基于keras的图像分类CNN模型的搭建以及可视化
本文借助keras实现了热图像的分类模型的搭建,以及可视化的工作。本文主要由以下内容组成。
- Keras模型介绍
- CNN模型搭建
- 模型可视化
Keras模型介绍
1. 简介
Keras 是 Google 的一位工程师François Chollet 开发的一个框架,能够有效地利用TensorFlow进行开发。keras之所以流行的原因,我在之前的博客已经说明过了:轻量级和快速开发,并且日益成为一种标准框架。(对于深度学习方面是小白的同学,keras不要太友好啊。搭建模型的感觉就像在搭建积木。当然掌握必要的深度学习方面的数学知识是非常必要的。)
keras的核心数据结构就是模型。模型是用来组织网络层的方式。总共有两种模型。
1. Sequential 模型
2. Model 模型
我使用的是Sequential 模型(这种模型是一系列网络层按照顺序构成的栈,是单输入单输出的结构,层与层之间只有相邻的关系,如果你需要构建更复杂的模型则要用Model模型) 。
2. 安装
keras的安装非常简单,你可以安装anaconda,然后再安装keras。直接就是pip install keras
有一个需要注意的地方就是 ,安装好之后,可以选择依赖的后端,在 ~/keras/keras.json 下修改最后一行backend对应的值即可。就是修改下面的这段代码中tensorflow,可以改成theano,其实差别不大。我用的是TensorFlow。
{
"image_dim_ordering": "tf",
"epsilon": 1e-07,
"floatx": "float32",
"backend": "tensorflow"
}
使用TensorFlow和theano的区别主要就是变换读取数据尺寸的语句不一样。(之前的博客我也提到过。)

CNN模型搭建
我的模型是由一个人脸识别的案例改过来的,我改了挺长时间的,我也是有事没事,然后就把模型拿出来跑跑,发现哪儿不对劲,就改改,最后到今天,基本都跑通了。
我的模型代码由四个部分代码组成。代码已经上传到了我的GitHub上了,大家觉得我的这段代码有帮助的话,记得给我的GitHub点个星星, 蟹蟹大噶!
- read_img.py
- read_data.py
- dataSet.py
- train_model.py
- test_model.py
read_img.py
这个文件里面呢,主要就是读取文件数据(码的,说了等于没说嘛)。好了,开始讲正题。
先讲这个endwith的函数
def endwith(s,*endstring):
resultArray = map(s.endswith,endstring)
if True in resultArray:
return True
else:
return False这个函数实现的功能就是对图片文件名字符串的匹配,比如你需要找到文件夹中所有的jpg文件,那就靠他了。
read_data.py
这个文件主要用来读取文件夹下不同子文件夹的数据,然后将子文件夹的名字作为label
def read_file(path):
img_list = []
label_list = []
dir_counter = 0
#对路径下的所有子文件夹中的所有jpg文件进行读取并存入到一个list中
for child_dir in os.listdir(path):
child_path = os.path.join(path, child_dir)
for dir_image in os.listdir(child_path):
print(child_path)
if endwith(dir_image,'jpg'):
img = cv2.imread(os.path.join(child_path, dir_image))
img =cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
img_list.append(img)
label_list.append(dir_counter)
dir_counter += 1
# 返回的img_list转成了 np.array的格式
img_list = np.array(img_list)
return img_list,label_list,dir_counter核心的代码就是这个了,这部分代码最终返回的是图片list,label 的list,以及读取到的子文件夹数目。python强大的地方在于,可以非常直观地体现出你想表达的意思,比如
