目录
研究生阶段入手的就是attention mechanism,一直想沉下心来认真的总结一下。
想来想去,标题借用了Google在2017年提出Transformer模型论文所用的标题,该论文使用的self-attention在NLP界大放异彩,最近,ICLR2020中一篇论文“On the Relationship between Self-Attention and Convolutional Layers”获得6-6-6的高分(https://arxiv.org/abs/1911.03584),该论文提出self-attention能代替CNN表达任何卷积滤波层,证明了CNN所提取的特征,self-attention层同样能做到。同时,CVPR2020中Google的DeepMind团队“Towards Robust Image Classification Using Sequential Attention Models”利用attention mechanism将图片分类的指标再度提升(https://arxiv.org/pdf/1912.02184)(论文解析https://blog.csdn.net/hesongzefairy/article/details/104917032),可以预见Attention Mechanism热度将再次推向高峰。
我就顺着时间线,探究一下现在NLP和CV处理连续帧时依然常用的两种注意机制,soft attention和self attention,还有很多其他的注意机制其实是这两种的变种,弄懂其中的原理,理解了attention的本质,则一通百通。
什么是注意机制?
说到注意机制,宏观上理解,无论是理论上什么样的注意机制,靠代码怎么编写实现的注意机制,本质上都是想要模拟人类的选择性注意机制,当一幅图出现在人的面前,人眼扫视一遍后会排除无关的信息,大脑会将目光集中在图中一个感兴趣的区域上以获取更多感兴趣区域的信息,所以归根结底,学者们提出注意机制的目的就是为了让模型学会人类选择性注意机制这种抑制无用信息,最大程度获取且保留有用信息的能力。
注意机制广泛应用的起点在哪?
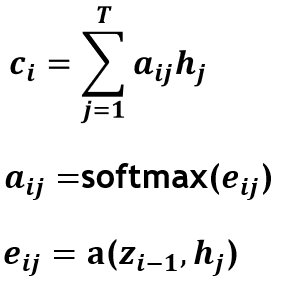
如果理解过注意机制,对这三个公式应该不陌生,这就是我们常说的soft attention,看不懂也不要紧,后面慢慢讲。2015年针对机器翻译任务,Bahdanau在论文“Neural Machine Translation by Jointly Learning to Align and Translate”提出了一种encoder-decoder的结构并采用了这种注意机制,为后面NLP的快速发展奠定了基础,tensorflow中有这个模型的封装(BahdanauAttention)能够直接调用,可见其经典程度,2016年Luo在Bahdanau的global attention基础上提出local attention进一步推进注意机制在NLP中的统治力“Effective Approaches to Attention-based Neural Machine Translation”,tensorflow中同样封装了这个模型(LuongAttention)。有了这样的基础,之后无论是NLP领域还是CV领域,注意机制的应用开始万花齐放,有了诸如Image caption、机器问答VQA之类非常有意思的分支。
附tensorflow中的调用:(具体用法可参见tensorflow官方文档)
-
tf.contrib.seq2seq.BahdanauAttention()
-
tf.contrib.seq2seq.LuongAttention()
经典Seq2Seq模型(encoder-decoder)
简化版本的seq2seq模型如下图:

假设输入句子“I am a student”,encoder层通过LSTM将其编码成一个向量c,decoder层将向量c解码成输出句子,这就是一个简单的encoder-decoder模型。
那么可以思考一下,编码向量c中其实包含了输入句子的所有信息,每个时间步模型都根据上一次的预测词和c来预测当前时间步的输出词,公式表示如下:
output("我") = LSTM(c)
output("是") = LSTM(c,“我”)
output("一个") = LSTM(c,“我”,“是”)
output("学生") = LSTM(c,“我”,“是”,“一个”)
可以看出,预测每一个输出,都需要根据编码向量c和之前时间步上的预测输出,值得思考的是,输出“学生”的时候,模型真的需要c中的所有信息吗,其实最关键的是c中只要包含“student"这个信息预测正确的概率就非常大,此时c中除了“student”以外的信息其实都是不重要或者是干扰信息,那么如何抑制c中的无关信息?这就轮到Attention Mechanism出场。
为什么需要Attention Mechanism?
在经典的encoder-decoder模型中,编码向量c被作为输入重复使用,然后在后续时间步中,得到正确的输出并不需要c中的所有信息,将Attention Mechanism加入进来,就能帮助模型筛选信息,就如人类的选择性注意机制一样,输出“学生”时只需要编码向量c中包含“student”即可,模型变化如下:

编码向量c通过注意机制的筛选之后,decode解码层每个时间步的输入就相应改变:
output("我") = LSTM(c1)
output("是") = LSTM(c2,“我”)
output("一个") = LSTM(c3,“我”,“是”)
output("学生") = LSTM(c4,“我”,“是”,“一个”)
可以看出加入注意机制之后,整个模型变得灵活了,输入不再固定为一个编码向量c,c中的冗余信息得到有效抑制。
Soft Attention计算过程
上述就是Bahdanau在论文“Neural Machine Translation by Jointly Learning to Align and Translate”采用的注意机制,也称为soft attention,上一节只是从宏观层面介绍了为什么要引入注意机制,以及注意机制的作用是什么,这节就来具体分析注意机制到底是如何计算的。
之前已经展示过了三个公式,那三个公式就是soft attention的核心,用说人话的方式来说就是三个步骤:计算相似度、计算注意权重、加权求和,接下来还是通过图来具体分析:
以输出“是”这一时刻为例:

第一步:计算相似度
由上一时刻的状态和编码后的四个向量
分别计算相似度Similarity,具体计算方式有多种:
点积:
cosine:
MLP网络:
第二步:计算attention weight
将第一步算出的四个值通过softmax归一化成概率值,softmax的公式相信大家都了解
得到的概率值可以理解成对的保留程度,此时以输出“是”举例,故对h2的保留程度最大为0.8
第三步:加权求和
计算0.1*h1+0.8*h2+0.05*h3+0.05*h4,就能得到经过注意机制筛选之后的新编码向量c2
以上就是soft attention(BahdanauAttention)的思想和计算全过程,那么如何理解Attention模型的物理含义?一般在NLP中里会把Attention模型看作是输出句子中某个单词和输入句子每个单词的对齐模型(Align model)。目标句子生成的每个单词对应输入句子单词的概率分布可以理解为输入句子单词和这个目标生成单词的对齐概率,这在机器翻译语境下是非常直观的:传统的统计机器翻译一般在做的过程中会专门有一个短语对齐的步骤,而注意机制与之是相同的作用。
Attention Mechanism的本质
通过之前几个小节的介绍,对于soft attention的思想应该有很清晰的理解了,现在将整个Attention Mechanism从Seq2Seq这个情景下抽离出来,其本质到底是什么?只有弄清楚了本质,才能将注意机制的方法应用到更多领域中。
我们先假设这样一种情况:
在你面前有四个小盒子,盒子上分别有标签“苹果”、“橙子”、“梨”、“车厘子”,此时你想吃车厘子,怎么办?
当然是找标签是“车厘子”的盒子,打开盒子开吃
现在细化一下这个过程,当你脑海中浮现想吃车厘子的想法,首先你的目光扫视一遍桌上的四个盒子,通过比对四个盒子的标签,发现其中一个盒子标签为”车厘子“和想法吻合,于是目光集中到这个车厘子的盒子,准备开吃。
这个例子就是注意机制的思想,再抽象一点,结合计算机中的知识,四个盒子看作四个<key, value>键值对,四个key就是“苹果”、“橙子”、“梨”、“车厘子”,value就是四个盒子里面装的东西,此时脑海中的想法是想吃车厘子,于是获得一个query车厘子,我们就使用这个query和四个key一个一个对比,直到发现query=key的时候,我们取出key对应的value,达成目的。
理解了这个例子,就理解了Attention Mechanism的本质,本质就是通过query和key分别比较,找到和query相似度最高的那个key,目的就是获取这个key对应的value,公式表达如下:
但是这个例子中的注意机制其实比较hard,满足条件query=key才行,那么当我们想法是“最想吃车厘子,其他的也能尝一口”,这样是不是就soft了起来,通过计算query和key相似度,我们最后可能吃了好多车厘子同时也把苹果、橙子、梨也咬了一口。
有了这样的理解之后,再回到seq2seq的模型中,对于那三个公式是不是有了更深刻的理解,,四个键值对
,分别计算了query和四个keyh1、h2、h3、h4的相似度,softmax计算出四个概率值,最后加权求和得到输出。

其实也有不少人将Attention机制看作一种软寻址(Soft Addressing):看作存储器内存储的内容,每个内容由地址Key和值Value组成,当前有个Key=Query的查询,目的是取出存储器中对应的Value值,即Attention数值。通过Query和存储器内元素Key的地址进行相似性比较来寻址,之所以说是软寻址,指的不像一般寻址只从存储内容里面找出一条内容,而是可能从每个Key地址都会取出内容,取出内容的重要性根据Query和Key的相似性来决定,之后对Value进行加权求和,这样就可以取出最终的Value值,也即Attention值。
代码实现:
import tensorflow as tf
import numpy as np
def attention(input):
# input: [batch_size,time_step,dimension]
input_shape = input.shape.as_list()
time_step,hidden_size = input_shape[1], input_shape[2]
#定义query
query = tf.Variable(tf.truncated_normal(shape=[hidden_size, 1], stddev=0.5, dtype=tf.float32))
#定义W 使input维度和query相同
W = tf.Variable(tf.truncated_normal(shape=[hidden_size, hidden_size], stddev=0.5, dtype=tf.float32))
score = tf.matmul(tf.matmul(tf.reshape(input, [-1,hidden_size]), W), query) # score: [batch_size*time_step,1] 点乘计算相似度
score = tf.reshape(score,[-1,time_step,1])# score: [batch_size,time_step,1]
alpha = tf.nn.softmax(score, axis=1) # alpha: [batch_size,time_step,1]
# 矩阵相乘包含了公式中的求和部分
c_t = tf.matmul(tf.transpose(input, [0, 2, 1]), alpha)
return tf.tanh(c_t)
