Hadoop基本理论知识
- HDFS(Hadoop Distributed File System)基于Google发布的论文设计开发
- 具备其它分布式文件系统相同特性外,还有特有的特性:
高容错性:认为硬件总是不可靠的
高吞吐量:认为大量数据访问的应用提供高吞吐量支持
大文件存储:支持存储TB-PB级别的数据 - HDFS适合做什么?
大文件存储与访问
流式数据访问 - HDFS不适合做什么?
大量小文件存储
随机写入
低延迟读取
HDFS应用场景举例:
-
HDFS是Hadoop技术框架中的分布式文件系统,对部署在独立物理机器上的文件进行管理。
-
可用于多种场景,如:
-
网站用户行为数据存储
-
生态系统数据存储
-
气象数据存储
基本系统架构
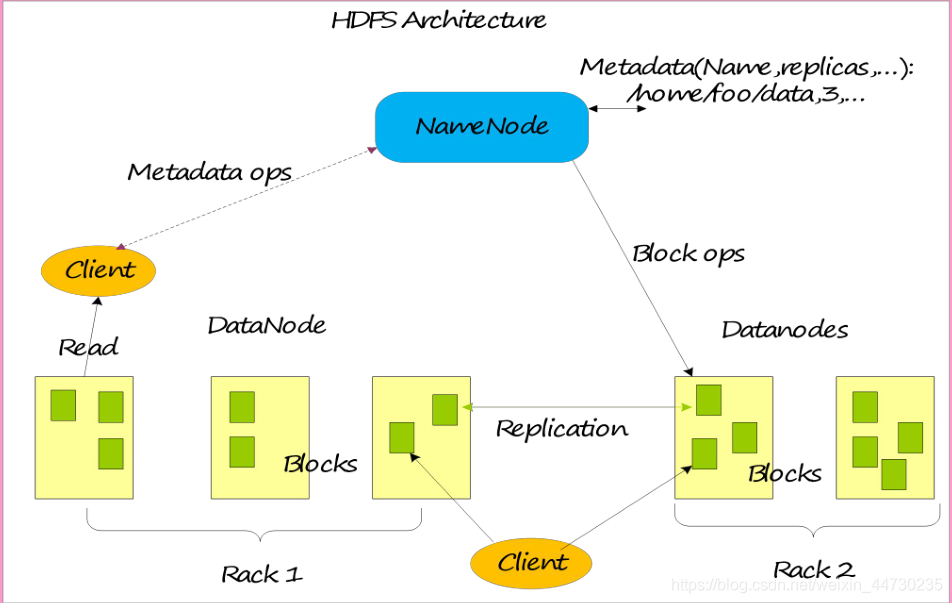
HDFS架构关键设计
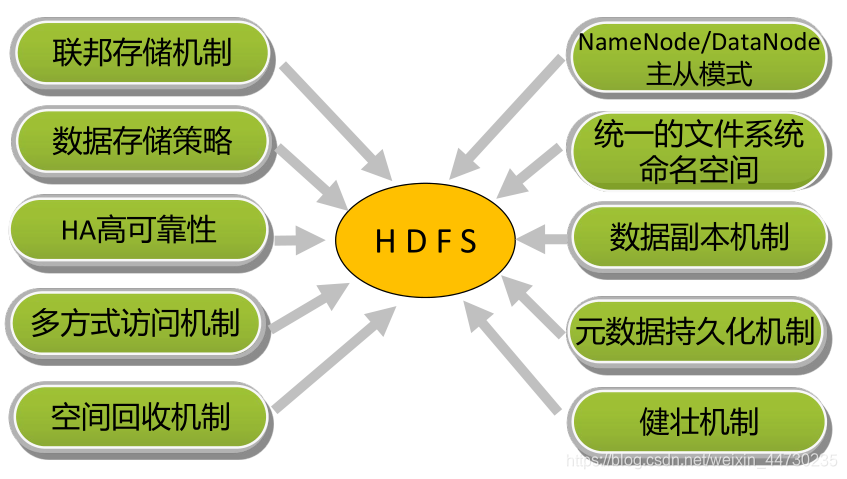
HDFS高可靠性(HA)
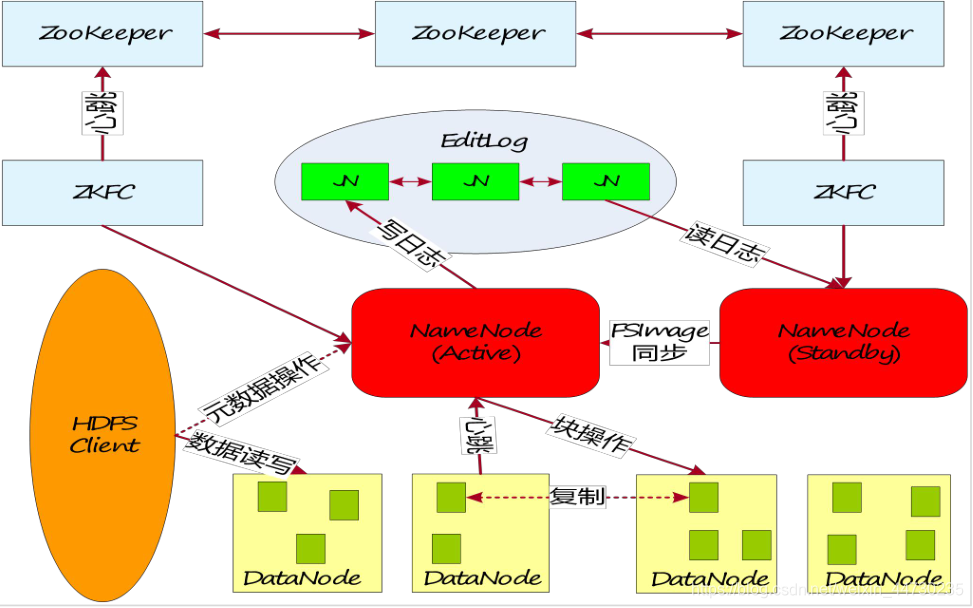
元数据持久化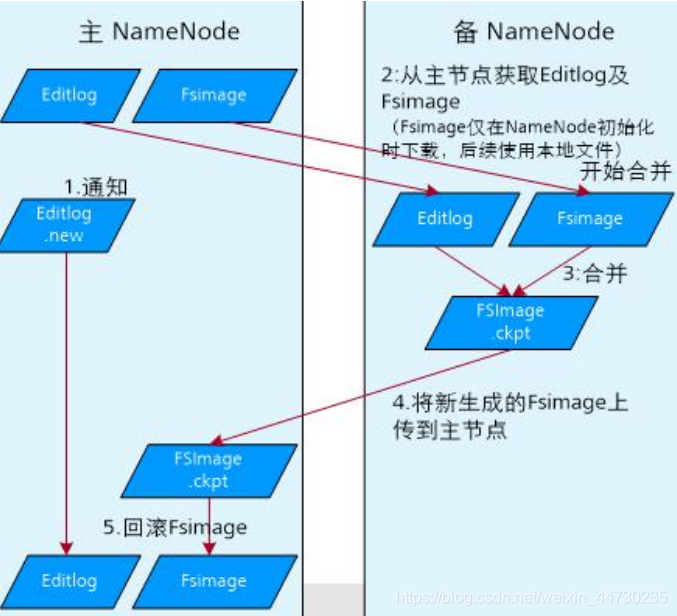
