简介
这个的介绍在我的另一篇博文中(Beam-介绍),在此不在再赘述,最近碰到个有意思的事,聊聊beam的链路,简单来说自己操作的一些函数中间有些转换组件,注册在链路中,在此截了一张官网的图片。
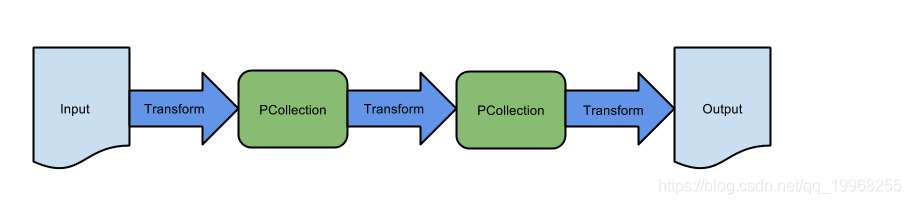
这是简单链路大概样子,各个函数串联在一起,当然了实际中不可能这样一帆风顺,肯定遇到很多种情况,我列下几种情况分享下。
集合注册
PipelineOptionsFactory.register(IndexerPipelineOptions.class);
Pipeline pipeline = Pipeline.create(options);
PCollection<String> p1 = pipeline.apply(TextIO.read().from("")).apply(ParDo.of(new DoFn<String, String>() {
@ProcessElement
public void processElement(ProcessContext c) throws Exception {
System.out.println(c.element().toString());
}
}));
PCollectionList<String> plist = PCollectionList.empty(pipeline);
plist.and(p1);
pipeline.run();以导流的方式放到beam的集合,不断apply函数等等,形成多种链路,中间可以拆分导流集合,或者合并集合都很简单我就不说了,当然这些存储的都是计划,并没有数据,核心思想移动计算不移动数据。
错误案例1
public static void main(String[] args) throws PropertyVetoException {
IndexerPipelineOptions options = PipelineOptionsFactory.fromArgs(args).withValidation().as(IndexerPipelineOptions.class);
PipelineOptionsFactory.register(IndexerPipelineOptions.class);
Pipeline pipeline = Pipeline.create(options);
String s1="insert into test values('11','11')";
String s2="insert into test values('12','12')";
String s3="insert into test values('13','13')";
String s5="insert into test values('15','15')";
String s6="insert into test values('16','16')";
String s7="insert into test values('17','17')";
String s4="insert into test values('14','14')";
save(pipeline,s1);
save(pipeline,s2);
save(pipeline,s3);
save(pipeline,s4);
save(pipeline,s5);
save(pipeline,s6);
save(pipeline,s7);
pipeline.run();
}
public static void save(Pipeline pipeline,String sql) throws PropertyVetoException {
ComboPooledDataSource cpds = new ComboPooledDataSource();
cpds.setDriverClass("com.mysql.jdbc.Driver");
cpds.setJdbcUrl("jdbc:mysql://xxxx:3306/bigdata?characterEncoding=utf8&useSSL=true");
cpds.setUser("root");
cpds.setPassword("root");
Schema type =
Schema.builder().addStringField("sass").build();
Row build = Row.withSchema(type).addValue("123").build();
pipeline
.apply(Create.of(build))
.apply(
JdbcIO.<Row>write()
.withDataSourceConfiguration(
JdbcIO.DataSourceConfiguration.create(
cpds))
.withStatement(sql)
.withPreparedStatementSetter(
(element, statement) -> {
})
);
}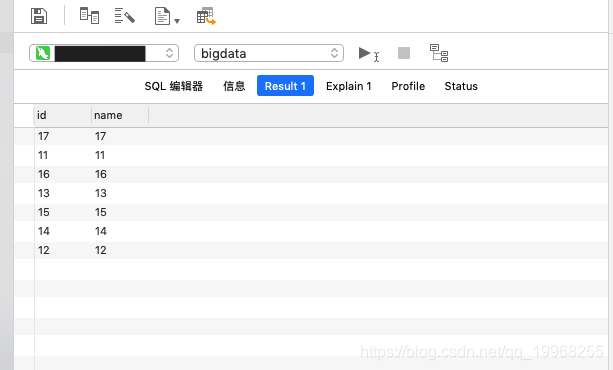
