
词法分析器
简介:
|| 词法分析流程:
读取字符流,,并应用一组规则来判断每个单词在源语言中是否合法,如果单词判断为有效,则会给它分配一个词类,将其聚合形成单词流。
|| 手工编写的词法分析器因为避免了很多不必要的开销,故比生成的词法分析器,带来极大的性能优势的好处,往往超出了自动生成语法分析器的便利性带来的好处
|| 程序设计语言的词法结构(微语法):规定了如何将字符组合为单词
(注意:语法是对单词进行分类,组成句子)
|| 什么是有效标识符:大部分语言中标识符为 始于一个字母字符,后接上0个或多个字母/数字字符,结束于第一个非字母或数字的字符
eg:有效的标识符:dd55d88dd,fffff。无效的标识符:12fff
|| 关键字(保留字):有特殊含义的有效标识符,词法分析器会自动将其归类到另一个语法范畴中去 eg:static,while,if
|| 对于识别一个单词的FA来说,单词对应的实际文本称为*“词素”*
识别单词
|| 识别器的转移图:每个圆圈都代表计算中的一个抽象状态
s0是初始状态,s5是接受状态(以双层圆圈绘制),通常神略目标为错误状态的转移
以下为关键字“while”的识别示例:

以下为new和not的识别器:
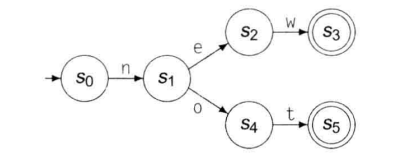
合并识别器:

|| 识别器的形式化: 有限自动机
(对于一个识别器(识别单词程序),我们将其转换图用五元组进行数学表示,则称该五元组为有限自动机,描述了识别器的规格)
完整解释:对于需要实现转移图的代码,转移图就是这些代码的抽象。我们将这些转移图看作形式化的数学对象时,称其为有限自动机(FA),它定义了识别器的规格。在形式上有限状态机是一个五元组(S, Σ, δ, s0,SA),各分量的含义如下:
- S是识别器中的有限状态集,以及一个错误状态se
- Σ是识别器使用的有限字母表。通常,Σ即转移图中边的标签合集
- δ(s,c)是识别器的转移函数,它将每个状态的s∈S和每个字符每个字符c∈Σ的组合(s, c)映射到下一个状态。例如在状态si遇到输入字符c,FA将采用转移si —> δ(si, c)
- s0 是S中指定的起始状态
- SA 是S中的接受状态集合
因此上面转化图的FA形式如下:

|| 因此FA接受字符串s = x1x2x3, …, xn的充要条件为:
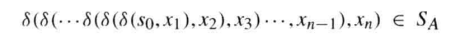
|| 注意事项:
- 对于FA有两种错误:
第一种是词法错误,某个字符将FA庄转移到了错误状态se
第二种是前缀问题,FA耗尽了输出流(即遍历了字符串所有字符后),停留在了se之外的非接受状态。(这说明是前缀) - FA对于每个输入字符都会进行一次状态转移,直至耗尽输入流,因此高效实现的FA,识别器的运行时间于输入字符串的长度成正比
|| 识别一类单词的FA:有环转移图的形式化
以下为所有正整数的识别器转移图:
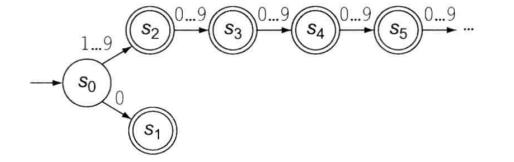
以下为其有环简化:
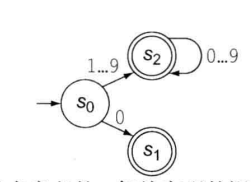
由上图可以看出,该识别器可以识别一类字符串(无符号整数),因此这个FA是在语法范畴上(识别出一个词类)进行识别。
|| 表示一类的FA,其分量δ可以用表格来高效定义:

正则表达式
|| 正则语言的定义:
在有限自动机FA中所接受的单词的集合,形成了一种语言。我们还可以用正则表达式(RE)的符号表示法来更简洁地表述该语言。通过RE描述的语言叫做正则语言
|| 正则表达式基本的语法规则


|| 优先级:括号>求补>闭包>连接>选择
|| 一些特殊的闭包

|| 小插话:
- 很多语言中的通配符 --”*“,其实就是RE Σ*的简写
- 字符串的RE: “(^ ") *”
注释的RE: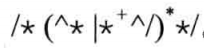 或者
或者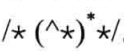
从正则表达式到词法分析器
|| 区分非确定性FA和确定性FA
NFA(非确定性有限自动机):允许在空串∈(RE空集)转移的FA
DFA(确定性有限自动机):不允许在空串∈(RE空集)转移的FA
|| 空串∈转移在RE转换为FA时的作用:
在RE转换为FA时,空串的作用就是生成∈转移,合并两个FA。
这样一来在某一阶段中,状态有多种转换的路径,因此在状态转移的每一步都需要检查当前字符(隐含上下文),背离了顺序算法的行为观念
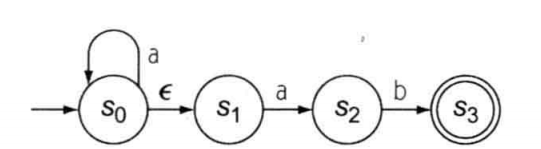
|| NFA的工作模型:(工作原理)
每次NFA必须进行非确定性选择时,NFA都会克隆自身,以追踪每个可能的转移。因此对于一个输入的字符来说,其NFA其实时一个特定的状态集合,每个状态都由某个克隆来匹配。
NFA进行非确定性选择时,并发活动状态下克隆出来的集合称为NFA的配置。
当NFA到达一个配置,此时已经耗尽了输出流,且有一个或者多个克隆的副本处于某个接收状态,则NFA接受(识别)该字符串
|| DFA与NFA之间的关系
- 等价性:两者在表现上等价,任何的DFA都是NFA的一个特例
- 包含性:NFA其实是有限个的配置,一个NFA可能有很多很多个等价的DFA
|| 我们将使用如下构造法,以便将RE转换为适合于直接实现的FA

|| 从正则表达式到NFA的构造法:Thompson构造法
Thompson构造法的本质:1,构建了对应于单字母RE的NFA 2,使用NFA上的∈转换,模拟连接RE选择闭包等操作

|| Thompson构造法的代码实现:
构造一棵树,以表示内部的优先级,使用后序遍历

|| 从NFA到DFA:子集构造法
|| 目的NFA(N, Σ, δN, n0,NA)为输入,生成一个DFA(D, Σ, δD, d0,DA)
|| 流程
首先:运行构造法,构造出一个目标DFA的模型

然后:如果qi包含NFA某个接收状态,即说明表示它的状态di是DFA的接收状态之一。通过qi到di的映射,获得转移函数。最后通过构造函数q0成为di,获得DFA的初始状态
|| 不动点算法。(子集构造法是不动点计算的一个例子)
该算法的特点是:对某个结构已知的域中的集群,重复运用一个单调函数。当计算达到某一状态时,如果进一步的迭代之得出已有的结果,则计算终止。相当于在连续的迭代空间中触碰到了一个"不动点"。
|| 离线计算 ∈-closure

ps:具有问题完全信息前提下(即所有输入数据已知) 设计出的算法称为离线算法( off line algorithms)
|| 从DFA到最小DFA:Hopcroft算法
为了减少识别器在内存中占用的空间,即通过减少计算机访问内存的耗时,增加计算速度
|| 算法的核心其实就是检测两个状态是否是等价的:

|| 为了解决RE重义问题,需要给RE分配优先级
实现词法分析器
