一、张量操作
1.张量的拼接—cat()与stack()函数
函数原型:
torch.cat(tensors, => 张量序列
dim = 0, => 要拼接的维度
out = None)torch.stack(tensors, => 张量序列
dim = 0, => 要拼接的维度
out = None)区别:
cat() : 在原维度上拼接
stack():创建新的维度代码举例:
import torch
a = torch.randint(1, 3, [2, 3])
b = torch.randint(1, 3, (2, 3))
print("a = {0}, shape = {1}\nb = {2}, shape = {3}".format(a, a.shape, b, b.shape))
c = torch.cat([a, b], dim=1)
d = torch.stack((a, b), dim=1)
print("c = {0}, shape = {1}\nd = {2}, shape = {3}".format(c, c.shape, d, d.shape))运行结果:
a = tensor([[1, 1, 2],
[1, 1, 2]]), shape = torch.Size([2, 3])
b = tensor([[1, 2, 1],
[2, 1, 2]]), shape = torch.Size([2, 3])
c = tensor([[1, 1, 2, 1, 2, 1],
[1, 1, 2, 2, 1, 2]]), shape = torch.Size([2, 6])
d = tensor([[[1, 1, 2],
[1, 2, 1]],
[[1, 1, 2],
[2, 1, 2]]]), shape = torch.Size([2, 2, 3])
2.张量的切分—chunk()和split()函数
函数原型:
torch.chunk(input, => 输入的张量
chunks, => 份数
dim = 0) => 维度
功能:将张量按照维度dim进行平均切分成chunks份。
返回值:张量列表。
注:如果不能平均切分,最后一份会小于其他张量。torch.split(input, => 输入的张量
split_size_or_sections, => 为int时,表示每份的长度;
为list时,按照list切分该维张量
di = 0) => 维度区别:
split()函数比chunk()函数更加灵活,要根据具体需要选择合适函数。代码举例:
import torch
a = torch.randint(1, 3, (2, 7))
tensors = torch.chunk(a, chunks=3, dim=1)
for idx, tensor in enumerate(tensors):
print("第{0}个张量 = {1}, shape = {2}".format(idx+1, tensor, tensor.shape))
tensors = torch.split(a, 2, dim=1)
for idx, tensor in enumerate(tensors):
print("第{0}个张量 = {1}, shape = {2}".format(idx+1, tensor, tensor.shape))
tensors = torch.split(a, [1, 1, 5], dim=1)
for idx, tensor in enumerate(tensors):
print("第{0}个张量 = {1}, shape = {2}".format(idx+1, tensor, tensor.shape))运行结果
第1个张量 = tensor([[2, 1, 1],
[1, 2, 2]]), shape = torch.Size([2, 3])
第2个张量 = tensor([[1, 1, 1],
[1, 2, 2]]), shape = torch.Size([2, 3])
第3个张量 = tensor([[2],
[1]]), shape = torch.Size([2, 1])第1个张量 = tensor([[2, 1],
[1, 2]]), shape = torch.Size([2, 2])
第2个张量 = tensor([[1, 1],
[2, 1]]), shape = torch.Size([2, 2])
第3个张量 = tensor([[1, 1],
[2, 2]]), shape = torch.Size([2, 2])
第4个张量 = tensor([[2],
[1]]), shape = torch.Size([2, 1])第1个张量 = tensor([[2],
[1]]), shape = torch.Size([2, 1])
第2个张量 = tensor([[1],
[2]]), shape = torch.Size([2, 1])
第3个张量 = tensor([[1, 1, 1, 1, 2],
[2, 1, 2, 2, 1]]), shape = torch.Size([2, 5])
3.张量的索引—index_select()和mask_select()函数
函数原型
torch.index_select(input, => 待索引的张量
dim, => 待索引的维度
index, => 待索引数据的序号
out = None)
返回值:一维或高维张量torch.masked_select(input, => 待索引的张量
mask, => 与input同形状的布尔类型张量
out = None)
返回值 : 一维张量区别
返回值的维度一般不同。代码举例
import torch
a = torch.randint(1, 10, (3, 3))
print("a = {0}, shape = {1}".format(a, a.shape))
idx = torch.tensor([0, 2], dtype=torch.long) # 注意是long类型!!!
