文章目录
在docker中拉取Cassandra镜像
在终端中输入如下命令:(前提是已经安装好docker)
docker pull cassandra
创建docker network
Docker有以下网络类型:
bridge:多由于独立container之间的通信
host: 直接使用宿主机的网络,端口也使用宿主机的
overlay:当有多个docker主机时,跨主机的container通信
macvlan:每个container都有一个虚拟的MAC地址
none: 禁用网络
默认网络:Docker在默认情况下,分别会建立一个bridge、一个host和一个none的网络:
docker network ls
NETWORK ID NAME DRIVER SCOPE
cdc35147c3ae bridge bridge local
0418807a829c host host local
a4b53107ae28 none null local
创建命令
docker network create [OPTIONS] NETWORK
注意:docker client和daemon API都必须至少为1.21才能使用此命令。使用docker version命令检查client和daemon API版本。
options参数
| Name, shorthand | Description |
|---|---|
--attachable |
Enable manual container attachment |
--aux-address |
Auxiliary IPv4 or IPv6 addresses used by Network driver |
--config-from |
The network from which copying the configuration |
--config-only |
Create a configuration only network |
--driver , -d |
Driver to manage the Network |
--gateway |
IPv4 or IPv6 Gateway for the master subnet |
不加options参数时网络默认采用桥接网络
创建一个Cassandra实例
docker run --name some-cassandra --network some-network -d cassandra:tag
some-cassandra换成你想命名的容器名,some-network换成刚才创建的network,tag注明Cassandra的版本号,默认安装换成latest即可
比如:
docker run --name ctest --network test -d cassandra:latest
连接cqlsh
docker run -it --network some-network --rm cassandra cqlsh some-cassandra
docker run -it --network test --rm cassandra cqlsh ctest
Connected to Test Cluster at ctest:9042.
[cqlsh 5.0.1 | Cassandra 3.11.4 | CQL spec 3.4.4 | Native protocol v4]
Use HELP for help.
CQL语言
Cassandra查询语言(cql)是一种声明性语言,允许用户使用类似于SQL的语言查询Cassandra。cql是在Cassandra 0.8版中引入的,现在是从Cassandra中检索数据的首选方法。在引入CQL之前,节省一个基于RPC的API是从Cassandra检索数据的首选方法。cql的一个主要好处是它与SQL的相似性,从而有助于降低Cassandra的学习难度。我们可以把CQL看作是一个简单的API,而不是cassandra的内部存储结构。
CQL基础
让我们先了解一些基本的cql构造,然后再进入一个实践示例。
keyspace
keyspace类似于RDBMS数据库。它是应用程序数据的容器。与数据库一样,keyspace必须具有名称和一组关联的属性。定义键空间时必须设置的两个重要属性是复制因子和复制策略。
column family/table
列族/表类似于RDBMS表。keyspace由许多列族/表组成。
Primary Key / Tables
主键使用户能够唯一标识数据的“内部行”。主键由两部分组成。行/分区键和群集键。行/分区键确定存储数据的节点,而群集键确定特定行中数据的排序顺序。
