1.tf.nn.dynamic_rnn()
创建一个由RNNCell指定的递归神经网络cell。
tf.nn.dynamic_rnn(
cell,
inputs,
sequence_length=None,
initial_state=None,
dtype=None,
parallel_iterations=None,
swap_memory=False,
time_major=False,
scope=None
)
- cell:RNNCell的实例。
- inputs:RNN输入。如果为time_major == False(默认值),则必须Tensor为shape: [batch_size, max_time, …]或此类元素的嵌套元组。如果为time_major == True,则必须Tensor为shape:[max_time, batch_size, …]或此类元素的嵌套元组。这也可能是满足此属性的张量(可能是嵌套的)元组。前两个维度必须在所有输入中都匹配,否则,等级和其他形状成分可能会有所不同。在这种情况下,cell每个时间步长的输入 都将复制这些元组的结构,时间维度除外(从中获取时间)。cell每个时间步长的输入将是一个Tensor或多个(可能是嵌套的)张量元组,每个元组具有维度[batch_size, …]。
- sequence_length:(可选)一个int32 / int64向量[batch_size]。超过批处理元素的序列长度时,用于复制状态和归零输出。此参数使用户能够提取最后一个有效状态并正确填充输出,因此提供此参数是为了确保正确性。
- initial_state:(可选)RNN的初始状态。如果cell.state_size 为整数,则必须Tensor为适当的type和shape [batch_size, cell.state_size]。如果cell.state_size是元组,则它应该是具有形状的张量的元组[batch_size, s] for s in cell.state_size。
- dtype:(可选)初始状态和预期输出的数据类型。如果未提供initial_state或RNN状态具有异构dtype,则为必需。
- parallel_iterations:(默认值:32)。要并行运行的迭代次数。那些没有任何时间依赖性并且可以并行运行的操作将是。此参数权衡时间与空间。值>> 1使用更多的内存,但是占用的时间更少,而较小的值使用的内存更少,但是计算需要的时间更长。
- swap_memory:透明地交换前向推理中产生的张量,但从GPU到CPU的反向支持需要张量。这允许训练RNN,这些RNN通常不适合单个GPU,并且性能损失很小(或没有)。
- time_major:inputs和outputs张量的形状格式。如果为真,则Tensors必须将其成形[max_time, batch_size, depth]。如果为假,则Tensors必须对它们进行整形[batch_size, max_time, depth]。使用 time_major = True会更有效率,因为它避免了RNN计算开始和结束时的转置。但是,大多数TensorFlow数据都是批量生产的,因此默认情况下此函数接受输入并以批量生产的形式发出输出。
- scope:创建子图的VariableScope;默认为“ rnn”。
2.tf.contrib.layers.fully_connected()
添加一个完全连接的层。
tf.contrib.layers.fully_connected(
inputs,
num_outputs,
activation_fn=tf.nn.relu,
normalizer_fn=None,
normalizer_params=None,
weights_initializer=initializers.xavier_initializer(),
weights_regularizer=None,
biases_initializer=tf.zeros_initializer(),
biases_regularizer=None,
reuse=None,
variables_collections=None,
outputs_collections=None,
trainable=True,
scope=None
)
- inputs:张量至少为2,并且最后一个维度的静态值;即[batch_size, depth],[None, None, None, channels]。
- num_outputs:整数或长整数,表示图层中输出单位的数量。
- activation_fn:激活功能。默认值为ReLU函数。将其显式设置为None可以跳过它并保持线性激活。
- normalizer_fn:使用标准化函数代替biases。如果 normalizer_fn提供了,然后biases_initializer和 biases_regularizer被忽略,biases没有创造,也不能被添加。默认设置为无,因为没有规范化功能
- normalizer_params:归一化功能参数。
- weights_initializer:权重的初始值设定项。
- weights_regularizer:权重的可选正则化器。
- biases_initializer:用于偏差的初始化程序。如果为None,则跳过偏见。
- biases_regularizer:偏倚的可选正则化器。
- reuse:是否应重用图层及其变量。为了能够重用,必须给出层范围。
- variables_collections:所有变量的可选集合列表,或每个变量包含不同集合列表的字典。
- outputs_collections:集合以添加输出。
- trainable:如果True还向图集合添加变量 GraphKeys.TRAINABLE_VARIABLES(请参见tf.Variable)。
- scope:variable_scope的可选范围。
3.tf.losses.mean_squared_error()
首先我们可以看一下该函数的底层实现:
def mean_squared_error(
labels, predictions, weights=1.0, scope=None,
loss_collection=ops.GraphKeys.LOSSES,
reduction=Reduction.SUM_BY_NONZERO_WEIGHTS):
"""Adds a Sum-of-Squares loss to the training procedure.
