2020-04-16
github
https://github.com/MorvanZhou/tutorials/tree/master/sklearnTUT
视频教程bilibili
https://www.bilibili.com/video/BV1xW411Y7Qd?p=1
sk4_learning_pattern
用knn做Iris花,划分了train和test


from sklearn import datasets from sklearn.model_selection import train_test_split from sklearn.neighbors import KNeighborsClassifier iris = datasets.load_iris() iris_X = iris.data iris_y = iris.target ##print(iris_X[:2, :]) ##print(iris_y) X_train, X_test, y_train, y_test = train_test_split( iris_X, iris_y, test_size=0.3) ##print(y_train) knn = KNeighborsClassifier() knn.fit(X_train, y_train) print(knn.predict(X_test)) print(y_test)
sk5_datasets
用线性回归预测Boston房评,并可视化
from sklearn import datasets from sklearn.linear_model import LinearRegression import matplotlib.pyplot as plt loaded_data = datasets.load_boston() data_X = loaded_data.data data_y = loaded_data.target model = LinearRegression() model.fit(data_X, data_y) print(model.predict(data_X[:4, :])) print(data_y[:4]) X, y = datasets.make_regression(n_samples=100, n_features=1, n_targets=1, noise=10) plt.scatter(X, y) plt.show()
sk6_model_attribute_method
用线性回归预测Boston房评,输出特定参数,例子y=0.1x+0.3
print(model.coef_)#coefficient为0.1(系数) print(model.intercept_)#intercept为0.3(截距) print(model.get_params())#自己定义的参数,如{'copy_X': True, 'fit_intercept': True, 'n_jobs': None, 'normalize': False} print(model.score(data_X, data_y))# R^2 coefficient of determination R^2可决系数
from sklearn import datasets from sklearn.linear_model import LinearRegression loaded_data = datasets.load_boston() data_X = loaded_data.data data_y = loaded_data.target model = LinearRegression() model.fit(data_X, data_y) print(model.predict(data_X[:4, :])) print(model.coef_) print(model.intercept_) print(model.get_params()) print(model.score(data_X, data_y)) # R^2 coefficient of determination
[30.00384338 25.02556238 30.56759672 28.60703649] [-1.08011358e-01 4.64204584e-02 2.05586264e-02 2.68673382e+00 -1.77666112e+01 3.80986521e+00 6.92224640e-04 -1.47556685e+00 3.06049479e-01 -1.23345939e-02 -9.52747232e-01 9.31168327e-03 -5.24758378e-01] 36.459488385090125 {'copy_X': True, 'fit_intercept': True, 'n_jobs': None, 'normalize': False} 0.7406426641094095
sk7_normalization
用numpy写一个array并归一化。用make_classification创造一些例子,用SVM分类,计算有无归一化的score情况。
