似的用户群体G,然后把G中所包含的且A中没有的东西进行预测评估,最后根据预测评估值对用户A进行推荐。
- 基于物品的推荐算法:当一个用户需要个性化推荐时,例如由于他之前购买花朵,所以会给他推荐花盆,因为其他用户很多都同时购买花朵和花盆。基于物品的推荐算法需要先计算物品之间的相似度,再根据物品的相似度和用户的历史行为给用户生成推荐列表。
本文笔者将介绍第一种算法,基于用户的协同过滤算法(UserCF)的实现,正如上文所说,我们将步骤分为三步:
1、找到与用户A兴趣相似的用户群体
- 首先,我们需要计算用户之间的相似度,本文我们采用余弦相似度来计算,公式为

(其中,N(u)表示用户u所购买的物品集合,|N(u)|则是其购买物品数目,N(v)同理,是用户v的对象)
计算分母部分:我们通过构造了一个相似度矩阵sparseMatrix,sparseMatrix[u][v]表示用户u与用户v购买的相同物品个数
- 然后我们将用户相似度降序排序,只取阈值内的用户最为相似用户群体
2、对G中所包含的且A没有听说过或没有见过的进行预测分析。
从相似用户群体中,得到相似用户购买的而我(登录用户)没有的物品,作为带预测的物品。因为与我兴趣相投的用户买了它们,所以可能我也会喜欢它们,这便是UserCF的原理。对这些待预测物品,我们需要进行预测分析,公式为:
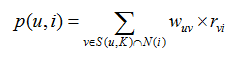
其中,u表示用户,i表示物品,(u,k)表示用户u的相似群体,p(u,i)则为用户u对物品i的好感度 ,r代表评分,本例中取1,在有评分的系统中它起到调整权重的作用,使得结果更加精准。
3、根据预测分析值对A进行推荐
根据用户对预测物品的好感度分析,进行排序后即可生成排序列表,本例比较精简,只推荐最合适1个的商品。
代码如下:
#include<cstdio>
#include<cstring>
#include<cmath>
#include<iostream>
#include<algorithm>
#include<set>
using namespace std;
const int maxn = 100;
struct similarty{
double weight;
int user;
}similartys[maxn];
void myprint(int userItem[][maxn],int n){
for(int i=0;i<n;i++){
cout<<"用户"<<userItem[i][0]<<"买了:";
int j=1;
while(userItem[i][j]!='\0'){
cout<<userItem[i][j]<<" ";
j++;
}
cout<<endl;
}
cout<<"-----------"<<endl;
}
int length(int *array){
int num=0;
int p=1;
while(array[p]!='\0'){
num++;
p++;
}
return num;
}
bool myfind(int userItem[][maxn],int user,int n){
for(int i=1;i<=length(userItem[user-1]);i++){
if(userItem[user-1][i]==n) return true;
}
return false;
}
bool cmp(similarty a,similarty b){
return a.weight>b.weight;
}
int main(){
int n=5; //用户人数
int userId=3; //推荐给userId
int num=2; //匹配用户个数
cout<<"用户人数:"<<n<<" "<<"登录id:"<<userId<<endl<<"具体情况:"<<endl;
//数据集
int userItem[n][maxn]={
{1,1,2,3,6,7},
{2,2,3},
{3,1,2,4,5,7},
{4,1,2,4,6},
{5,3,4}
};
myprint(userItem,n);
int sparseMatrix[n+1][n+1]; //记录两个用户之间的相似度的稀疏矩阵
memset(sparseMatrix,0,sizeof(sparseMatrix));
//计算用户之间的相似相似度矩阵
for(int i=0;i<n;i++){
for(int j=i+1;j<n;j++){
int p=1;
while(userItem[i][p]!='\0'){
int q=1;
while(userItem[j][q]!='\0'){
if(userItem[i][p] == userItem[j][q]){
sparseMatrix[userItem[j][0]][userItem[i][0]]++;
sparseMatrix[userItem[i][0]][userItem[j][0]]++;
break;
}
q++;
}
p++;
}
}
}
//计算用户之间的相似度 (余弦相似性)
int userIdLength = length(userItem[userId-1]);
int cnt=0;
for(int i=1;i<=n;i++){
if(i!=userId){
int iLength = length(userItem[i-1]);
similartys[cnt].weight = sparseMatrix[userId][i]/sqrt(userIdLength*iLength);
similartys[cnt].user = i;
cout<<"用户"<<userId<<"和"<<i<<"相似度:"<<similartys[cnt].weight<<endl;
cnt++;
}else{
similartys[cnt++].weight=-1;
}
}
sort(similartys,similartys+n,cmp);
cout<<"-----------"<<endl<<"用户匹配度最高的[2]位用户为:";
for(int i=0;i<2;i++){
cout<<similartys[i].user<<" ";
}
set<int> items; //记录考虑的商品:相似用户有的,而登录用户没有的
for(int i=0;i<2;i++){
for(int j=1;j<=length(userItem[similartys[i].user-1]);j++){
if(!myfind(userItem,userId,userItem[similartys[i].user-1][j])){
items.insert(userItem[similartys[i].user-1][j]);
}
}
}
cout<<endl<<"-----------"<<endl<<"考虑商品:"<<endl;
set<int>::iterator it = items.begin();
for(it;it!=items.end();it++){
cout<<*it<<" ";
}
cout<<endl<<"它们的匹配度为:"<<endl;
//计算商品匹配度
double maxpick = 0;
int recommendation;
for(it=items.begin();it!=items.end();it++){
double pick = 0;
for(int i=0;i<2;i++){
if(myfind(userItem,similartys[i].user,*it)){
pick+=similartys[i].weight;
}
}
if(pick>maxpick){
maxpick = pick;
recommendation = *it;
}
cout<<"商品"<<*it<<":"<<pick<<endl;
}
cout<<"-----------"<<endl<<"推荐商品:"<<recommendation<<endl;
}运行效果:

总结:CF算法原理其实比较简单,需要我们掌握好几步中的计算公式,即可实现基本功能。
