文章目录
1.实验目的
在hiring.csv中,包含公司的招聘信息,例如候选人的工作经验,笔试成绩和个人面试成绩。 基于这三个因素,人力资源将决定工资。 有了这些数据,您需要为人力资源部门建立一个机器学习模型,以帮助他们确定未来应聘者的薪水。 使用此预测薪水来预测以下候选人薪资,
(1)2年工作经验,测试成绩9,面试成绩6
(2)12年工作经验,测试分数10,面试分数10
2.导入必要模块并读取数据
import pandas as pd
import numpy as np
from sklearn.linear_model import LinearRegression
from word2number import w2n
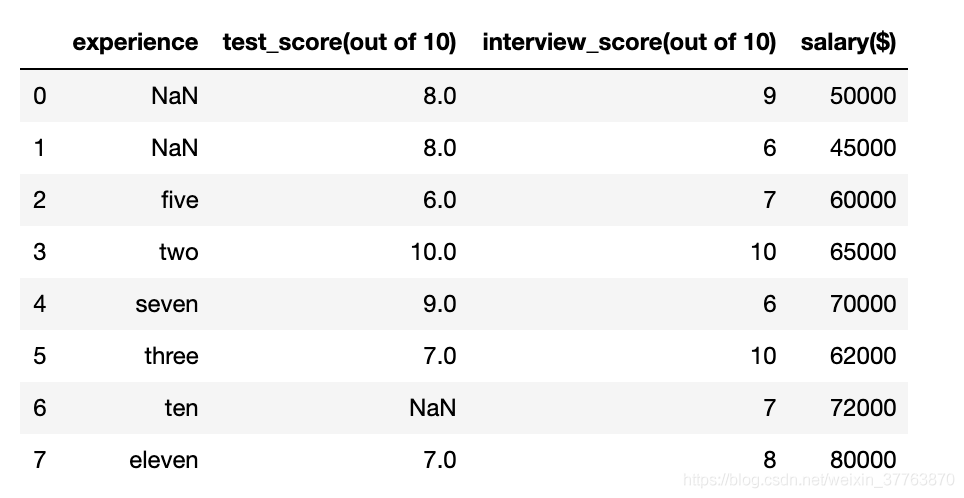
df = pd.read_csv('hiring.csv')
df
3.对数据进行处理
3.1.experience字段数字化
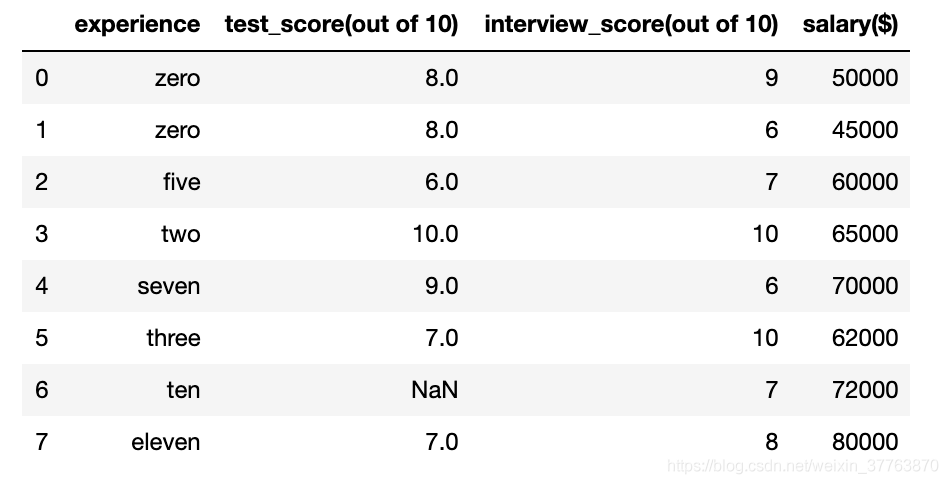
df.experience = df.experience.fillna('zero') #NaN统一替换为zero
df
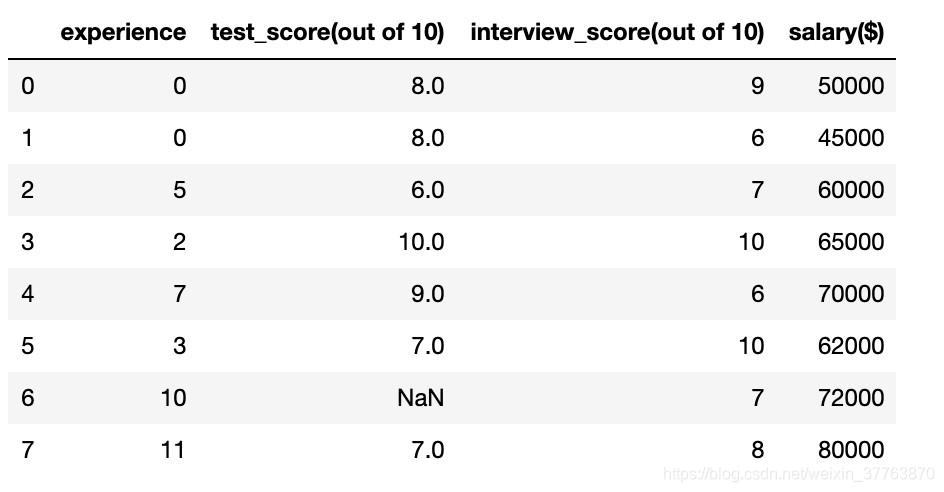
