在大学,交作业基本都是电子档了,每个人都需要将作业发给学习委员,学习委员统计后才能发给老师。之中就存在许多问题。如
- 有同学少交了,清查花费时间
- 命名不规范
如何使用Python帮助学习委员解决这两个问题呢
构建名单
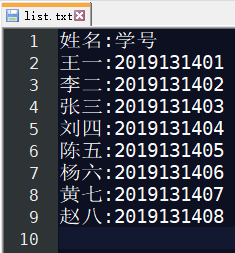
- 首先清查作业的问题。这里我们肯定需要全班同学的名单,我们做成一个txt,就是酱紫的
- 没有2,咔咔保存就是了
编写代码
- 我们主要的思路就是将同学的作业进行分词,这个名单即是词库,也是参照。这样我们得到所交作业中的所有同学的名字,一一对比,就知道哪些没交了。同一文件名就简单了,就不用说了。那首先我们需要将同学们的姓名加入词库。这里我们用的jieba,这是一个优秀的分词包,没有的话可以在cmd(win+r,输入cmd)中输入
pip install jieba安装
import os
import time
import jieba
filelist = {} # 文件名
dict_temp = {} # 字典
is_ok = {} # 交作业判断符
# 打开名单读取信息保存到字典和词库
def load_dict_from_file():
global dict_temp, is_ok
dict_temp.clear()
is_ok.clear()
with open('list.txt', 'r', encoding = 'utf-8') as dict_file: # 打开文件
for line in dict_file.readlines():
(key, value) = line.strip().split(':')
dict_temp[key] = value # 添加班级信息字典
is_ok[key] = 0 # 交作业判断字典
jieba.add_word(key) # 保存名字到jieba词库
- 现在我们需要遍历一个文件夹中的所有作业了
#找文件名
def get_file_list():
global filelist
rootdir = 'file'
list = os.listdir(rootdir) # 列出文件夹下所有的目录与文件
for i in range(0, len(list)):
paths = os.path.join(rootdir, list[i])
(key, value) = os.path.basename(paths).split('.') # 每个文件的名字做一个列表元素
filelist[key] = value
- 这两个关键的操作完成了就可以开始整个操作了,这里为什么要删除“\ufeff姓名”而不是“姓名”,这是编码问题。理解utf-8和utf-8-sig的同学可以在打开文件的时候选择utf-8-sig的编码,就不会有\ufeff了
work_name = input("请输入当前作业的名称:")
load_dict_from_file()
get_file_list()
m = len(filelist) # 打印出目录下所有的文件
del dict_temp['\ufeff姓名']
for n in filelist:
words = jieba.lcut(n)
# print (word) # 分词测试
for key in dict_temp:
for word in words:
if word == key:
oldname = './file/' + n + '.' + filelist[n]
newname = './file/' + dict_temp[key] + '-' + key + '-' + work_name + '.' + filelist[n]
# print (oldname) # 测试语句
# print (newname) # 测试语句
os.rename(oldname, newname)
is_ok[key] = 1
break
print ('共有{}人已交作业'.format(m))
# 分辨没有交作业的
# print (is_ok.keys())
del is_ok['\ufeff姓名']
for key in is_ok:
if is_ok[key] == 0:
print ("{}没交作业".format(key))
print ("作业已处理完成")
time.sleep(10)
- perfect!现在来试一试。我们新建了个收作业的文件夹,现在作业交上来了,本次我们的作业是骑猪跑一圈的第一次实验,所以大家的规范命名应该是
<学号>-<姓名>-骑猪跑一圈第一次实验,这些命名简直醉了
- 命名错了就算了,8个人的作业都不交齐,造反了?算了算了,生气也要保持微笑。现在试试我们的
小助手
看看我们的文件夹呢
OK,准备去催作业了差点忘了,我不是学习委员O_O



