一:网络爬虫设计方案
爬虫名称:分析小说长度对阅读者的影响
设计方案概述:
1.找到要爬取的网页,使用F12查看源代码,找到我们要爬取的数据
2.使用get请求和beautifulsoup解析工具进行爬取数据
3.使用pandas进行数据可视化
4.使用matplotlib进行数据分析以及回归方程的绘制
5.最后将数据持久化
技术难点:找到对应数据之间的线性关系,爬取有用的数据,将有碍分析的数据剔除
二:页面的结构分析:
打开所要爬取的网页:https://mbook.km.com/rank-wanben.html
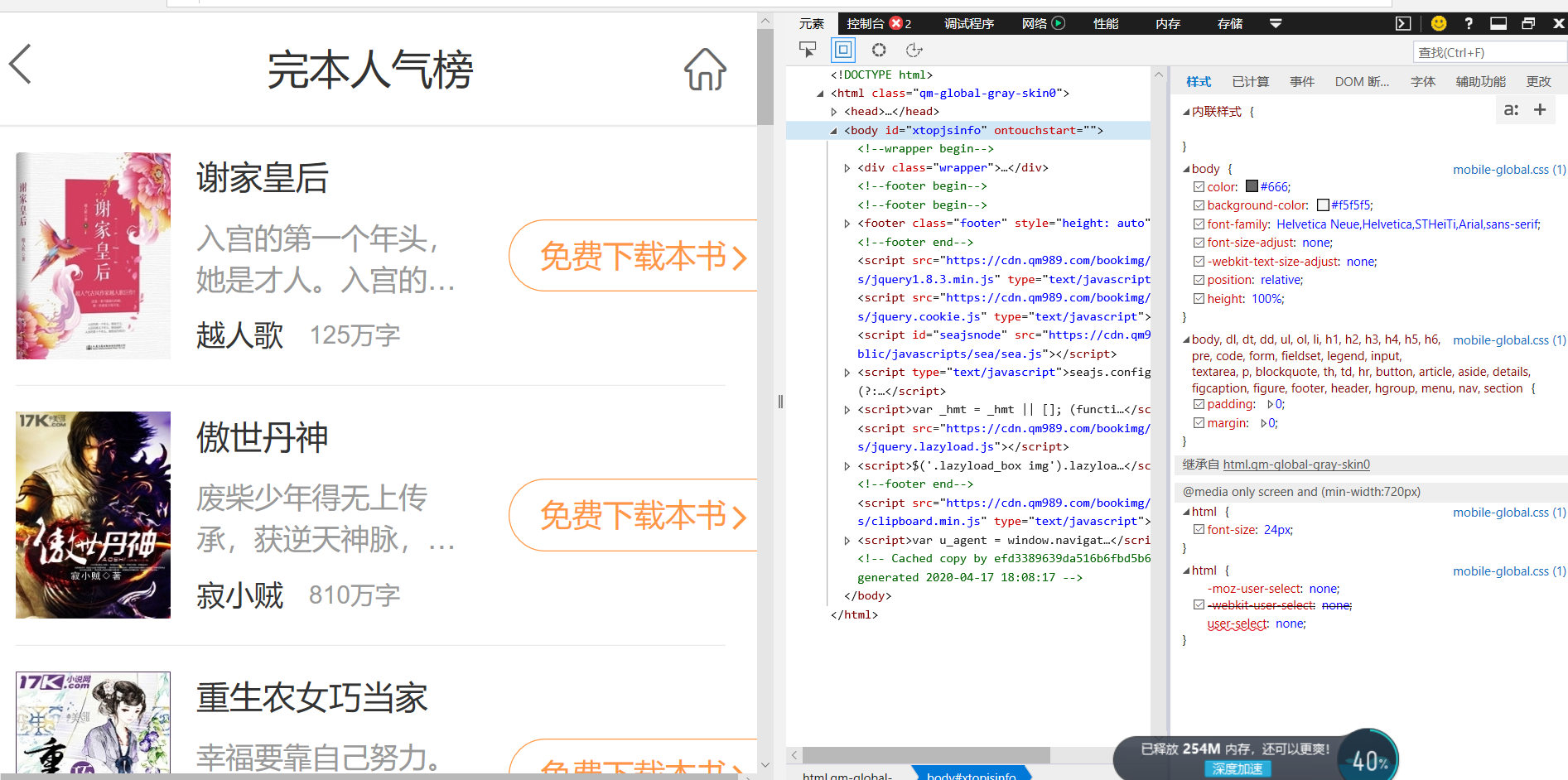
3.于是我们便可以利用find_all函数进行遍历查找的方式爬取
三:爬虫程序设计
先把我们所需要的信息爬取下来
import pandas as pd
import numpy as np
import scipy as sp
from numpy import genfromtxt
import matplotlib
from pandas import DataFrame
import matplotlib.pyplot as plt
from scipy.optimize import leastsq
import urllib.request as urlrequest
#导入相关库
url='https://mbook.km.com/rank-wanben.html'
#搜索网址
headers={'User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.18363'}#伪装爬虫
#伪装爬虫
r=requests.get(url)
#发送get请求
r.encoding=r.apparent_encoding
#统一编码
t=r.text
soup=BeautifulSoup(t,'lxml')
#使用BeautifulSoup工具解析
title=[]
count=[]
#建立两个空列表
for x in soup.find_all(class_="title"):
title.append(x.get_text().strip())
for y in soup.find_all('span',class_="num"):
count.append(y.get_text().strip())
#使用find_all函数进行遍历查找
data=[title,count]
#把两个列表收到data变量中
print(data)
#使用print函数打印

接下来进行数据可视化保存为csv文件
df=pd.DataFrame(data,index=["小说",'字数'])
2 #数据可视化
3 df.to_csv('精品小说.csv')
4 #读取csv文件
5 df = pd.DataFrame(pd.read_csv('精品小说.csv'))
6 #print(df)
7 df.head()

进行数据清洗

接下来进行数据分析和可视化
#进行数据可视化
#正常显示中文
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
plt.rcParams['axes.unicode_minus']=False
#创建画布
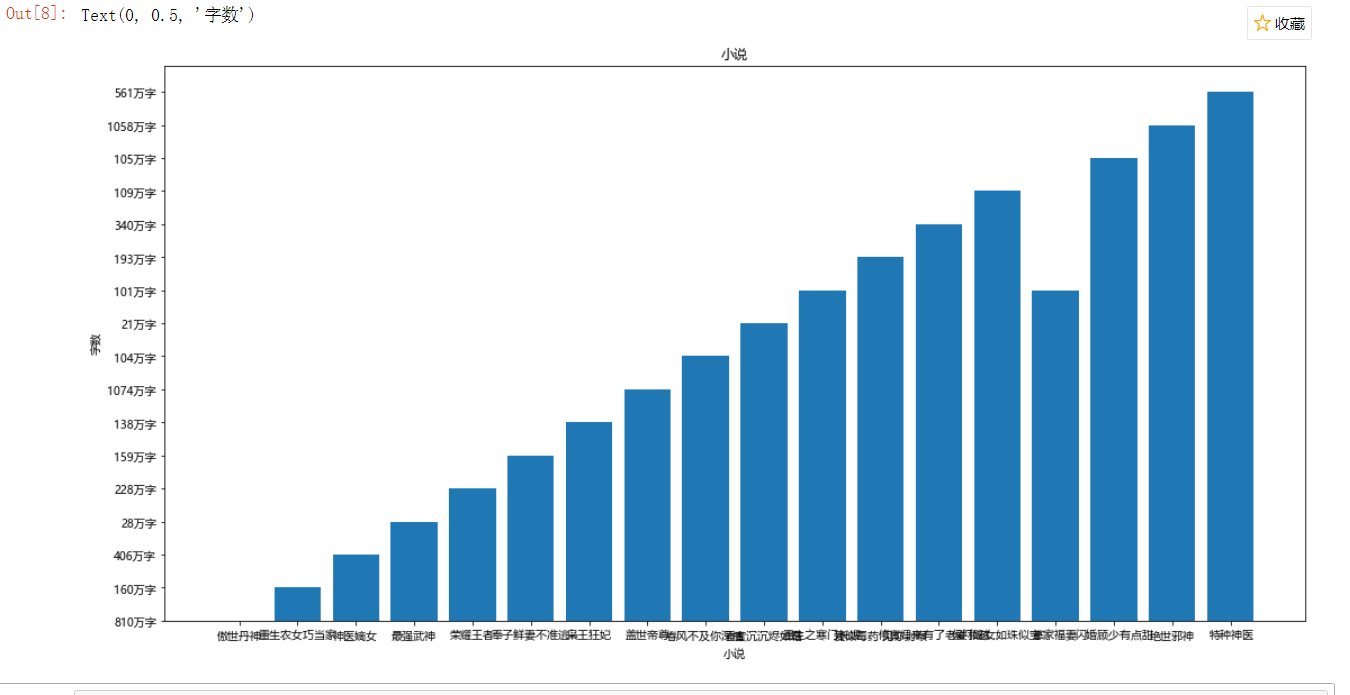
plt.figure(figsize=(40,20))#设置画布大小
#绘制子图1