for child_dir in os.list_dir(path):直接将子文件夹路径加入到需要的路径中,非常方便。
dataSet.py
这个文件中有一处代码,把我卡了一段时间,主要是不太明白咋改,当时程序也一直报错,后来看看书,也明白了其中的一些问题。
核心代码就是下面这个:
class DataSet(object):
def __init__(self,path):
self.num_classes = None
self.X_train = None
self.X_test = None
self.Y_train = None
self.Y_test = None
self.extract_data(path)
#在这个类初始化的过程中读取path下的训练数据
def extract_data(self,path):
#根据指定路径读取出图片、标签和类别数
imgs,labels,counter = read_file(path)
print("输出标记")
print(labels)
#将数据集打乱随机分组
X_train,X_test,y_train,y_test = train_test_split(imgs,labels,test_size=0.4,random_state=random.randint(0, 100))
print("输出训练标记和训练集长度")
print(y_train)
print(len(X_train))
print(X_train[1])
print("测试长度和测试集标记")
print(len(X_test))
print(y_test)
print("输出和")
print(counter)
#重新格式化和标准化
# 本案例是基于thano的,如果基于tensorflow的backend需要进行修改
X_train = X_train.reshape(X_train.shape[0], 174, 212, 1)
X_test = X_test.reshape(X_test.shape[0], 174, 212,1)
X_train = X_train.astype('float32')/255
X_test = X_test.astype('float32')/255
print(X_train[1])
#将labels转成 binary class matrices
Y_train = np_utils.to_categorical(y_train, num_classes=counter)
Y_test = np_utils.to_categorical(y_test, num_classes=counter)
print(Y_train)
#将格式化后的数据赋值给类的属性上
self.X_train = X_train
self.X_test = X_test
self.Y_train = Y_train
self.Y_test = Y_test
self.num_classes = counter这一部分代码就是将读取进行的所有数据先打乱,然后按照一定比例划分成训练集和测试集,然后将数据再reshape为需要的大小。我看网上的说法,就是需要你将你自己的图片最好都重置成长宽一样或者长宽相近的图片。就是这部分代码:
#重新格式化和标准化
# 本案例是基于TensorFlow的,如果基于tensorflow的backend需要进行修改
X_train = X_train.reshape(X_train.shape[0], 174, 212, 1)
X_test = X_test.reshape(X_test.shape[0], 174, 212,1)当时没太明白shape[0]的作用,后来想明白了其实这个就是shape[0]就是划分得到集合的图片数目。
X_train,X_test,y_train,y_test = train_test_split(imgs,labels,test_size=0.4,random_state=random.randint(0, 100))这部分代码呢,是将数据集打乱,然后按照4:6的关系进行划分的语句。但是在后面多次跑程序的过程中发现,打乱数据,然后重新划分数据集会导致测试集的准确率不稳定。
train_model.py
这个文件是整个系统的最核心,需要讲的也很多。核心代码就是:
#建立一个基于CNN的识别模型
class Model(object):
