之前我们已经介绍过全量索引和增量索引了,对于增量索引,我们使用了logstash定时,1分钟扫描一次,虽然可以解决一些问题,但是对于大数据量的,可能并不适用,因此再介绍一个新的索引构建中间件。
我们对增量构建的要求:准实时性(可以理解为异步),性能要求,编程简化要求。
关于阿里canal,可以理解为一个消息管道,管道中有一个source可以理解为mysql数据库,target可以理解为其他存储,在这就是es。
可以看下文档https://github.com/alibaba/canal,里面有介绍关于原理方面。

首先需要开启mysql的binary log,默认是关闭的,在mysql目录下,my.ini:
在最后加上:
#因为开启binary log是为了同步分布式数据使用的,所以每个节点都要有id
server-id=1
#mysql使用行方式做binary log存储
binlog_format=ROW
#binary log文件相对路径
log_bin=mysql_bin
然后重启,查看命令:show variables like 'log_bin';
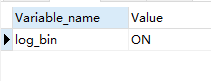
这样,mysql就会将 binary log写入指定的磁盘文件。
接下来,需要有一个复制权限的账户给canal,
CREATE USER canal IDENTIFIED BY 'canal';
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%' indentified by 'canal';
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'localhost' indentified by 'canal';
FLUSH PRIVILEGES;在上面网址下载canal.deployer,然后打开conf\example\instance.properties
## mysql serverId
canal.instance.mysql.slaveId = 1234
#position info,需要改成自己的数据库信息
canal.instance.master.address = 127.0.0.1:3306
canal.instance.master.journal.name =
canal.instance.master.position =
canal.instance.master.timestamp =
#canal.instance.standby.address =
#canal.instance.standby.journal.name =
#canal.instance.standby.position =
#canal.instance.standby.timestamp =
#username/password,需要改成自己的数据库信息
canal.instance.dbUsername = canal
canal.instance.dbPassword = canal
canal.instance.defaultDatabaseName =
canal.instance.connectionCharset = UTF-8
#table regex
canal.instance.filter.regex = .\*\\\\..\*然后启动,没问题即可。
接下来下载canal adapter,1.3的版本不支持es6,所以可以把源码下下来,把pom中的版本号改掉再打包就好。
conf/application.yml中将下面注释放开,因为canal在机器上已经监听数据库了,这个canal adapter可以指定监听哪个数据库:

改为
srcDataSources:
defaultDS:
url: jdbc:mysql://127.0.0.1:3306/dianpingdb?useUnicode=true
username: canal
password: canal将最后的es配置放开:
- name: es
hosts: 127.0.0.1:9300
properties:
cluster.name: dianping-app在conf/es下新建shop.yml
第一行要跟上面的yaml保持一致
第二行代表要监听配的example
最后是指以3000条做批量添加
dataSourceKey: defaultDS
destination: example
groupId:
esMapping:
_indent: shop
_type: _doc
_id: id
upsert: true
sql: "select a.id,a.name,a.tags,concat(a.latitude,',',a.longitude) as location,a.remark_score,a.price_per_man,a.category_id,b.name as category_name,a.seller_id,c.remark_score as seller_remark_score,c.disabled_flag as seller_disabled_flag from shop a inner join category b on a.category_id = b.id inner join seller c on c.id = a.seller_id"
commitBatch: 3000启动即可。
接下来可以测试一下,在数据库改一下,相对的es就改变了。
上面貌似可以用了,但是在多表的情况下,对于canal的机制,他可以感知到是某一行的某个字段发生版画,但上面sql的字段a.name和b.name,canal会把这两个当成同一个字段去修改,这就跟我们想要的不符了。要解决这个问题,我们可以自定义canal的接入。
加依赖:
<!-- https://mvnrepository.com/artifact/com.alibaba.otter/canal.protocol -->
<dependency>
<groupId>com.alibaba.otter</groupId>
<artifactId>canal.protocol</artifactId>
<version>1.1.3</version>
</dependency>
<!-- https://mvnrepository.com/artifact/com.alibaba.otter/canal.common -->
<dependency>
<groupId>com.alibaba.otter</groupId>
<artifactId>canal.common</artifactId>
<version>1.1.3</version>
</dependency>
<!-- https://mvnrepository.com/artifact/com.alibaba.otter/canal.client -->
<dependency>
<groupId>com.alibaba.otter</groupId>
<artifactId>canal.client</artifactId>
<version>1.1.3</version>
</dependency>代码:
@Component
public class CanalClient implements DisposableBean {
private CanalConnector canalConnector;
@Bean
public CanalConnector getCanalConnector(){
canalConnector = CanalConnectors.newClusterConnector(
Lists.newArrayList(new InetSocketAddress("127.9.9.1" , 11111)),
"example",
"canal",
"canal"
);
canalConnector.connect();
//指定filter,格式{database}.{table}
canalConnector.subscribe();
//回滚寻找上次中断的位置(我们的canal client去消费canal的管道是个流式的操作,如果在中途被中断了,那么canal client会记录终端的位置)
canalConnector.rollback();
return canalConnector;
}
@Override
public void destroy() throws Exception {
if (canalConnector != null){
canalConnector.disconnect();
}
}