axes1=plt.subplot(2,2,4)
X=data2.loc[:,'小说']
Y=data2.loc[:,'字数']
#绘制柱状图
plt.bar(X,Y)
plt.title('小说')
plt.xlabel('小说')
plt.ylabel('字数')
接下来画散点图和回归直线方程
#画一元二次回归方程
chinese=matplotlib.font_manager.FontProperties(fname='C:/精品小说')
#调用中文
plt.rcParams['font.sans-serif']=['Arial Unicode MS']
plt.rcParams['axes.unicode_minus']=False
filename="D:/hotbo.xlsx"
colnames=["rank","name","hot"]
df=pd.read_excel(filename,skiprows=1,names=colnames)
X=df.rank
Y=df.hot
#确定x,y轴
def func(params,x):
a,b,c=params
return a*x*x+b*x+c
def error(params,x,y):
#设置误差函数
return func(params,x)-y
p0=[1978,0]
def main():
#主函数
plt.figure(figsize=(8,6))
#画布尺寸
p0=[1978,300,1]
Para=leastsq(error,p0,args=(X,Y))
a,b,c=Para[0]
print("a=",a,"b=",b,"c=",c)
plt.scatter(X,Y,color="green",label="样本数据",linewidth=2)
x=np.linspace(1,25,25)
y=a*x*x+b*x+c
plt.plot(x,y,color="red",label="拟合曲线",linewidth=2)
#画拟合曲线
plt.legend()
plt.title("小说名称与长度")
plt.grid()
plt.show()
main()
完整的代码如下:
import pandas as pd
import numpy as np
import scipy as sp
from numpy import genfromtxt
import matplotlib
from pandas import DataFrame
import matplotlib.pyplot as plt
from scipy.optimize import leastsq
import urllib.request as urlrequest
#导入相关库
url='https://mbook.km.com/rank-wanben.html'
#搜索网址
headers={'User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.18363'}#伪装爬虫
#伪装爬虫
r=requests.get(url)
#发送get请求
r.encoding=r.apparent_encoding
#统一编码
t=r.text
soup=BeautifulSoup(t,'lxml')
#使用BeautifulSoup工具解析
title=[]
count=[]
#建立两个空列表
for x in soup.find_all(class_="title"):
title.append(x.get_text().strip())