from sklearn import preprocessing import numpy as np from sklearn.model_selection import train_test_split from sklearn.datasets.samples_generator import make_classification from sklearn.svm import SVC import matplotlib.pyplot as plt a = np.array([[10, 2.7, 3.6], [-100, 5, -2], [120, 20, 40]], dtype=np.float64) print(a) print(preprocessing.scale(a)) X, y = make_classification(n_samples=300, n_features=2 , n_redundant=0, n_informative=2, random_state=22, n_clusters_per_class=1, scale=100) plt.scatter(X[:, 0], X[:, 1], c=y) plt.show() X = preprocessing.scale(X) # normalization step X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=.3) clf = SVC() clf.fit(X_train, y_train) print(clf.score(X_test, y_test))
2020-04-17
sk8_cross_validation
原来的代码比较旧,换上新一点的
交叉验证
1、把Iris花数据集分成7:3,用knn分类计算score
2、交叉验证,cross_val_score,计算score,cv=5表示把数据集分成4:1,5次预测,每次选的测试集都不一样
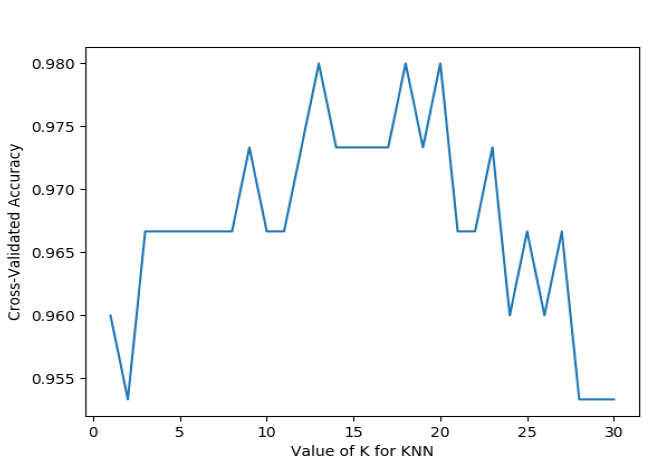
3、邻居个数用k_range从1到30表示,并用交叉验证的方法测试出应该选择多少个邻居比较好,可视化
from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split from sklearn.neighbors import KNeighborsClassifier iris = load_iris() X = iris.data y = iris.target # test train split # X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=4) knn = KNeighborsClassifier(n_neighbors=5) knn.fit(X_train, y_train) y_pred = knn.predict(X_test) print(knn.score(X_test, y_test)) # this is cross_val_score # from sklearn.model_selection import cross_val_score knn = KNeighborsClassifier(n_neighbors=5) scores = cross_val_score(knn, X, y, cv=5, scoring='accuracy') print(scores) print(scores.mean()) # this is how to use cross_val_score to choose model and configs # from sklearn.model_selection import cross_val_score import matplotlib.pyplot as plt k_range = range(1,31) k_scores = [] for k in k_range: knn = KNeighborsClassifier(n_neighbors=k) ## loss = -cross_val_score(knn, X, y, cv=10, scoring='mean_squared_error') # for regression scores = cross_val_score(knn, X, y, cv=10,scoring='accuracy') # for classification k_scores.append(scores.mean()) plt.plot(k_range, k_scores) plt.xlabel('Value of K for KNN') plt.ylabel('Cross-Validated Accuracy') plt.show()
运行结果
0.9736842105263158
[0.96666667 1. 0.93333333 0.96666667 1. ]
0.9733333333333334
sk9_cross_validation2
导入learning_curve,在5个特定位置(train_size)计算Loss,画图看Loss趋势,可初步判断有无过拟合