FILE_PATH = "G:/desktop/myProject/model.h5" #模型进行存储和读取的地方
def __init__(self):
self.model = None
#读取实例化后的DataSet类作为进行训练的数据源
def read_trainData(self,dataset):
self.dataset = dataset
#建立一个CNN模型,一层卷积、一层池化、一层卷积、一层池化、抹平之后进行全链接、最后进行分类 其中flatten是将多维输入一维化的函数 dense是全连接层
def build_model(self):
self.model = Sequential()
self.model.add(
Convolution2D(
filters=32,
kernel_size=(5, 5),
padding='same',
dim_ordering='tf',
input_shape=self.dataset.X_train.shape[1:],
)
)
self.model.add( BatchNormalization())
self.model.add(Activation('relu'))
self.model.add(
MaxPooling2D(
pool_size=(2, 2),
strides=(2, 2),
padding='same'
)
)
self.model.add(Convolution2D(filters=64, kernel_size=(5, 5), padding='same'))
self.model.add(BatchNormalization())
self.model.add(Activation('relu'))
self.model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2), padding='same'))
self.model.add(Dropout(0.15))
self.model.add(Convolution2D(filters=64, kernel_size=(5, 5), padding='same'))
self.model.add(BatchNormalization())
self.model.add(Activation('relu'))
self.model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2), padding='same'))
self.model.add(Dropout(0.15))
self.model.add(Flatten())
self.model.add(Dense(512))
self.model.add(BatchNormalization())
self.model.add(Activation('relu'))
self.model.add(Dropout(0.5))
self.model.add(Dense(128))
self.model.add(BatchNormalization())
self.model.add(Activation('relu'))
self.model.add(Dropout(0.5))
self.model.add(Dense(self.dataset.num_classes))
self.model.add(BatchNormalization())
self.model.add(Activation('softmax'))
self.model.summary()
# plot_model(model,to_file='G:/desktop/myProject/model.png')
这个搭建起来的模型呢,是由一层卷积,一层池化,一层卷积,一层池化,抹平之后采用全连接,最后进行的分类,结构并不复杂。其中flatten函数是将多维的输入一维化的函数,然后dense函数是全连接层。
当时这个模型刚拿到手,训练准确率低得可怕,然后就想着提升准确率。主要用的方法就是四种:
1. 加入dropout,防止过拟合。
2. 改进优化函数,进而达到优化学习率的目的。
3. 还有一个很重要的就是加入batch_normalization。
4. batch_size和epoch的调节也是非常有影响的,但是这个调到哪个数,有点靠经验,我看网上有人说对于单个GPU,batch_size调到32比较合适。