首先要注意的是,cql严重限制了可应用于查询的谓词。这本质上是为了防止错误的查询,并迫使用户仔细考虑他们的数据模型。以下是SQL中经常使用但在cql中不可用的内容列表:
- 没有任意的where子句
–在cql中,谓词只能包含主键中指定的列。 - 无连接构造
–无法跨列族连接数据。不鼓励在两个列族之间连接数据,因此在cql中没有连接构造。 - 无分组依据
–不能对相同的数据分组。 - 没有任意的ORDER BY子句
–ORDER BY只能应用于集群列。
学习cql的最佳方法是编写cql查询。cql是与Cassandra交互的一种非常简单的方法,但是如果不理解底层的内部工作,很容易被误用。了解底层结构是掌握CQL的关键。
CQL实例
cqlsh> CREATE KEYSPACE animalkeyspace
WITH REPLICATION = { 'class' : 'SimpleStrategy' ,
'replication_factor' : 1 };
特别注意命令的WITH REPLICATION部分。这说明animalkeyspace应该使用一个简单的复制策略,并且对于插入到animalkeyspace中的所有数据,只具有一个副本。这对于演示来说很好,但对于任何类型的测试或生产环境来说都不是一个实际的选择。
接下来,我们创建一个column family。为了创建一个column family,您需要在“USE command”的帮助下导航到animalkeyspace。USE command使客户机能够连接到特定的键空间,即,所有进一步的cql命令将在所选键空间的上下文中执行。在cqlsh提示下执行以下命令,将当前客户机连接到animalkeyspace。
cqlsh> use animalkeyspace;
cqlsh:animalkeyspace>
请注意,cqlsh提示符将从“cqlsh>”更改为“cqlsh:animalkeyspace>”,这将在视觉上提醒您当前连接的keyspace。
现在让我们创建一个列族/表来存放与猴子相关的数据。要定义表,必须使用CREATE TABLE命令。请特别注意主键。主键由两部分组成。即分区/行键和集群键。主键的第一列是分区键。其余列用于确定群集键。复合分区键(由多列组成的分区键)可以通过在集群列之前使用一组额外的括号来定义。行键有助于在集群中分布数据,而集群键决定存储在行中的数据的顺序。因此,在设计表时,将行键看作是一种工具,用于在集群中均匀分布数据,而集群键有助于确定行中数据的顺序。查询模式将极大地影响集群键,因为它用于对存储在行中的数据进行排序。注意,集群键是可选的。
让我们通过在cqlsh提示符中执行以下命令来创建monkey表。
cqlsh:animalkeyspace> CREATE TABLE Monkey (
identifier uuid, species text, nickname text, population int, PRIMARY KEY ((identifier), species));
在上表中,我们选择identifier作为分区键,选择species作为集群键。
让我们使用下面的insert语句在上面的列族中插入一行:
cqlsh:animalkeyspace> INSERT INTO monkey (identifier, species, nickname, population)
VALUES ( 5132b130-ae79-11e4-ab27-0800200c9a66,
'Capuchin monkey', 'cute', 100000);
现在,让我们检查一下在Monkey表中创建和插入一行之后发生了什么。
cqlsh:animalkeyspace> Select * from monkey;
identifier | species | nickname | population
--------------------------------------+-----------------+----------+------------
5132b130-ae79-11e4-ab27-0800200c9a66 | Capuchin monkey | cute | 100000
(1 rows)
如果将插入到Monkey表中的数据转换为JSON,会得到以下结果:
[
{
"key": "5132b130ae7911e4ab270800200c9a66", // 行/分区键
"columns": [
[
"Capuchin monkey:", // 集群键。注意,集群键没有任何关联的数据。键和数据相同。
"",
1423586894518000 // 创建此内部列时记录的时间戳。
],
[
"Capuchin monkey:nickname", // nickname internal列的头。注意,对于每个额外的内部列,集群键总是有前缀。
