一、准备工作
1、启动hadoop集群
[root@hadoop129 hadoop-2.5.0-cdh5.3.6]# start-dfs.sh
2、启动hive
[root@hadoop129 hive-0.13.1-cdh5.3.6]# hive
3、创建数据库表
create database text01;
create database if not exists text02;

hive数据库及表都是保存在HDFS文件系统里,注意,数据库和表对应的都是目录,不是文件。
利用HDFS Explorer查看刚才创建的数据库test01.db与test02.db:

大家可以看到创建的hive数据库默认位置:/user/hive/warehouse。
4、查看数据库
1、查看所有数据库

除了我们刚才创建的test01、test02,还有一个默认的default数据库。注意:test01与test02数据库在默认位置/user/hive/warehouse
2、查询满足条件的数据库
hive> show databases like ‘test*’;
hive> show databases like ‘*02’;

5、修改数据库信息
给数据库添加键值对信息
hive> alter database test02 set dbproperties(‘id’=‘202001’, ‘name’=‘qingjiabo1997’);

hive> create database test05 with dbproperties(‘name’=‘qingjiabo’, ‘date’=‘2020-2-1’);

6、查看数据库信息
hive> desc database test01;
hive> desc database extended test02;
hive> desc database test04;
hive> desc database extended test05;

7、使用数据库
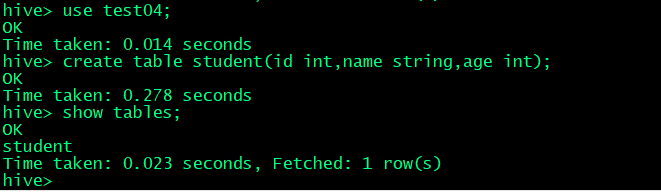
hive>use test04;
此时,test04成为当前数据库,可以在里面创建数据表了
8、删除数据库
删除数据库test05:
hive> drop database if exists test05;

删除数据库test04:
hive> drop database if exists test04;

test04数据库里包含数据表,那么必须添加cascade参数才能删除
hive> drop database if exists test04 cascade;

二、数据表操作
使用数据库test01:
hive> use test01;
1、创建数据表
hive> create table student(id int, name string, age int);
hive> create table employees (
> name string,
> salary float,
> subordinates array<string>,
> duductions map<string, float>,
> address struct<street:string, city:string, state:string, zip:int>)
> row format delimited
> fields terminated by ','
> collection items terminated by '|'
> map keys terminated by ':'
> stored as textfile;
2、查看数据库里的表
(1)在hive里查看数据库里的表
hive> show tables;
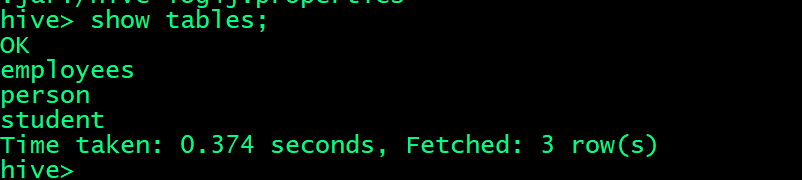
2)利用HDFS Explorer查看创建的表

