目录
urllib库
urlopen函数
urllib库中的所有请求都被集中在,urllib.request模块
from urllib import request
resp=request.urlopen("http://www.baidu.com")#
print(resp.read())
print(resp.readline())
print(resp.readlines())#以列表的形式返回,每一行都是列表的一项
print(resp.getcode())#返回状态码,此处为200,表示正常
urlretrieve函数
是为了爬取网页,并存储,比如第一个链接是一个图片的链接的话,就可以把图片存起。
request.urlretrieve("http://www.baidu.com","baidu.com")
urlencode函数

params={"name":"张三","age":"18"}
result=parse.urlencode(params)
print(result)
结果:
name=%E5%BC%A0%E4%B8%89&age=18url="http://www.baidu.com/s"
params={"wd":"刘德华"}
result=parse.urlencode(params)
url=url+"?"+result
print(url)
requ=request.urlopen(url)
print(requ.read())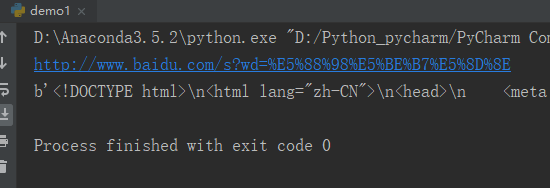
parse.qs函数的用法
解码

urlparse和urlsplit函数
对url的各个部分进行分割
两者其实差不多,但是urlsplit没有params属性,
url="http://www.baidu.com/s?wd=python&username=abc#1"
result=parse.urlparse(url)
print(result)
结果:
ParseResult(scheme='http', netloc='www.baidu.com', path='/s', params='', query='wd=python&username=abc', fragment='1')
可以通过
print(result.scheme)
print(result.netloc)
print(result.query)来取各部分
request.Request类:
可以在请求之前加上请求头,来抵抗反爬虫。
url="https://www.lagou.com/"
headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36"}
req=request.Request(url,headers=headers)
resp=request.urlopen(req)
#resp=request.urlopen(url)
print(resp.read())如果不加请求头,会识别出来为爬虫机制,加上了可以模拟浏览器的行为。