for y in soup.find_all('span',class_="num"):
count.append(y.get_text().strip())
#使用find_all函数进行遍历查找
data=[title,count]
#把两个列表收到data变量中
print(data)
#使用print函数打印
df=pd.DataFrame(data,index=["小说","字数"])
#数据可视化
print(df.T)
df=pd.DataFrame(data,index=["小说",'字数'])
#数据可视化
df.to_csv('精品小说.csv')
#数据清洗
print('\n====各列是否有缺失值情况如下:====')
print(df.isnull())
#统计空值情况
print(df.duplicated())
#查找重复值
print(df.isna().head())
#统计缺失值 # 得出结果为False则不为空值
print(df.describe())
#描述数据
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
plt.rcParams['axes.unicode_minus']=False
#创建画布
plt.figure(figsize=(40,20))#设置画布大小
#绘制子图1
axes1=plt.subplot(2,2,4)
X=data2.loc[:,'小说']
Y=data2.loc[:,'字数']
#绘制柱状图
plt.bar(X,Y)
plt.title('小说')
plt.xlabel('小说')
plt.ylabel('字数')
#画一元二次回归方程
chinese=matplotlib.font_manager.FontProperties(fname='C:/精品小说')
#调用中文
plt.rcParams['font.sans-serif']=['Arial Unicode MS']
plt.rcParams['axes.unicode_minus']=False
filename="D:/hotbo.xlsx"
colnames=["rank","name","hot"]
df=pd.read_excel(filename,skiprows=1,names=colnames)
X=df.rank
Y=df.hot
#确定x,y轴
def func(params,x):
a,b,c=params
return a*x*x+b*x+c
def error(params,x,y):
#设置误差函数
return func(params,x)-y
p0=[1978,0]
def main():
#主函数
plt.figure(figsize=(8,6))
#画布尺寸
p0=[1978,300,1]
Para=leastsq(error,p0,args=(X,Y))
a,b,c=Para[0]
print("a=",a,"b=",b,"c=",c)
plt.scatter(X,Y,color="green",label="样本数据",linewidth=2)
x=np.linspace(1,25,25)
y=a*x*x+b*x+c
plt.plot(x,y,color="red",label="拟合曲线",linewidth=2)
#画拟合曲线
plt.legend()
plt.title("小说名称与长度")
plt.grid()
plt.show()
main()