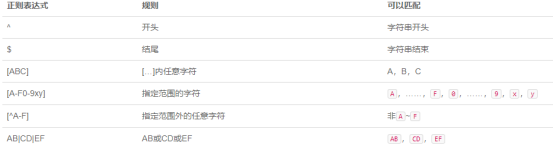
正则表达式定义了字符串的模式。
正则表达式可以用来搜索、编辑或处理文本。
正则表达式并不仅限于某一种语言,但是在每种语言中有细微的差别。
对于正则表达式abc来说,它只能精确地匹配字符串"abc",不能匹配"ab",“Abc”,“abcd"等其他任何字符串。
如果正则表达式有特殊字符,那就需要用\转义。例如,正则表达式a&c,其中&是用来匹配特殊字符&的,它能精确匹配字符串"a&c”,但不能匹配"ac"、“a-c”、“a&&c"等。
要注意正则表达式在Java代码中也是一个字符串,所以,对于正则表达式a&c来说,对应的Java字符串是"a\&c”,因为\也是Java字符串的转义字符,两个\实际上表示的是一个\:
public class Main {
public static void main(String[] args) {
String re1 = "abc";
System.out.println("abc".matches(re1));
System.out.println("Abc".matches(re1));
System.out.println("abcd".matches(re1));
String re2 = "a\\&c"; // 对应的正则是a\&c
System.out.println("a&c".matches(re2));
System.out.println("a-c".matches(re2));
System.out.println("a&&c".matches(re2));
}
}
如果想匹配非ASCII字符,例如中文,那就用\u####的十六进制表示,例如:a\u548cc匹配字符串"a和c",中文字符和的Unicode编码是548c。
匹配任意字符
精确匹配实际上用处不大,因为直接用String.equals()就可以做到。大多数情况下,想要的匹配规则更多的是模糊匹配。可以用.匹配一个任意字符。
例如,正则表达式a.c中间的.可以匹配一个任意字符,例如,下面的字符串都可以被匹配:
- “abc”,因为.可以匹配字符b;
- “a&c”,因为.可以匹配字符&;
- “acc”,因为.可以匹配字符c。
但它不能匹配"ac"、“a&&c”,因为.匹配一个字符且仅限一个字符。
匹配数字
用.可以匹配任意字符,这个口子开得有点大。如果只想匹配0~9这样的数字,可以用\d匹配。例如,正则表达式00\d可以匹配:
- “007”,因为\d可以匹配字符7;
- “008”,因为\d可以匹配字符8。
它不能匹配"00A",“0077”,因为\d仅限单个数字字符。
匹配常用字符
用\w可以匹配一个字母、数字或下划线,w的意思是word。例如,java\w可以匹配:
- “javac”,因为\w可以匹配英文字符c;
- “java9”,因为\w可以匹配数字字符9;
- “java_”,因为\w可以匹配下划线_。
它不能匹配"java#","java ",因为\w不能匹配#、空格等字符。
匹配空格字符
用\s可以匹配一个空格字符,注意空格字符不但包括空格,还包括tab字符(在Java中用\t表示)。例如,a\sc可以匹配:
- “a c”,因为\s可以匹配空格字符;
- “a c”,因为\s可以匹配tab字符\t。
它不能匹配"ac","abc"等。
匹配非数字
用\d可以匹配一个数字,而\D则匹配一个非数字。例如,00\D可以匹配:
- “00A”,因为\D可以匹配非数字字符A;
- “00#”,因为\D可以匹配非数字字符#。
00\d可以匹配的字符串"007","008"等,00\D是不能匹配的。
类似的,\W可以匹配\w不能匹配的字符,\S可以匹配\s不能匹配的字符,这几个正好是反着来的。
public class Main {
public static void main(String[] args) {
String re1 = "java\\d"; // 对应的正则是java\d
System.out.println("java9".matches(re1));
System.out.println("java10".matches(re1));
System.out.println("javac".matches(re1));
String re2 = "java\\D";
System.out.println("javax".matches(re2));
System.out.println("java#".matches(re2));
System.out.println("java5".matches(re2));
}
}
重复匹配
用\d可以匹配一个数字,例如,A\d可以匹配"A0",“A1”,如果要匹配多个数字,比如"A380",怎么办?