from sklearn.model_selection import learning_curve from sklearn.datasets import load_digits from sklearn.svm import SVC import matplotlib.pyplot as plt import numpy as np digits = load_digits() X = digits.data y = digits.target train_sizes, train_loss, test_loss= learning_curve( SVC(gamma=0.01), X, y, cv=10, scoring='neg_mean_squared_error', train_sizes=[0.1, 0.25, 0.5, 0.75, 1]) train_loss_mean = -np.mean(train_loss, axis=1) test_loss_mean = -np.mean(test_loss, axis=1) plt.plot(train_sizes, train_loss_mean, 'o-', color="r", label="Training") plt.plot(train_sizes, test_loss_mean, 'o-', color="g", label="Cross-validation") plt.xlabel("Training examples") plt.ylabel("Loss") plt.legend(loc="best") plt.show()
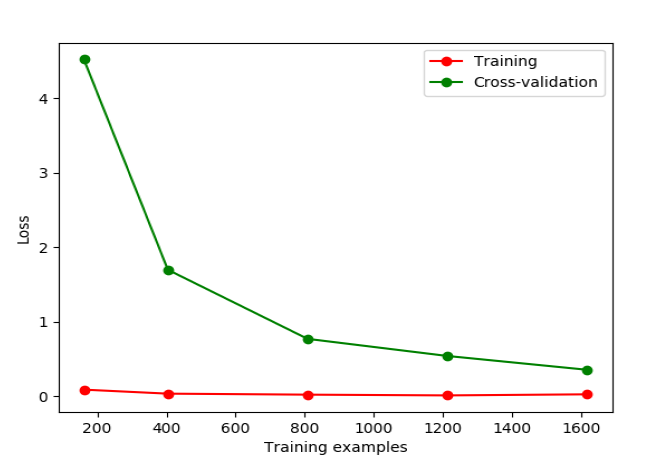
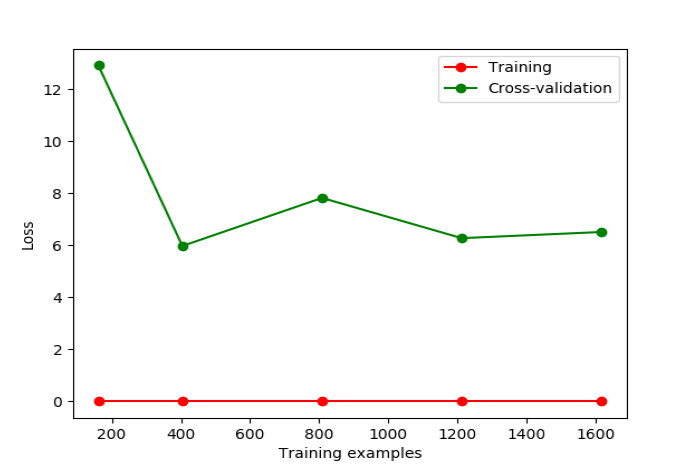
gamma=0.001,比较好 gamma=0.01,Loss下降后又上升,存在过拟合
2020-04-18
sk10_cross_validation3
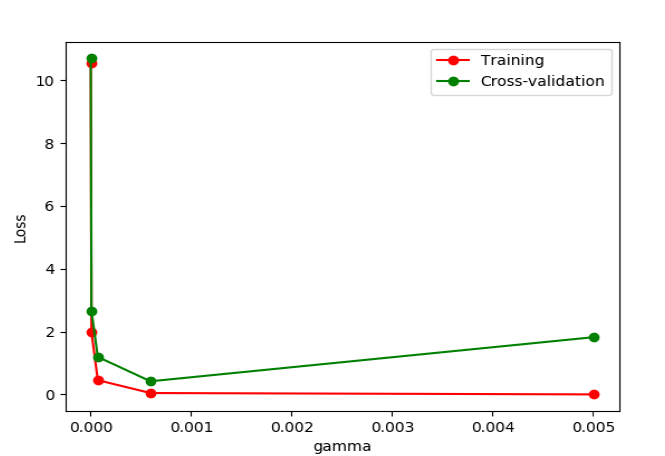
导入validation_curve,参数gamma从10^-6到10^-2.3,以横坐标为gamma数值,纵坐标为Loss值,可初步判断gamma的最优取值(传说中的调参)
from sklearn.model_selection import validation_curve from sklearn.datasets import load_digits from sklearn.svm import SVC import matplotlib.pyplot as plt import numpy as np digits = load_digits() X = digits.data y = digits.target param_range = np.logspace(-6, -2.3, 5)#从10^-6到10^-2.3,分成5份 train_loss, test_loss = validation_curve( SVC(), X, y, param_name='gamma', param_range=param_range, cv=10, scoring = 'neg_mean_squared_error') train_loss_mean = -np.mean(train_loss, axis=1) test_loss_mean = -np.mean(test_loss, axis=1) plt.plot(param_range, train_loss_mean, 'o-', color="r", label="Training") plt.plot(param_range, test_loss_mean, 'o-', color="g", label="Cross-validation") plt.xlabel("gamma") plt.ylabel("Loss") plt.legend(loc="best") plt.show()
sk11_save
训练完一个model后有两种方式保存,一是用pickle,二是用joblib
from sklearn import svm from sklearn import datasets clf = svm.SVC() iris = datasets.load_iris() X, y = iris.data, iris.target clf.fit(X, y) # method 1: pickle import pickle # save with open('save/clf.pickle', 'wb') as f: pickle.dump(clf, f) # restore with open('save/clf.pickle', 'rb') as f: clf2 = pickle.load(f) print(clf2.predict(X[0:1])) # method 2: joblib from sklearn.externals import joblib # Save joblib.dump(clf, 'save/clf.pkl') # restore clf3 = joblib.load('save/clf.pkl') print(clf3.predict(X[0:1]))
做个保存方便查看,完。