`weights` acts as a coefficient for the loss. If a scalar is provided, then
the loss is simply scaled by the given value. If `weights` is a tensor of size
`[batch_size]`, then the total loss for each sample of the batch is rescaled
by the corresponding element in the `weights` vector. If the shape of
`weights` matches the shape of `predictions`, then the loss of each
measurable element of `predictions` is scaled by the corresponding value of
`weights`.
Args:
labels: The ground truth output tensor, same dimensions as 'predictions'.
predictions: The predicted outputs.
weights: Optional `Tensor` whose rank is either 0, or the same rank as
`labels`, and must be broadcastable to `labels` (i.e., all dimensions must
be either `1`, or the same as the corresponding `losses` dimension).
scope: The scope for the operations performed in computing the loss.
loss_collection: collection to which the loss will be added.
reduction: Type of reduction to apply to loss.
Returns:
Weighted loss float `Tensor`. If `reduction` is `NONE`, this has the same
shape as `labels`; otherwise, it is scalar.
Raises:
ValueError: If the shape of `predictions` doesn't match that of `labels` or
if the shape of `weights` is invalid. Also if `labels` or `predictions`
is None.
@compatibility(eager)
The `loss_collection` argument is ignored when executing eagerly. Consider
holding on to the return value or collecting losses via a `tf.keras.Model`.
@end_compatibility
"""
if labels is None:
raise ValueError("labels must not be None.")
if predictions is None:
raise ValueError("predictions must not be None.")
with ops.name_scope(scope, "mean_squared_error",
(predictions, labels, weights)) as scope:
predictions = math_ops.cast(predictions, dtype=dtypes.float32)
labels = math_ops.cast(labels, dtype=dtypes.float32)
predictions.get_shape().assert_is_compatible_with(labels.get_shape())
losses = math_ops.squared_difference(predictions, labels)
return compute_weighted_loss(
losses, weights, scope, loss_collection, reduction=reduction)
-
labels:真实张量,与“预测”的尺寸相同。
-
predictions:预测的输出。
通过底层代码我们发现losses实际上是通过调用squared_difference函数得到的
我们通过查看squared_difference函数的官方文档发现,该函数是计算两个张量的差的平方。
tf.math.squared_difference(
x,
y,
name=None
)
但是mean_squared_error()函数最后的返回值是函数compute_weighted_loss()的返回值,也就是说最终的损失还需再通过调用compute_weighted_loss函数才能得到,通过查看底层源码我们发现compute_weighted_loss函数是根据所给权重weights来计算由squared_difference函数得到的预测值与真实值差的平方的加权平均数。
def compute_weighted_loss(
losses, weights=1.0, scope=None, loss_collection=ops.GraphKeys.LOSSES,
reduction=Reduction.SUM_BY_NONZERO_WEIGHTS):
"""Computes the weighted loss.
Args:
losses: `Tensor` of shape `[batch_size, d1, ... dN]`.
weights: Optional `Tensor` whose rank is either 0, or the same rank as
`losses`, and must be broadcastable to `losses` (i.e., all dimensions must
be either `1`, or the same as the corresponding `losses` dimension).
scope: the scope for the operations performed in computing the loss.
loss_collection: the loss will be added to these collections.
reduction: Type of reduction to apply to loss.
Returns:
Weighted loss `Tensor` of the same type as `losses`. If `reduction` is
`NONE`, this has the same shape as `losses`; otherwise, it is scalar.
