一、需求
使用kettle将源库多张表批量同步到目标库。
二、设计
整体设计流程如下:
1、在数据开始同步前,在目标库中的日志表记录数据同步开始时间;
2、将所有需要同步的表名放在目标库的一张表中,在kettle中读取这些表名;
3、循环读取每一个表名,进行表数据同步;
4、所有表同步完成后,更新日志表的结束时间。
整个job如下:
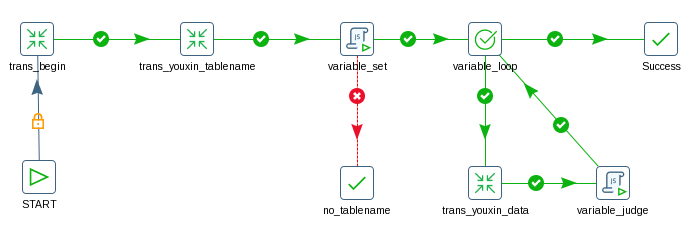
下面再详细看看job里的每个组件:
1、trans_begin
组件:General->Transformation
功能:更新日志表里数据同步开始时间。

配置如下:

2、trans_youxin_tablename
组件:General->Transformation
功能:读取所有要同步的表名。
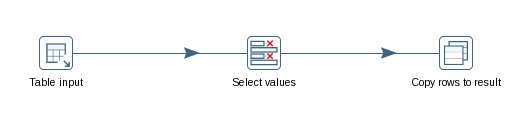
2.1 Table input
组件:Input->Table input
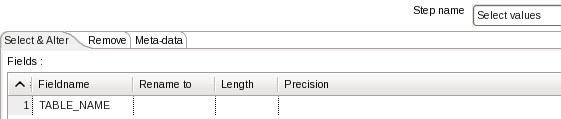
功能:目标库有一张表存放所有要同步的表名,读取这张表记录。(表里面有两个字段:序列号SEQ_NO、表名TABLE_NAME,序列号从1开始递增)

2.2 Select values
组件:Transform->Select values
功能:获取所有表名。
2.3 Copy rows to result
组件:Utility->Clone row
功能:将表名放到结果集。
3、variable_set
组件:Scripting->JavaScript
功能:设置变量。
内容如下:
var prevRow=previous_result.getRows();
if (prevRow == null &&(prevRow.size()=0))
{
false;
}else{
parent_job.setVariable("tables", prevRow);
parent_job.setVariable("size", prevRow.size());
parent_job.setVariable("i", 0);
parent_job.setVariable("tablename", prevRow.get(0).getString("TABLE_NAME",""));
true;
}
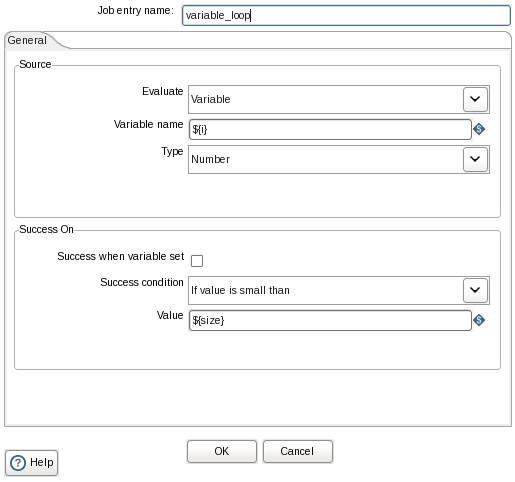
4、 variable_loop
组件:Conditions->simple evaluation
功能:循环读取每个表名。
5、trans_youxin_data
组件:General->Transformation
功能:将源表同步到目标表。

5.1 Table input
组件:Input->Table input
功能:读取源表数据。

5.2 Table output
组件:Output->Table output
功能:将数据写入目标表。

5.3 Blocking Step
组件:Flow->Blocking Step
功能:在前面的Table input和Table output执行完成之后,才执行后面的update log。

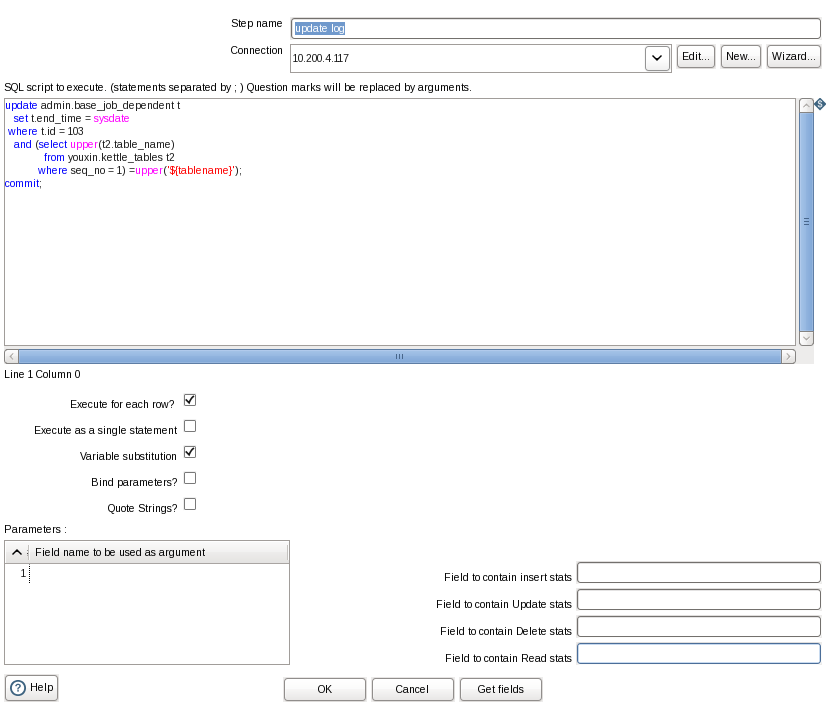
5.4 update log
组件:Scripting->Execute SQL Script
功能:在步骤2.1可以看到,读取表名是按照SEQ_NO倒序,最后读的是SEQ_NO=1的表名。因为是循环处理每个表的同步,如果发现已经处理到了SEQ_NO=1的表,说明全部表同步完成,这时就可以更新日志表的结束时间。
6、variable_judge
组件:Scripting->JavaScript
功能:获取当前处理的表名。
内容如下:
var list_Tables =parent_job.getVariable("tables").replace(" ","").replace("[","").replace("]","").split(",");
var size = new Number(parent_job.getVariable("size"));
var i = new Number(parent_job.getVariable("i"))+1;
if(i<size){
parent_job.setVariable("tablename", list_Tables[i].trim());
}
parent_job.setVariable("i",i);
true;
完毕。
