1 简介
Spark是三大分布式计算系统开源项目之一(Hadoop,Spark,Storm)。
特点
-
运行速度快:
Spark使用先进的DAG(Directed Acyclic Graph,有向无环图)执行引擎,以支持循环数据流与内存计算,基于内存的执行速度可比Hadoop MapReduce快上百倍,基于磁盘的执行速度也能快十倍;
-
容易使用:
Spark支持使用Scala、Java、Python和R语言进行编程,简洁的API设计有助于用户轻松构建并行程序,并且可以通过Spark Shell进行交互式编程; -
通用性:
Spark提供了完整而强大的技术栈,包括SQL查询、流式计算、机器学习和图算法组件,这些组件可以无缝整合在同一个应用中,足以应对复杂的计算; -
运行模式多样:
Spark可运行于独立的集群模式中,或者运行于Hadoop中,也可运行于Amazon EC2等云环境中,并且可以访问HDFS、Cassandra、HBase、Hive等多种数据源。
与Hadoop相比,Spark最大的特点就是将计算数据、中间结果都存储在内存中,大大减少了IO开销,因而,Spark更适合于迭代运算比较多的数据挖掘与机器学习运算。
2.安装
Spark可以独立安装使用,也可以和Hadoop一起安装使用。和Hadoop一起安装使用,可以让Spark使用HDFS存取数据。
当安装好Spark以后,里面就自带了scala环境,不需要额外安装scala。
参考链接 anaconda 下spark 安装;
暂时还是不懂这种安装方式和 使用 pip install pyspark 有什么区别。
3. 功能
3.1 基本概念
- RDD:是弹性分布式数据集(Resilient Distributed Dataset)的简称,是分布式内存的一个抽象概念,提供了一种高度受限的共享内存模型;
- DAG:是Directed Acyclic Graph(有向无环图)的简称,反映RDD之间的依赖关系;
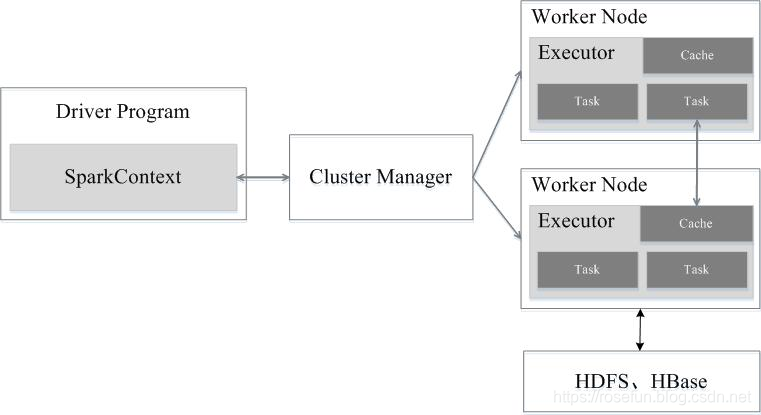
- Executor:是运行在工作节点(Worker Node)上的一个进程,负责运行任务,并为应用程序存储数据;
- 应用:用户编写的Spark应用程序;
- 任务:运行在Executor上的工作单元;
- 作业:一个作业包含多个RDD及作用于相应RDD上的各种操作;
- 阶段:是作业的基本调度单位,一个作业会分为多组任务,每组任务被称为“阶段”,或者也被称为“任务集”。
3.2 RDD
RDD,Resilient distributed datasets,分布式收集数据结构,是Spark 计算引擎。
RDD只需将具体的应用逻辑表达为一系列转换处理,不同RDD之间的转换操作形成依赖关系,可以实现管道化,从而避免了中间结果的存储,大大降低了数据复制、磁盘IO和序列化开销。
每个RDD可以分成多个分区,每个分区就是一个数据集片段,并且一个RDD的不同分区可以被保存到集群中不同的节点上。
RDD的操作及数据运算,分为“行动”(Action)和“转换”(Transformation)两种类型,转换操作(比如map、filter、groupBy、join等)接受RDD并返回RDD,而行动操作(比如count、collect等)接受RDD但是返回非RDD(即输出一个值或结果)。
步骤:
- RDD读入外部数据源(或者内存中的集合)进行创建;
- RDD经过一系列的“转换”操作,每一次都会产生不同的RDD,供给下一个“转换”使用;
- 最后一个RDD经“行动”操作进行处理,并输出到外部数据源(或者变成Scala集合或标量)。
需要说明的是,RDD采用了惰性调用,真正的计算发生在RDD的“行动”操作,对于“行动”之前的所有“转换”操作,Spark只是记录下“转换”操作应用的一些基础数据集以及RDD生成的轨迹,即相互之间的依赖关系,而不会触发真正的计算。
特性
- 高容错性。
RDD只读不能修改数值,如需修改数据则通过转换形成子RDD。 - 中间结果持久化到内存。
减少通讯开销。 - 存放数据可以是Java对象。
分类
- 窄连接
包括map、filter、union。 - 宽连接
包含groupByKey、sortByKey等。
如果父RDD的一个分区只被一个子RDD的一个分区所使用就是窄依赖,否则就是宽依赖。
1.1 MapReduce 算法
- 矩阵向量相乘;
- 指数迭代;
- 随机梯度方法;
- 随机SVD;
- QR;
缺点:
- 数据共享的局限性;
- 不同步骤的产物在分布式文件系统;
- 复制和磁盘内存存储导致慢;

3.Spark函数


4.Spark示例


参考:
