写在前面
文中代码或伪代码均为网上摘抄,本人代码要的私!
hw2
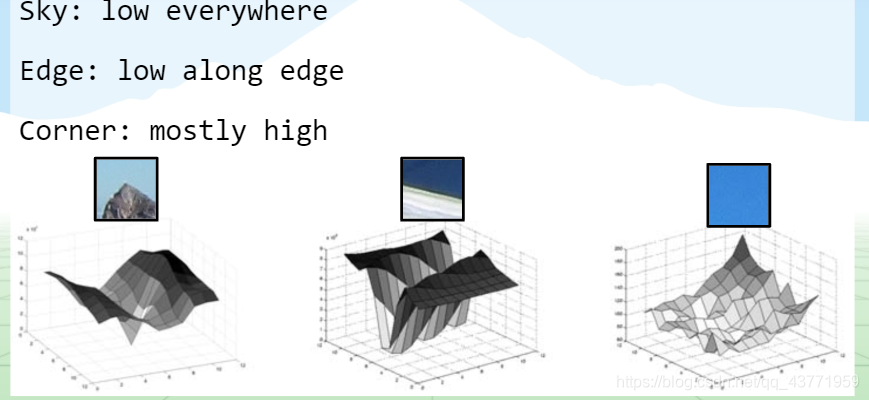
1、哈里斯角点检测
特征点计算

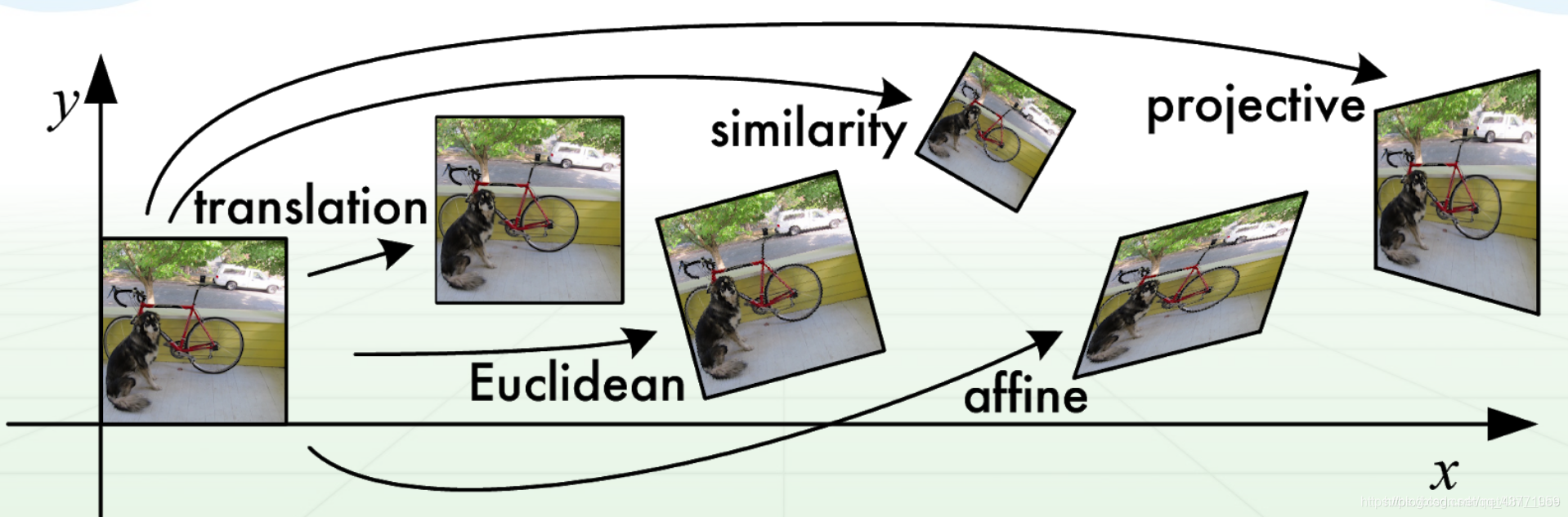
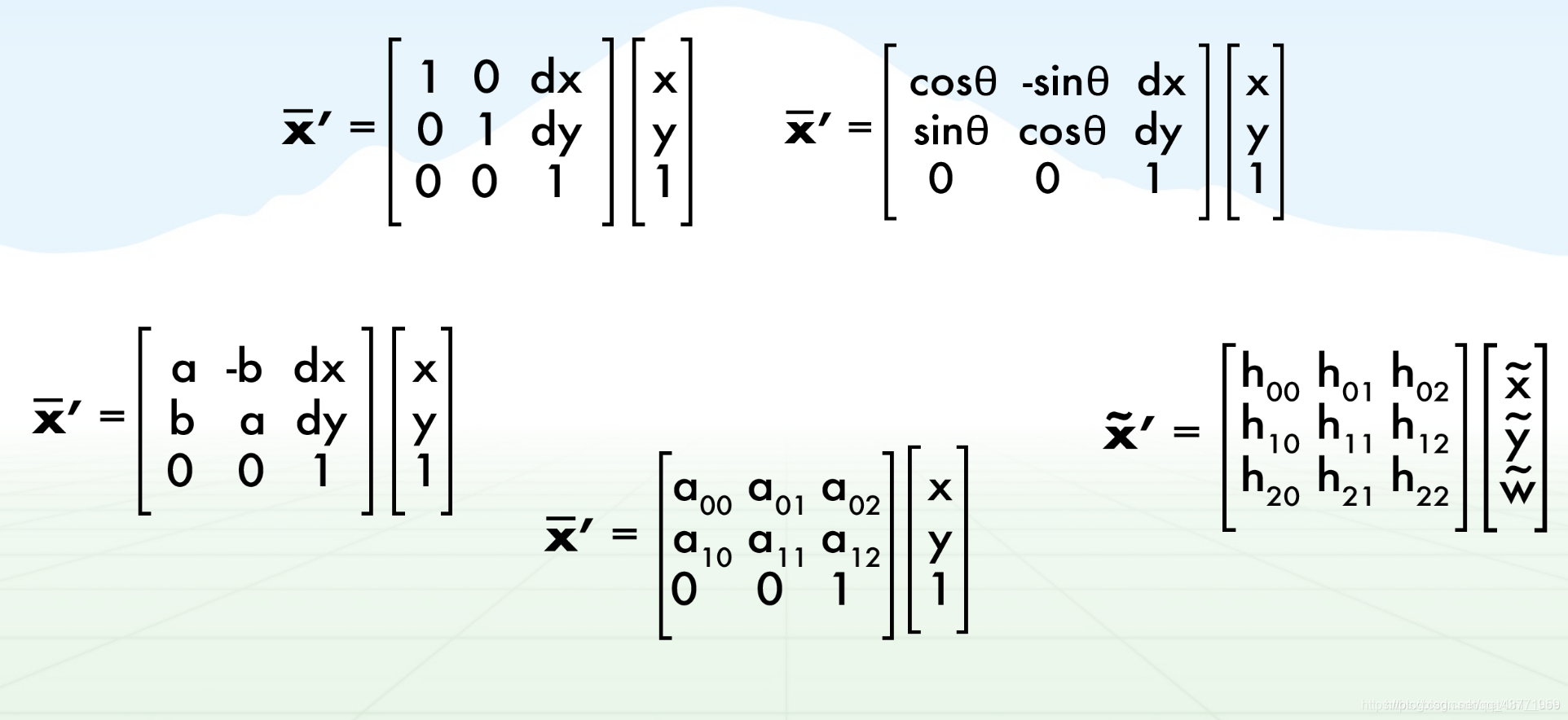
仿射:(本质坐标变换)

非最大抑制(NMS)
在进行目标检测时一般会采取窗口滑动的方式,在图像上生成很多的候选框,然后把这些候选框进行特征提取后送入分类器,一般会得出一个得分(score),比如人脸检测,会在很多框上都有得分,然后把这些得分全部排序。选取得分最高的那个框,接下来计算其他的框与当前框的重合程度(iou),如果重合程度大于一定阈值就删除,因为在同一个脸上可能会有好几个高得分的框,都是人脸但是不需要那么框我们只需要一个就够了。
遍历其余的框,如果和当前最高分框的重叠面积(IOU)大于一定阈值,我们就将框删除
网上找到的MATLAB代码
%% NMS:non maximum suppression
function pick = nms(boxes,threshold,type)
% boxes: m x 5,表示有m个框,5列分别是[x1 y1 x2 y2 score]
% threshold: IOU阈值
% type:IOU阈值的定义类型
% 输入为空,则直接返回
if isempty(boxes)
pick = [];
return;
end
% 依次取出左上角和右下角坐标以及分类器得分(置信度)
x1 = boxes(:,1);
y1 = boxes(:,2);
x2 = boxes(:,3);
y2 = boxes(:,4);
s = boxes(:,5);
% 计算每一个框的面积
area = (x2-x1+1) .* (y2-y1+1);
%将得分升序排列
[vals, I] = sort(s);
%初始化
pick = s*0;
counter = 1;
% 循环直至所有框处理完成
while ~isempty(I)
last = length(I); %当前剩余框的数量
i = I(last);%选中最后一个,即得分最高的框
pick(counter) = i;
counter = counter + 1;
%计算相交面积
xx1 = max(x1(i), x1(I(1:last-1)));
yy1 = max(y1(i), y1(I(1:last-1)));
xx2 = min(x2(i), x2(I(1:last-1)));
yy2 = min(y2(i), y2(I(1:last-1)));
w = max(0.0, xx2-xx1+1);
h = max(0.0, yy2-yy1+1);
inter = w.*h;
%不同定义下的IOU
if strcmp(type,'Min')
%重叠面积与最小框面积的比值
o = inter ./ min(area(i),area(I(1:last-1)));
else
%交集/并集
o = inter ./ (area(i) + area(I(1:last-1)) - inter);
end
%保留所有重叠面积小于阈值的框,留作下次处理
I = I(find(o<=threshold));
end
pick = pick(1:(counter-1));
end
2、补丁匹配
距离测量:
Σx,y (I(x,y) - J(x,y))2

找最佳匹配
随机抽样一致算法(random sample consensus,RANSAC)
采用迭代的方式从一组包含离群的被观测数据中估算出数学模型的参数。
①考虑一个最小抽样集的势为n的模型(n为初始化模型参数所需的最小样本数)和一个样本集P,集合P的样本数#§>n,从P中随机抽取包含n个样本的P的子集S初始化模型M;
②余集SC=P\S中与模型M的误差小于某一设定阈值t的样本集以及S构成S*。S认为是内点集,它们构成S的一致集(Consensus Set);
③若#(S)≥N,认为得到正确的模型参数,并利用集S*(内点inliers)采用最小二乘等方法重新计算新的模型M*;重新随机抽取新的S,重复以上过程。
④在完成一定的抽样次数后,若未找到一致集则算法失败,否则选取抽样后得到的最大一致集判断内外点,算法结束。

伪代码的算法如下所示:(网上的)
输入:
Data 一组观测数据
Model 适应于数据的模型
n 适应于模型的最小数据个数
k 算法的迭代次数
t 用于决定数据是否适应于模型的阈值
d 判定模型是否适用于数据集的数据数目
参考链接:http://blog.csdn.net/pi9nc/article/details/26596519
Best_model 与数据最匹配的模型参数(没有返回null)
Best_consensus_set 估计出模型的数据点
Best_error 跟数据相关的估计出的模型错误
iterations = 0
best_model = null
best_consensus_set = null
best_error = 无穷大
while ( iterations < k )
maybe_inliers = 从数据集中随机选择n个点
maybe_model = 适合于maybe_inliers的模型参数
consensus_set = maybe_inliers
for ( 每个数据集中不属于maybe_inliers的点 )
if ( 如果点适合于maybe_model,且错误小于t )
将点添加到consensus_set
if ( consensus_set中的元素数目大于d )
已经找到了好的模型,现在测试该模型到底有多好
better_model = 适合于consensus_set中所有点的模型参数
this_error = better_model究竟如何适合这些点的度量
if ( this_error < best_error )
我们发现了比以前好的模型,保存该模型直到更好的模型出现
best_model = better_model
best_consensus_set = consensus_set
best_error = this_error
增加迭代次数
返回 best_model, best_consensus_set, best_error
SIFT算法详解
https://blog.csdn.net/zddblog/article/details/7521424