一个简单的多语句多输出的操作,输出多个PDone(Poutput),因为在同个pipeline中分发不同的输出,又因beam集合本身是无序,注册时没有依赖关系,分发任务不会排序,所以结果乱序。这种情形会很多,比如返回很多pipeline对象再注册继续会乱序的,比如PCollection注册链路再一起多个输出也会如此结果,比如PCollectionList注册顺序后输出结果也会乱序等等,经历过很多失败。
我使用JDBCIO连接hive一些大数据体系的库,这样用beam才会用到些精髓的东西,做这些测试案例用mysql因为方便些,原理相似。
错误案例2
Schema type = Schema.builder().addStringField("test").build();
Row row = Row.withSchema(type).addValue("test").build();
PCollection<Row> r1 = pipeline.apply("r1",Create.of(row));
PCollection<Row> r2 = pipeline.apply("r2",Create.of(row));
PCollection<Row> r3 = pipeline.apply("r2",Create.of(row));
PCollection<Row> r4= pipeline.apply("r4",Create.of(row));
PCollection<Row> r5 = pipeline.apply("r5",Create.of(row));
PCollection<Row> r6= pipeline.apply("r6",Create.of(row));
PCollection<Row> r7 = pipeline.apply("r7",Create.of(row));
PCollectionList<Row> pl = PCollectionList.of(r1).and(r2).and(r3).and(r4).and(r5).and(r6).and(r7);
List<PCollection<Row>> all = pl.getAll();
for (int i = 0; i < all.size(); i++) {
save2(all.get(i),l.get(i));
}
这样链路输出结果依旧会乱。
正确的操作
public static void main(String[] args) throws PropertyVetoException {
IndexerPipelineOptions options = PipelineOptionsFactory.fromArgs(args).withValidation().as(IndexerPipelineOptions.class);
PipelineOptionsFactory.register(IndexerPipelineOptions.class);
Pipeline pipeline = Pipeline.create(options);
Pipeline pipeline2 = Pipeline.create(options);
Pipeline pipeline3 = Pipeline.create(options);
Pipeline pipeline4 = Pipeline.create(options);
String s1="insert into test values('11','11')";
String s2="insert into test values('12','12')";
String s3="insert into test values('13','13')";
String s5="insert into test values('15','15')";
String s6="insert into test values('16','16')";
String s7="insert into test values('17','17')";
String s4="insert into test values('14','14')";
save(pipeline,s1).getPipeline().run();
save(pipeline2,s2).getPipeline().run();
save(pipeline3,s3).getPipeline().run();
save(pipeline4,s4).getPipeline().run();
}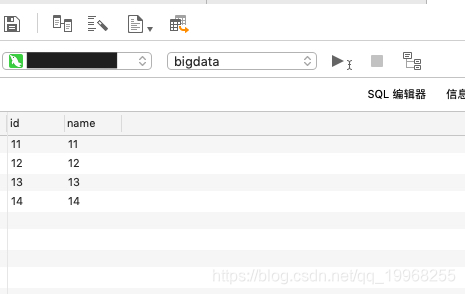
其实这个用到核心思想,我在其他博文中讲到的大数据处理四大设计模式-分离处理模式(如果你在处理数据集时并不想丢弃里面的任何数据,而是想把数据分类为不同的类别进行处理时,你就需要用到分离式来处理数据。)的应用,一个pipeline解决不了,拆分多个管道处理,多次运行,分离开来,当然效率会有损害(朋友们可以思考下),我说了说一些想法,有错误踩过的坑,有正确的做法,都是积累,分享给朋友们,有更好想法交流交流。
Beam-介绍:https://blog.csdn.net/qq_19968255/article/details/96158013