"cute", // 实际数据
1423586894518000
],
[
"Capuchin monkey:population", // population内部列的头
"100000", // 实际数据
1423586894518000
]
]
}
]
插入到Monkey表中的数据可以显示为下面的映射
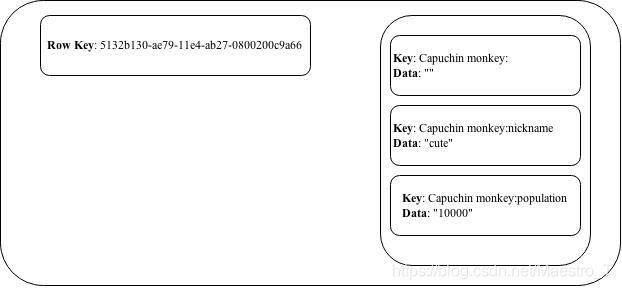
注意分区键5132B130AE7911E4AB270800200C9A66是行键和外部映射的键。Capuchin monkey:是我们的集群键,也是内部排序地图中的第一个条目。排序映射的第一个条目没有任何数据作为键,数据相同。随后的映射条目通过在列名称后面加上集群键来创建它们的键。Capuchin monkey:nickname是集群键+列标题nickname的结果。数据部分包含列的实际数据。
下图直观地描述了cql行、结果sstable和排序映射的逻辑映射之间的链接。
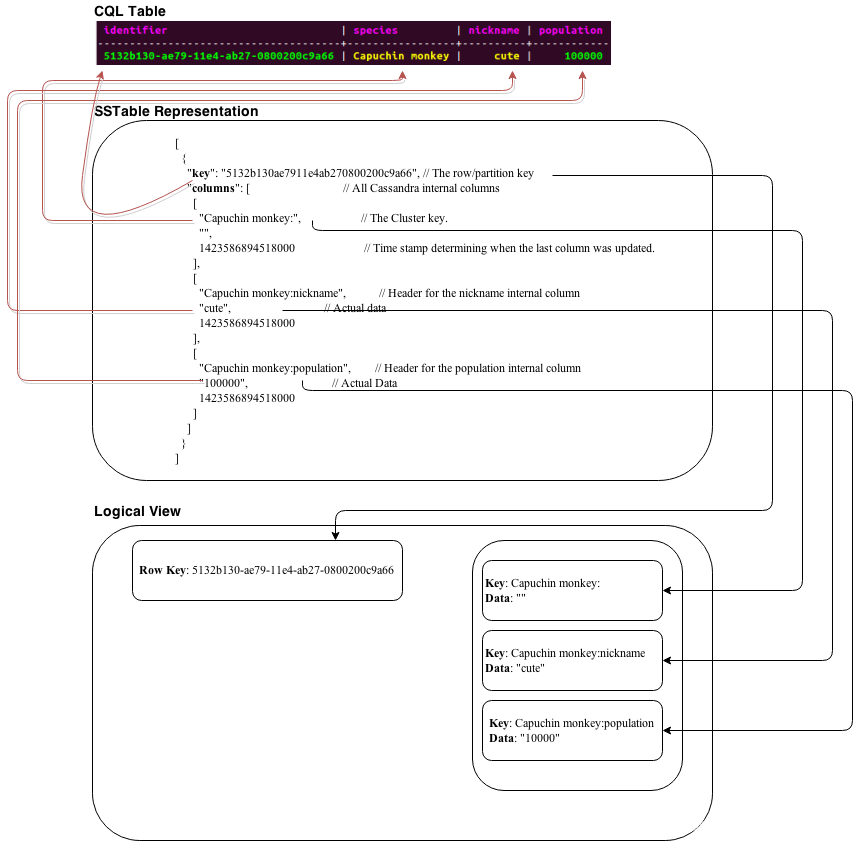 现在让我们再插入两行cql。插入的第一行将具有相同的分区键,但将更改群集键。插入的第二行将有一个新的分区键和群集键。
现在让我们再插入两行cql。插入的第一行将具有相同的分区键,但将更改群集键。插入的第二行将有一个新的分区键和群集键。
cqlsh:animalkeyspace> INSERT INTO monkey (identifier, species, nickname, population)
VALUES ( 5132b130-ae79-11e4-ab27-0800200c9a66, 'Small Capuchin monkey', 'very cute', 100);
INSERT INTO monkey (identifier, species, nickname, population)
VALUES ( 7132b130-ae79-11e4-ab27-0800200c9a66, 'Rhesus Monkey', 'Handsome', 100000);
进行查询:
cqlsh:animalkeyspace> Select * from monkey;
identifier | species | nickname | population
--------------------------------------+-----------------------+-----------+------------
5132b130-ae79-11e4-ab27-0800200c9a66 | Capuchin monkey | cute | 100000
5132b130-ae79-11e4-ab27-0800200c9a66 | Small Capuchin monkey | very cute | 100
7132b130-ae79-11e4-ab27-0800200c9a66 | Rhesus Monkey | Handsome | 100000
(3 rows)
现在在转换成json会得到以下结果:
[
{
"key": "5132b130ae7911e4ab270800200c9a66",
"columns": [
[
"Capuchin monkey:",
"",
1424557973603000
],
[
"Capuchin monkey:nickname",
"cute",
1424557973603000
],
[
"Capuchin monkey:population",
"100000",
1424557973603000
],
[
"Small Capuchin monkey:",
"",
1424558013115000
],
[
"Small Capuchin monkey:nickname",
"very cute",
1424558013115000
],
[
"Small Capuchin monkey:population",
"100",
1424558013115000
]
]
},
{
"key": "7132b130ae7911e4ab270800200c9a66",
"columns": [
[
"Rhesus Monkey:",
"",
1424558014339000
],
[
"Rhesus Monkey:nickname",
"Handsome",
1424558014339000
],
[
"Rhesus Monkey:population",
"100000",
1424558014339000
]
]
}
]
此时插入到Monkey表中的数据可以显示为下面的映射

-CQL实例来源,点击 这里查看原文.
