文书网在9月份终于更新了,上去看了一下,无比的流畅。秉持着一颗探索,天真的童心看看文书网这次更新有啥突破和进展,一言不合直接打开开发者工具,仔细寻找了一番,看到了一个可疑的连接,定睛一看,wc,参数这么多,加入参数,最后的返回值内竟然没有自己想要的文本内容,到底怎么弄!!!,可能很多小伙伴看到这里就开始怀疑自己了,这是啥玩意嘛,弄得这么复杂,还能不能愉快的玩耍了!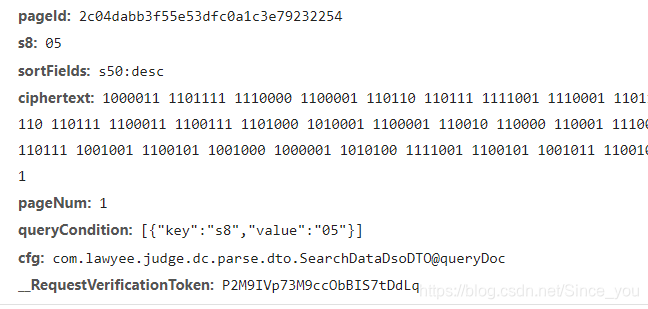
可是没办法嘛,我们要紧跟时代的步伐,慢慢来。经过一两个小时,调试js,终于拨开云雾,海阔天空。下面我们一一来分析这些参数。
1、pageid 其实这个参数我们可以猜想,可能是根据页数,通过某个加密函数进行加密,可是当我进行调试的时候,发现在改变页数的同时,他是不发生改变的。所以上面猜想失败。我全局搜索了一下pageid,出现很多,其中一个函数他尤其的亮眼,是他,是他,就是他,人群中最亮的仔。

其实观察源码发现,他是传入一个数,循环32次,每次输出一个16进制的数组成,没有什么难度。
2、s8 表示案件类型,05代表的是国家赔偿与司法救助案件,这些在wenshulist1.js这个js内全都有标注,可以自己去看(可以自己修改)
3、sortFields表示按照法院层级降序排列(可以自己修改)
4、ciphertext 这个参数其实也很好找,全局搜索

可以简单看下逻辑,前面几行都比较简单,重点是在 var enc这边,这边用到了一个DES3加密,也是这次更新可能唯一的难点,传入三个参数加密后,再经过strTobinary函数处理,就能得到该参数,DES3加密的函数在下方:
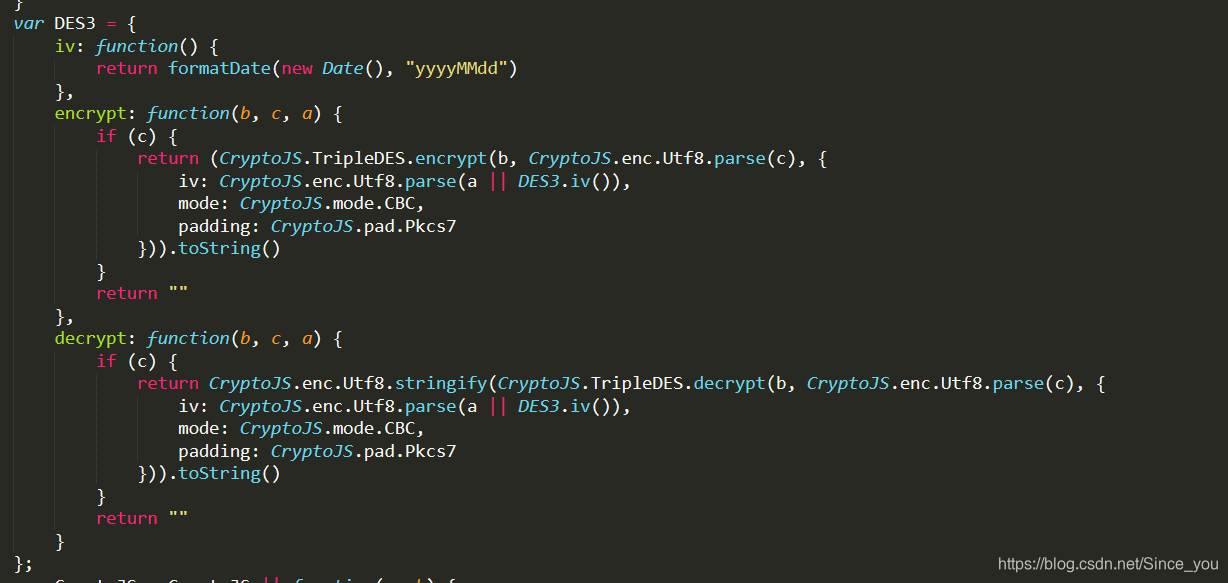
大约稍微那么一丢丢能看得懂,其实看不懂也没关系,python执行js就好了。
5、pagenum 当前的页数
6、querycondition 将之前那个转成字典再转化成列表就好了
7、cfg 固定参数
8、__RequestVerificationToken 唯一标致,也是一次获取后,后面也可以不发生改变,全局搜索下,是由这边生成的
function random(size){
var str = "",
arr = ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9', 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z', 'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z'];
for(var i=0; i<size; i++){
str += arr[Math.round(Math.random() * (arr.length-1))];
}
return str;
}
以上所有参数都基本上有逻辑能够写出来了,但是得到这些参数成功请求后,网站的作者还设置了一道坎,就是他会返回两个值,一个result,一个secretkey(还真是秘密钥匙),将这两个参数再进行一次DES3解码就能得到json数据了。其实整体看下来,没有以前难,甚至还有那么一丢丢小简单,下面就贴下代码,大家参考就好。
# coding=utf-8
import requests
import time
import execjs
import base64
import json
from pprint import pprint
from Cryptodome.Cipher import DES3
from Cryptodome.Util.Padding import unpad, pad
"""
2019年9月份文书网spider更新,简单看了下文书网更新过后的加密方式,整体比以前简单不少,
总结起来大概就是ciphertext这个参数是变化的,其他的基本上不会改变,传入data获取数据后,会有一个
DES3解密,其他的好像没什么难点(有可能没遇到坑),就大概写个逻辑脚本,需要完善
"""
# ----------------------------------自定义函数-------------------------------------------
# 获取ciphertext参数
def get_cipher():
with open ("c:\\Users\\包子xia\\Desktop\\file\\cipher.js",encoding='utf-8') as f:
js = f.read()
ctx =execjs.compile(js)
cipher = ctx.call("cipher")
return cipher
# 获取DES解密后的返回值
def get_result(result,secretKey,date):
des3 = DES3.new(key=secretKey.encode(), mode=DES3.MODE_CBC, iv=date.encode())
decrypted_data = des3.decrypt(base64.b64decode(result))
plain_text = unpad(decrypted_data, DES3.block_size).decode()
return plain_text
# 获取__RequestVerificationToken参数
def get_token():
js = """ function random(size){
var str = "",
arr = ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9', 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z', 'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z'];