index_select = torch.index_select(a, index=idx, dim=0)
print("index_select = {0}, shape = {1}".format(index_select, index_select.shape))
mask = a.ge(5) # ge:大于等于 gt:大于 le:小于等于 lt:小于
mask_select = torch.masked_select(a, mask)
print("mask = {0}\nmasked_select = {1}, shape = {2}".format(mask, mask_select, mask_select.shape))运行结果
a = tensor([[1, 6, 9],
[3, 3, 5],
[7, 9, 7]]), shape = torch.Size([3, 3])
index_select = tensor([[1, 6, 9],
[7, 9, 7]]), shape = torch.Size([2, 3])
mask = tensor([[False, True, True],
[False, False, True],
[ True, True, True]])
masked_select = tensor([6, 9, 5, 7, 9, 7]), shape = torch.Size([6])4.张量的变换—reshape() 和 transpose() 和 squeeze()函数
函数原型
torch.reshape(input, => 待变换的张量
shape) => 新张量的形状
注:当张量在内存中连续时,新张量与input共享数据内存torch.transpose(input, => 待变换的张量
dim0, => 待变换的维度
dim1) => 待变换的维度
注:torch,t() : 用于二位张量转置; 对于矩阵而言,等价于torch.transpose(input, 0, 1)torch.squeeze(input, => 待变换的维度
dim = None, => 为None时,移除所有长度为1的轴;
为指定维度时,当该轴为1时,移除该轴。
out = None)应用举例&运行结果:
torch.reshape()
import torch
a = torch.randperm(10)
reshape = torch.reshape(a, (2, 5)) # (-1, 5)
print("a = {0}\nres = {1}".format(a, reshape))
a[0] = 999
print("a = {0}, 内存地址 = {1}\nrsp = {2}, 内存地址 = {3}".format(a, id(a), reshape, id(reshape)))a = tensor([0, 6, 2, 5, 7, 1, 4, 3, 9, 8])
res = tensor([[0, 6, 2, 5, 7],
[1, 4, 3, 9, 8]])
a = tensor([999, 6, 2, 5, 7, 1, 4, 3, 9, 8]), 内存地址 = 2501396614904
rsp = tensor([[999, 6, 2, 5, 7],
[ 1, 4, 3, 9, 8]]), 内存地址 = 2501396612744 # #二者的内存地址相同torch.transpose()
import torch
a = torch.randint(1, 10, (2, 2, 3))
b = torch.transpose(a, dim0=1, dim1=2)
print("a.shape = {0}\nb.shape = {1}".format(a.shape, b.shape))a.shape = torch.Size([2, 2, 3])
b.shape = torch.Size([2, 3, 2])torch.squeeze()
import torch
a = torch.rand((1, 2, 3, 1, 2))
b = torch.squeeze(a)
c = torch.squeeze(a, dim=0)
d = torch.squeeze(a, dim=1)
print("a.shape = {0}\nb.shape = {1}\nc.shape = {2}\nd.shape = {3}".format(a.shape, b.shape, c.shape, d.shape))a.shape = torch.Size([1, 2, 3, 1, 2])
b.shape = torch.Size([2, 3, 2])
c.shape = torch.Size([2, 3, 1, 2])
d.shape = torch.Size([1, 2, 3, 1, 2]) # 不变5.张量的数学运算
函数:
加减乘除:add addcdiv addcmul sub div mul
三角函数:abs acos cosh cos asin atan atan2
对数、指数、幂函数:log log10 log2 exp pow
部分原型:
torch.add(input, => 第一个张量
alpha = 1, => 乘项因子
other, => 第二个张量
out = None)
输出:output = input + alpha*othertorch.addcmul(input,
value = 1,
tensor1,
tensor2,
out = None)
输出:output = input + value*(tensor1/tensor2)二、线性回归实战
基于均方差
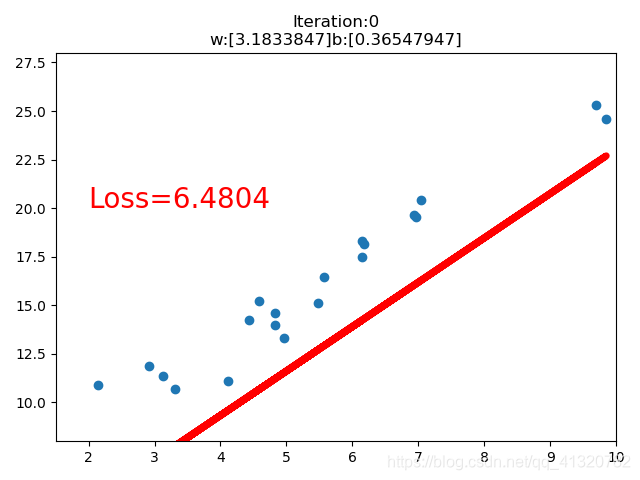
import torch
import matplotlib.pyplot as plt
torch.manual_seed(10)
lr = 0.05
# 创建数据
x = torch.rand(20, 1) * 10
y = 2 * x + (5 + torch.randn(20, 1))
# 创建线性回归参数
w = torch.randn((1), requires_grad=True)
b = torch.randn((1), requires_grad=True)
for iteration in range(1000):
# 前向传播
wx = torch.mul(w, x)
y_pred = torch.add(wx, b)
# 计算MSE loss
loss = (0.5 * (y-y_pred)**2).mean()
# 反向传播
loss.backward()
# 更新参数
b.data.sub_(lr*b.grad)
w.data.sub_(lr*w.grad)
# 清除张量的梯度
w.grad.zero_()
b.grad.zero_()
# 绘图
if iteration%20 == 0:
plt.scatter(x.data.numpy(), y.data.numpy())
plt.plot(x.data.numpy(), y_pred.data.numpy(), 'r-', lw=5)
plt.text(2, 20, 'Loss=%.4f'%loss.data.numpy(), fontdict={'size':20, 'color':'red'})
plt.xlim(1.5, 10)
plt.ylim(8, 28)
plt.title("Iteration:{}\nw:{}b:{}".format(iteration, w.data.numpy(), b.data.numpy()))
plt.pause(0.5)
if loss.data.numpy() < 1:
break