df.experience = df.experience.apply(w2n.word_to_num) #运用w2n.word_to_num将字母转化为数字
df
3.2.test_score(out of 10)字段NaN替换为平均数
import math
median_test_score = math.floor(df['test_score(out of 10)'].mean()) #取平均数并向下取整
median_test_score
#输出
7
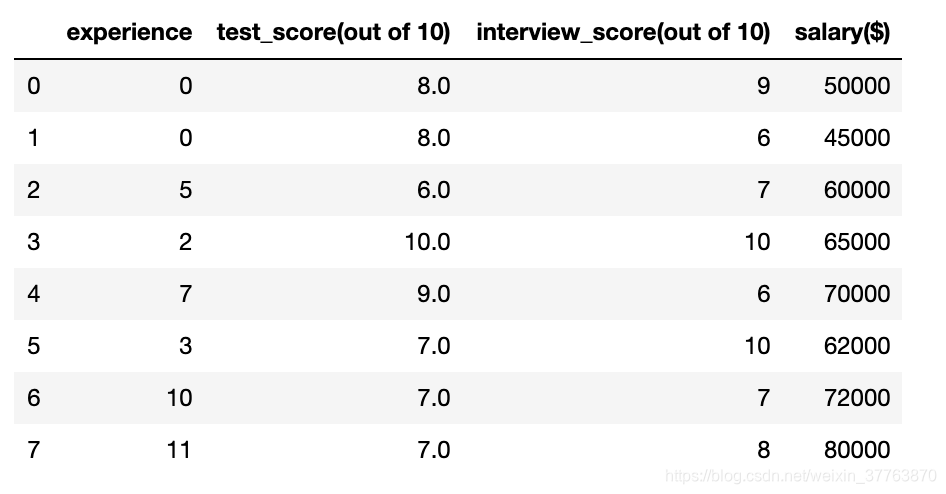
df['test_score(out of 10)'] = df['test_score(out of 10)'].fillna(median_test_score) #用平均数填充NaN
df
4.训练+预测
reg = LinearRegression() #实例化模型
reg.fit(df[['experience','test_score(out of 10)','interview_score(out of 10)']],df['salary($)']) #训练
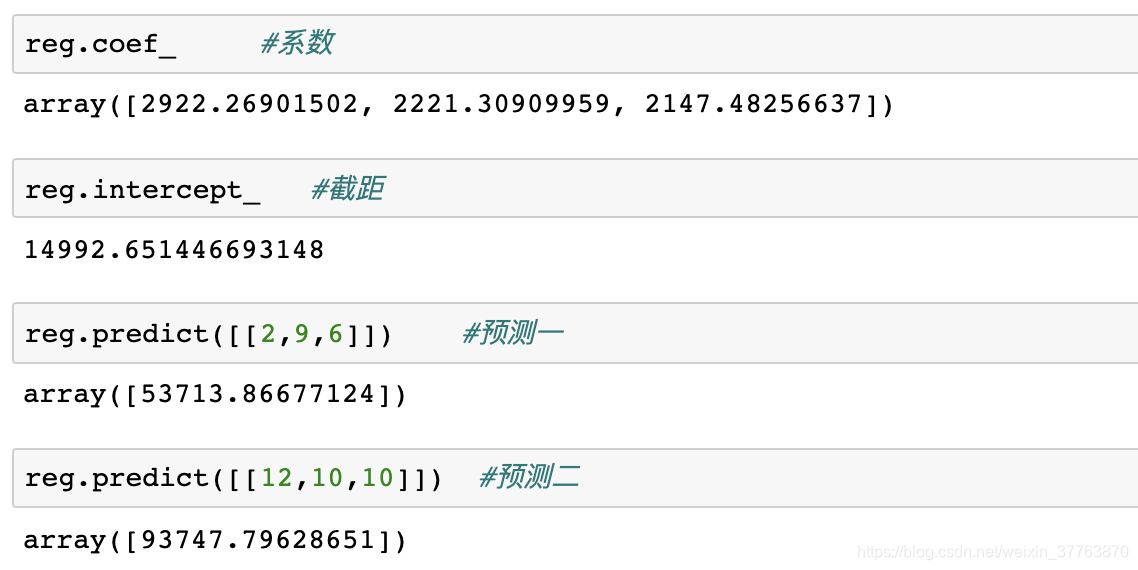
reg.coef_ #系数
reg.intercept_ #截距
reg.predict([[2,9,6]]) #预测一
reg.predict([[12,10,10]]) #预测二