for(var i=0; i<size; i++){
str += arr[Math.round(Math.random() * (arr.length-1))];
}
return str;
}
"""
ctx = execjs.compile(js)
result = ctx.call("random", "24")
return result
# 获取pageid
def get_pageid():
js = """function happy() {
var guid = "";
for (var i = 1; i <= 32; i++) {
var n = Math.floor(Math.random() * 16.0).toString(16);
guid += n;
// if ((i == 8) || (i == 12) || (i == 16) || (i == 20)) guid +=
// "-";
}
return guid;
}"""
ctx = execjs.compile(js)
pageid = ctx.call("happy")
return pageid
#-------------------------------自定义函数结束-----------------------------------------
class wenshu(object):
def __init__(self):
self.session = requests.Session()
self.headers = {
"Cookie":"SESSION=f25ce583-7609-43ba-bb12-a0f3cdb15515",
"Host":"wenshu.court.gov.cn",
"Origin":"http://wenshu.court.gov.cn",
"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36",
}
def get_docid(self):
"""文书列表页"""
url = "http://wenshu.court.gov.cn/website/parse/rest.q4w"
data = {
"s8": "04",
"pageId": "%s" % get_pageid(),
"sortFields": "s50:desc", # 按照法院层级降序排列
"ciphertext": "%s" % get_cipher(),
"pageNum": "1",
"pageSize": "5",
"queryCondition": '[{"key":"s8","value":"04"}]', # 这边可以自定义选择,04表示行政案件
"cfg": "com.lawyee.judge.dc.parse.dto.SearchDataDsoDTO@queryDoc",
"__RequestVerificationToken": "%s" % get_token()
}
response = self.session.post(url, data=data,headers=self.headers)
json_value = json.loads(response.text)
secretKey = json_value["secretKey"]
result = json_value["result"]
data = json.loads(get_result(result, secretKey, time.strftime("%Y%m%d")))
for key in data["queryResult"]["resultList"]:
rowkey = key["rowkey"]
self.detail_page(rowkey)
def detail_page(self,docid):
"""文书详情页"""
url = "http://wenshu.court.gov.cn/website/parse/rest.q4w"
data = {
"docId": "%s" % docid,
"ciphertext": get_cipher(),
"cfg": "com.lawyee.judge.dc.parse.dto.SearchDataDsoDTO@docInfoSearch",
"__RequestVerificationToken": "%s" % get_token(),
}
response = self.session.post(url, data=data,headers=self.headers)
json_value = json.loads(response.text)
secretKey = json_value["secretKey"]
result = json_value["result"]
data = json.loads(get_result(result, secretKey, time.strftime("%Y%m%d")))
pprint(data)
if __name__ == '__main__':
demo = wenshu()
demo.get_docid()
上面有一个js文件,我是用pyexecjs执行的,就不贴出来。本项目也是自己出于兴趣,想解析下看看。也是希望大家对网站手下留情,速度慢一点,温柔一点,这样对大家都好。
在此声明,如需转载,请标注来源。本文章也是记录自己的技术实践,绝无破坏网站运行的想法,如若被他人用于商业用途,与本人无关。同时欢迎访问个人博客主页… …