配置HDFS数据存储策略
-
默认情况下,HDFS NameNode自动选择DataNode保存数据的副本。实际业务中,存在以下场景:
-
DataNode上存在的不同的存储设备,数据需要选择一个合适的存储设备分级存储数据
-
DataNode不同目录中的数据重要程度不同,数据需要根据目录标签选择一个合适的DataNode节点保存
-
DataNode集群使用了异构服务器,关键数据需要保存在具有高度可靠性的节点组中。
HDFS数据完整性保障
-
HDFS主要目的是保证存储数据完整性,对于各组件的失效,做了可靠性处理。
-
重建失效数据盘的副本数据:DataNode向NameNode周期上报失败时,NameNode发起副本重建动作以恢复丢失副本。
-
集群数据均衡:数据均衡机制,此机制保证数据在各个DataNode上分布是平均的
-
元数据可靠性保证
-
采用日志机制操作元数据,同时元数据存放在主备NameNode上
-
快照机制实现了文件系统常见的快照机制,保证数据误操作时,能及时恢复。
-
安全模式:在数据节点故障,硬盘故障时,能防止故障扩散。
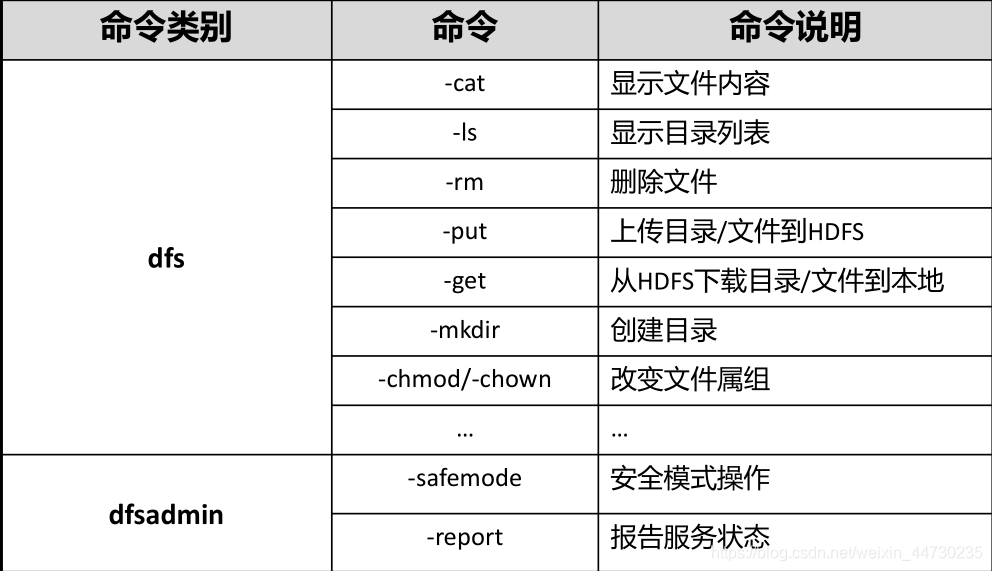
常用shell命令