修饰符可以匹配任意个字符,包括0个字符。用A\d可以匹配:
- A:因为\d*可以匹配0个数字;
- A0:因为\d*可以匹配1个数字0;
- A380:因为\d*可以匹配多个数字380。
修饰符+可以匹配至少一个字符。用A\d+可以匹配: - A0:因为\d+可以匹配1个数字0;
- A380:因为\d+可以匹配多个数字380。
但它无法匹配"A",因为修饰符+要求至少一个字符。
修饰符?可以匹配0个或一个字符。用A\d?可以匹配: - A:因为\d?可以匹配0个数字;
- A0:因为\d+可以匹配1个数字0。
但它无法匹配"A33",因为修饰符?超过1个字符就不能匹配了。
如果想精确指定n个字符怎么办?用修饰符{n}就可以。A\d{3}可以精确匹配: - A380:因为\d{3}可以匹配3个数字380。
如果想指定匹配n~m个字符怎么办?用修饰符{n,m}就可以。A\d{3,5}可以精确匹配: - A380:因为\d{3,5}可以匹配3个数字380;
- A3800:因为\d{3,5}可以匹配4个数字3800;
- A38000:因为\d{3,5}可以匹配5个数字38000。
如果没有上限,那么修饰符{n,}就可以匹配至少n个字符。
匹配开头和结尾
用正则表达式进行多行匹配时,用^表示开头,KaTeX parse error: Undefined control sequence: \d at position 11: 表示结尾。例如,^A\̲d̲{3},可以匹配"A001"、“A380”。
匹配指定范围
如果规定一个7~8位数字的电话号码不能以0开头,应该怎么写匹配规则呢?\d{7,8}是不行的,因为第一个\d可以匹配到0。
使用[…]可以匹配范围内的字符,例如,[123456789]可以匹配1~9,这样就可以写出上述电话号码的规则:[123456789]\d{6,7}。
把所有字符全列出来太麻烦,[…]还有一种写法,直接写[1-9]就可以。
要匹配大小写不限的十六进制数,比如1A2b3c,我们可以这样写:[0-9a-fA-F],它表示一共可以匹配以下任意范围的字符:
- 0-9:字符0~9;
- a-f:字符a~f;
- A-F:字符A~F。
如果要匹配6位十六进制数,前面讲过的{n}仍然可以继续配合使用:[0-9a-fA-F]{6}。
[…]还有一种排除法,即不包含指定范围的字符。假设要匹配任意字符,但不包括数字,可以写[^1-9]{3}: - 可以匹配"ABC",因为不包含字符1~9;
- 可以匹配"A00",因为不包含字符1~9;
- 不能匹配"A01",因为包含字符1;
- 不能匹配"A05",因为包含字符5。
或规则匹配
用|连接的两个正则规则是或规则,例如,AB|CD表示可以匹配AB或CD。
public class Main {
public static void main(String[] args) {
String re = "java|php";
System.out.println("java".matches(re));
System.out.println("php".matches(re));
System.out.println("go".matches(re));
}
}
它可以匹配"java"或"php",但无法匹配"go"。
要把go也加进来匹配,可以改写为java|php|go。
使用括号
可以把公共部分提出来,然后用(…)把子规则括起来表示成learn\s(java|php|go)。
public class Main {
public static void main(String[] args) {
String re = "learn\\s(java|php|go)";
System.out.println("learn java".matches(re));
System.out.println("learn Java".matches(re));
System.out.println("learn php".matches(re));
System.out.println("learn Go".matches(re));
}
}
上面的规则仍然不能匹配learn Java、learn Go这样的字符串。试修改正则,使之能匹配大写字母开头的learn Java、learn Php、learn Go
分组匹配
(…)还有一个重要作用,就是分组匹配。
import java.util.regex.*;
public class Main {
public static void main(String[] args) {
Pattern p = Pattern.compile("(\\d{3,4})\\-(\\d{7,8})");
Matcher m = p.matcher("010-12345678");
if (m.matches()) {
String g1 = m.group(1);
String g2 = m.group(2);
System.out.println(g1);
System.out.println(g2);
} else {
System.out.println("匹配失败!");
}
}
}
运行上述代码,会得到两个匹配上的子串010和12345678。
要特别注意,Matcher.group(index)方法的参数用1表示第一个子串,2表示第二个子串。传入0得到010-12345678,即整个正则匹配到的字符串。
复使用String.matches()对同一个正则表达式进行多次匹配效率较低,因为每次都会创建出一样的Pattern对象。完全可以先创建出一个Pattern对象,然后反复使用,就可以实现编译一次,多次匹配。
import java.util.regex.*;
public class Main {
public static void main(String[] args) {
Pattern pattern = Pattern.compile("(\\d{3,4})\\-(\\d{7,8})");
pattern.matcher("010-12345678").matches(); // true
pattern.matcher("021-123456").matches(); // true
pattern.matcher("022#1234567").matches(); // false
// 获得Matcher对象:
Matcher matcher = pattern.matcher("010-12345678");
if (matcher.matches()) {
String whole = matcher.group(0); // "010-12345678", 0表示匹配的整个字符串
String area = matcher.group(1); // "010", 1表示匹配的第1个子串
String tel = matcher.group(2); // "12345678", 2表示匹配的第2个子串
System.out.println(area);
System.out.println(tel);
}
}
}
使用Matcher时,必须首先调用matches()判断是否匹配成功,匹配成功后,才能调用group()提取子串。