}DisposableBean 是在程序结束的时候回调,也就是保证在程序结束的时候canal断开连接。
消息的消费过程可以类比为canal client从canal deployer中拉取数据库同步过来的消息,然后返给deployer信号说消息已经完成。所以还需要一个消息消费的类:
@Component
public class CanalScheduling implements Runnable , ApplicationContextAware {
private ApplicationContext applicationContext;
@Autowired
private ShopModelMapper shopModelMapper;
@Resource
private CanalConnector canalConnector;
@Autowired
private RestHighLevelClient restHighLevelClient;
@Override
@Scheduled(fixedDelay = 100)
public void run() {
long batchId = -1;
try {
int batchSize = 1000;
//从对应的canal中获取1000条消息,并且没有ack
Message message = canalConnector.getWithoutAck(batchSize);
batchId = message.getId();
List<CanalEntry.Entry> entries = message.getEntries();
if (batchId != -1 && entries.size() > 0){
entries.forEach(entry -> {
if (entry.getEntryType() == CanalEntry.EntryType.ROWDATA){
//解析处理
publishCanalEvent(entry);
}
});
}
canalConnector.ack(batchId);
}catch (Exception e){
e.printStackTrace();
canalConnector.rollback(batchId);
}
}
private void publishCanalEvent(CanalEntry.Entry entry){
CanalEntry.EventType eventType = entry.getHeader().getEventType();
String database = entry.getHeader().getSchemaName();
String table = entry.getHeader().getTableName();
CanalEntry.RowChange change = null;
try {
change = CanalEntry.RowChange.parseFrom(entry.getStoreValue());
} catch (InvalidProtocolBufferException e) {
e.printStackTrace();
}
change.getRowDatasList().forEach(rowData -> {
List<CanalEntry.Column> columns = rowData.getAfterColumnsList();
String primaryKey = "id";
CanalEntry.Column idColumn = columns.stream().filter(column ->
column.getIsKey()
&& primaryKey.equals(column.getName())).findFirst().orElse(null);
Map<String , Object> dataMap = parseColumnsToMap(columns);
try {
indexES(dataMap , database , table);
} catch (IOException e) {
e.printStackTrace();
}
});
}
Map<String , Object> parseColumnsToMap(List<CanalEntry.Column> columns){
Map<String , Object> jsonMap = new HashMap<String , Object>();
columns.forEach(column -> {
if(column == null){
return;
}
jsonMap.put(column.getName() , column.getValue());
});
return jsonMap;
}
private void indexES(Map<String , Object> dataMap , String database , String table) throws IOException {
indexES(dataMap,database,table);
if(!"dianpingdb".equals(database)){
return;
}
List<Map<String,Object>> result = new ArrayList<>();
if(!"seller".equals(table)){
result = shopModelMapper.buildESQuery(new Integer((String)dataMap.get("id")),null,null);
}else if(!"category".equals(table)){
result = shopModelMapper.buildESQuery(null,new Integer((String)dataMap.get("id")),null);
}else if(!"shop".equals(table)){
result = shopModelMapper.buildESQuery(null,null,new Integer((String)dataMap.get("id")));
}else{
return;
}
for(Map<String,Object>map : result){
IndexRequest indexRequest = new IndexRequest("shop");
indexRequest.id(String.valueOf(map.get("id")));
indexRequest.source(map);
restHighLevelClient.index(indexRequest, RequestOptions.DEFAULT);
}
}
@Override
public void setApplicationContext(ApplicationContext applicationContext) throws BeansException {
this.applicationContext = applicationContext;
}
}<select id="buildESQuery" resultType="java.util.Map">
select a.id,
a.name,
a.tags,
concat(a.latitude,',',a.longitude) as location,
a.remark_score,
a.price_per_man,
a.category_id,
b.name as category_name,
a.seller_id,
c.remark_score as seller_remark_score,
c.disabled_flag as seller_disabled_flag
from shop a
inner join category b on a.category_id = b.id
inner join seller c on c.id = a.seller_id
<if test="sellerId!=null">
and c.id = #{sellerId}
</if>
<if test="sellerId!=null">
and b.id = #{sellerId}
</if>
<if test="sellerId!=null">
and a.id = #{sellerId}
</if>
</select>这里只写了主要代码,逻辑总的来说就是java通过定时任务,每100秒从canal中获取消息,如果有的话,就获取具体修改的哪个库、哪个表、哪个字段,然后获取到对应的id,然后根据id去查相应的表的数据,然后用es的api把某一条数据更新到es上。这样就更灵活、可以根据业务逻辑去进行编写了。
