1). 扑克牌手动演练k均值聚类过程:>30张牌,3类
2). *自主编写K-means算法 ,以鸢尾花花瓣长度数据做聚类,并用散点图显示。(加分题)
3). 用sklearn.cluster.KMeans,鸢尾花花瓣长度数据做聚类,并用散点图显示.
4). 鸢尾花完整数据做聚类并用散点图显示.
5).想想k均值算法中以用来做什么?
答:
1)扑克牌手动演练k均值聚类过程:>30张牌,3类
随机选取三个中心(8,3,2);

经过第一步后,变为(9,4,2);

经过第二步后,变为(10,6,2),一直不变,聚类中心为(10,6,2);

2)自主编写K-means算法 ,以鸢尾花花瓣长度数据做聚类,并用散点图显示。
# -*- coding:utf-8 -*- from sklearn.datasets import load_iris import pandas as pd import numpy as np import matplotlib.pyplot as plt #选取数据空间中的K个对象作为初始中心,每个对象代表一个聚类中心; def initcenter(data, k): m = data.shape[1] # 样本的属性个数 center = [] temp = 0 temptemp = 0 for i in range(k): temp = np.random.randint(0, len(data)) if temp != temptemp: center.append(data[temp, :]) temptemp = temp else: print("重复啦") i -= 1 center = np.array(center) return center def nearest(center, x): distance = [] for j in range(k): distance.append(sum((x - center[j,:]) ** 2)) # print(np.argmin(distance)) y = np.argmin(distance) return y def xclassify(data, y, center): for index,x in enumerate(data): y[index] = nearest(center, x) return y def kcmean(data, y, center, k): m = data.shape[1] center_new = np.zeros([k, m]) for i in range(k): index = y == i center_new[i, :] = np.mean(data[index, :], axis=0) if np.all(center_new == center): return center,False else: center = center_new return center,True #初始化;调用生成center if __name__ == '__main__': data = load_iris().data center = initcenter(data,3) k = int(input("请输入质心个数:")) y = np.zeros(len(data)) flag = True while flag: y = xclassify(data, y, center) center, flag = kcmean(data, y, center, k) print("聚类结果:",y) for x in range(len(data)): plt.scatter(data[x][0], data[x][1], s=30, c='b', marker='.') for k in range(len(center)): plt.scatter(center[k][0], center[k][1], s=60, c='r', marker='D') plt.show()
运行结果:

可视化结果:

3)用sklearn.cluster.KMeans,鸢尾花花瓣长度数据做聚类,并用散点图显示.
# -*- coding:utf-8 -*- from sklearn.datasets import load_iris from sklearn.cluster import KMeans import matplotlib.pyplot as plt data_iris = load_iris().data speal_width = data_iris[:,2] X = speal_width.reshape(-1,1) X.shape kmeans_model = KMeans(n_clusters=3) kmeans_model.fit(X) kmeans_model.predict([[3.5]]) y_predict = kmeans_model.predict(X) kmeans_model.cluster_centers_ kmeans_model.labels_ plt.scatter(X[:,0],X[:,0],c=y_predict,s=50,cmap="rainbow") plt.show()
可视化结果:
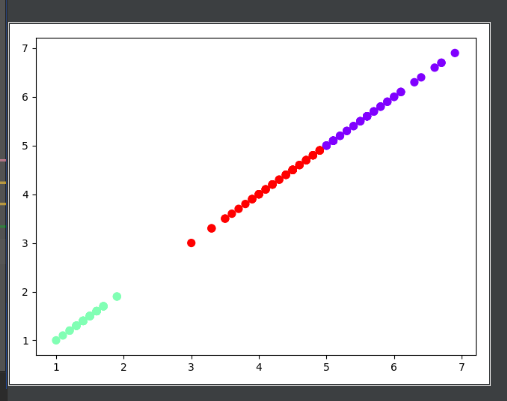
4)鸢尾花完整数据做聚类并用散点图显示.
# -*- coding:utf-8 -*- from sklearn.datasets import load_iris from sklearn.cluster import KMeans import matplotlib.pyplot as plt data_iris = load_iris().data kmeans_model = KMeans(n_clusters=3) kmeans_model.fit(data_iris) y_predict1 = kmeans_model.predict(data_iris) kmeans_model.cluster_centers_ kmeans_model.labels_ plt.scatter(data_iris[:,2],data_iris[:,3],c=y_predict1,s=50,cmap="rainbow") plt.show()
可视化结果:
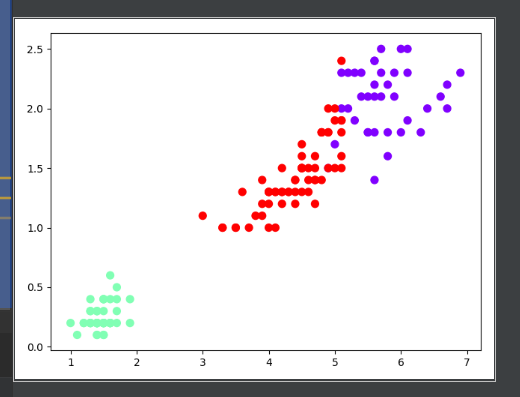
5)想想k均值算法中以用来做什么?
1.文档分类器
根据标签、主题和文档内容将文档分为多个不同的类别。这是一个非常标准且经典的K-means算法分类问题。首先,需要对文档进行初始化处理,将每个文档都用矢量来表示,并使用术语频率来识别常用术语进行文档分类,这一步很有必要。然后对文档向量进行聚类,识别文档组中的相似性。
2.客户分类
聚类能过帮助营销人员改善他们的客户群(在其目标区域内工作),并根据客户的购买历史、兴趣或活动监控来对客户类别做进一步细分。
3.球队状态分析
分析球员的状态一直都是体育界的一个关键要素。随着竞争越来愈激烈,机器学习在这个领域也扮演着至关重要的角色。如果你想创建一个优秀的队伍并且喜欢根据球员状态来识别类似的球员,那么K-means算法是一个很好的选择。
4.乘车数据分析
面向大众公开的Uber乘车信息的数据集,为我们提供了大量关于交通、运输时间、高峰乘车地点等有价值的数据集。分析这些数据不仅对Uber大有好处,而且有助于我们对城市的交通模式进行深入的了解,来帮助我们做城市未来规划。
5.网络分析犯罪分子
网络分析是从个人和团体中收集数据来识别二者之间的重要关系的过程。网络分析源自于犯罪档案,该档案提供了调查部门的信息,以对犯罪现场的罪犯进行分类。
6.呼叫记录详细分析
通话详细记录(CDR)是电信公司在对用户的通话、短信和网络活动信息的收集。将通话详细记录与客户个人资料结合在一起,这能够帮助电信公司对客户需求做更多的预测。