具体地优化过程讲解,在我上一篇博客上也讲到了,大家可以看看。
test_model.py
这一部分呢,就是拿一些图片来检测模型的分类效果。在这一部分,也卡了一段时间,主要不知道如何来用。这个文件的核心代码,其实有两个部分,一个就是单个图片的分类,还有一个就是一堆图片的监测。我用的是一堆图片的分类。过程就是:建立一个test文件夹->在test文件夹下面建立各个类别的子文件夹->代码读取的是test文件夹
核心代码:
#读取文件夹下子文件夹中所有图片进行识别
def test_onBatch(path):
model= Model()
model.load()
index = 0
img_list, label_list, counter = read_file(path)
# img_list = img_list.reshape(img_list.shape[0], 174, 212, 1)
# print(img_list.shape[0:])
# img_list = img_list.astype('float32')/255
# Label_list = np_utils.to_categorical(label_list, num_classes=counter)
for img in img_list:
picType,prob = model.predict(img)
if picType != -1:
index += 1
name_list = read_name_list('G:/desktop/myProject/pictures/test')
print(name_list)
print (name_list[picType])
else:
print (" Don't know this ")
return index在进行测试的时候经常报一个很奇怪的错误,可能你是需要清理一下会话,代码前面加入
from keras import backend as K
K.clear_session()模型可视化
模型可视化,其实没啥好讲的,就是加了一小段代码而已,但是对整个系统的逼格提升是大有裨益的。
首先:
from keras.callbacks import TensorBoard
from keras.utils import plot_model然后在model.fit函数中添加回调命令callbacks=[TensorBoard(log_dir='G:/desktop/myProject/tmp/log')]就行。
具体的就是:
self.model.fit(self.dataset.X_train,self.dataset.Y_train,epochs=12,batch_size=20,callbacks=[TensorBoard(log_dir='G:/desktop/myProject/tmp/log')])用这一句话就可以记录下keras运行中一些参数的变化情况,但是具体,如何多引入一些观察变量,我还没有细究。在纯粹的tensorflow中可以通过设置graph,以及封装变量达到这个目的的。
然后就是如何使用tensorboard:
当模型跑完一遍之后,在你刚才指定的位置log子文件夹下面会生成一个文件,然后你在命令行中进入该文件所在的盘符,然后输入tensorboard --logdir=G:\desktop\myProject\tmp\log即可。
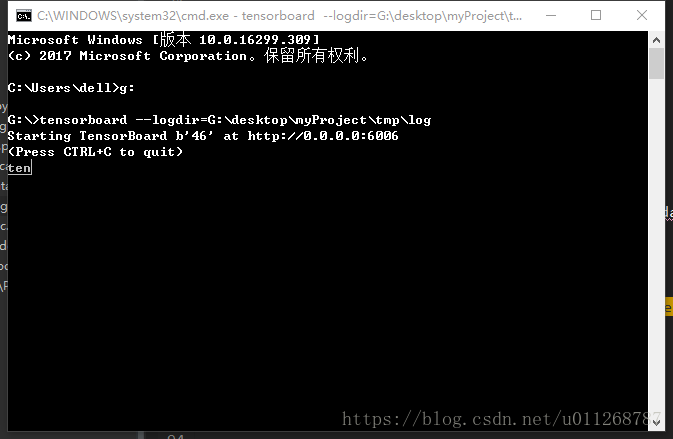
然后你将这个http://0.0.0.0:6006网址放到chrome浏览器,一般就会出结果(网络上一般都这么说),但是,按照这种方法我从来没有成功运行出来过,所以用的另外一个方法就是在网址栏上填入的是:localhost:6006就能出现tensorboard的界面了。
然后就出来了:
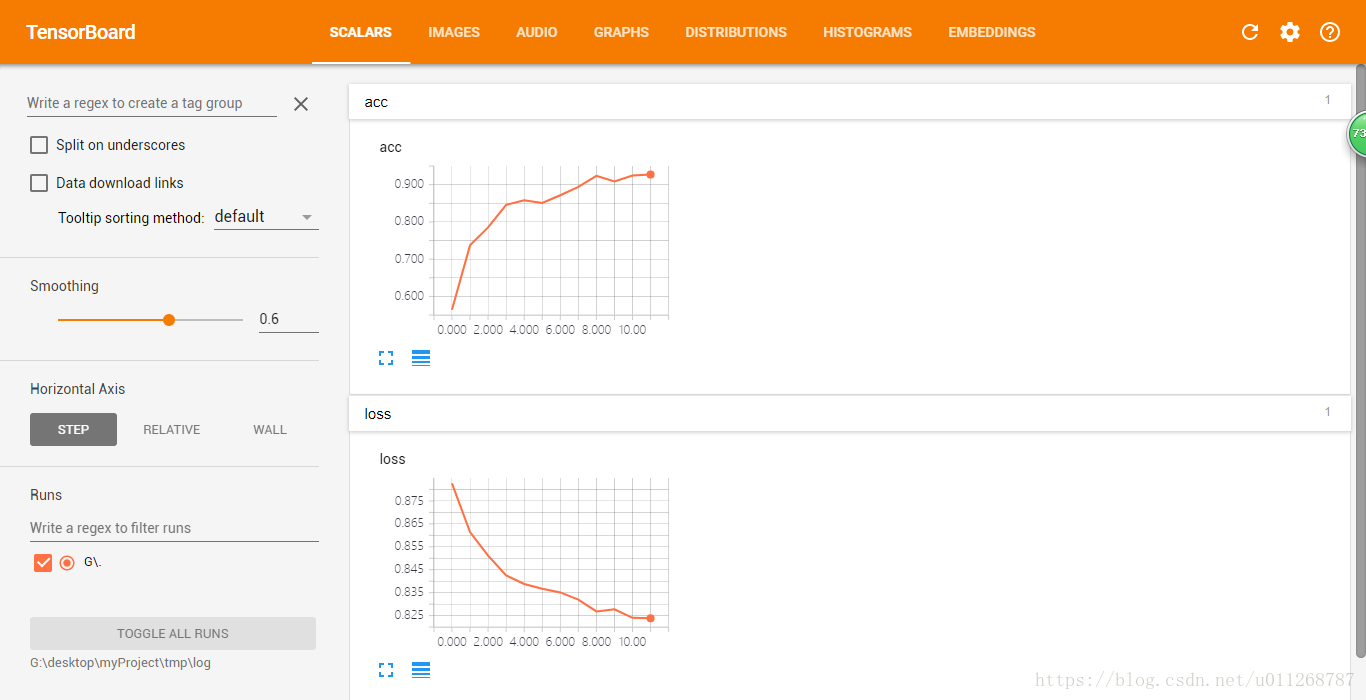
这一幅图中有两个变量一个是loss,一个是acc,acc很好理解就是准确率,但是这个loss我一直是整的模模糊糊,不大清楚,这不被某人一问,一下蒙了,答不上来,感觉很羞愧。于是找了一些些网上的资料,大体明白了。
目标函数,或称损失函数(就是这个loss),是编译一个模型必须的两个参数之一。
然后这个loss的得到,要从softmax开始讲,通过softmax得到的与真值误差可以经过公式计算出来。个人感觉这个博客写的很好:
卷积神经网络系列之softmax,softmax loss和cross entropy的讲解