Raises:
ValueError: If `weights` is `None` or the shape is not compatible with
`losses`, or if the number of dimensions (rank) of either `losses` or
`weights` is missing.
Note:
When calculating the gradient of a weighted loss contributions from
both `losses` and `weights` are considered. If your `weights` depend
on some model parameters but you do not want this to affect the loss
gradient, you need to apply `tf.stop_gradient` to `weights` before
passing them to `compute_weighted_loss`.
@compatibility(eager)
The `loss_collection` argument is ignored when executing eagerly. Consider
holding on to the return value or collecting losses via a `tf.keras.Model`.
@end_compatibility
"""
Reduction.validate(reduction)
with ops.name_scope(scope, "weighted_loss", (losses, weights)):
# Save the `reduction` argument for loss normalization when distributing
# to multiple replicas. Used only for estimator + v1 optimizer flow.
ops.get_default_graph()._last_loss_reduction = reduction # pylint: disable=protected-access
with ops.control_dependencies((
weights_broadcast_ops.assert_broadcastable(weights, losses),)):
losses = ops.convert_to_tensor(losses)
input_dtype = losses.dtype
losses = math_ops.cast(losses, dtype=dtypes.float32)
weights = math_ops.cast(weights, dtype=dtypes.float32)
weighted_losses = math_ops.multiply(losses, weights)
if reduction == Reduction.NONE:
loss = weighted_losses
else:
loss = math_ops.reduce_sum(weighted_losses)
if reduction == Reduction.MEAN:
loss = _safe_mean(
loss, math_ops.reduce_sum(array_ops.ones_like(losses) * weights))
elif (reduction == Reduction.SUM_BY_NONZERO_WEIGHTS or
reduction == Reduction.SUM_OVER_NONZERO_WEIGHTS):
loss = _safe_mean(loss, _num_present(losses, weights))
elif reduction == Reduction.SUM_OVER_BATCH_SIZE:
loss = _safe_mean(loss, _num_elements(losses))
# Convert the result back to the input type.
loss = math_ops.cast(loss, input_dtype)
util.add_loss(loss, loss_collection)
return loss
权重默认情况下是1.上述底层实现用到的_num_present和_safe_mean函数源代码如下,前者是计算损失张量中元素的个数,后者是通过个数计算平均值。
def _num_present(losses, weights, per_batch=False):
"""Computes the number of elements in the loss function induced by `weights`.
A given weights tensor induces different numbers of usable elements in the
`losses` tensor. The `weights` tensor is broadcast across `losses` for all
possible dimensions. For example, if `losses` is a tensor of dimension
`[4, 5, 6, 3]` and `weights` is a tensor of shape `[4, 5]`, then `weights` is,
in effect, tiled to match the shape of `losses`. Following this effective
tile, the total number of present elements is the number of non-zero weights.
Args:
losses: `Tensor` of shape `[batch_size, d1, ... dN]`.
weights: `Tensor` of shape `[]`, `[batch_size]` or
`[batch_size, d1, ... dK]`, where K < N.
per_batch: Whether to return the number of elements per batch or as a sum
total.
Returns:
The number of present (non-zero) elements in the losses tensor. If
`per_batch` is `True`, the value is returned as a tensor of size
`[batch_size]`. Otherwise, a single scalar tensor is returned.
"""
if ((isinstance(weights, float) and weights != 0.0) or
(context.executing_eagerly() and weights._rank() == 0 # pylint: disable=protected-access
and not math_ops.equal(weights, 0.0))):
return _num_elements(losses)
with ops.name_scope(None, "num_present", (losses, weights)) as scope:
weights = math_ops.cast(weights, dtype=dtypes.float32)
present = array_ops.where(
math_ops.equal(weights, 0.0),
array_ops.zeros_like(weights),
array_ops.ones_like(weights))
present = weights_broadcast_ops.broadcast_weights(present, losses)
if per_batch:
return math_ops.reduce_sum(
present,
axis=math_ops.range(1, array_ops.rank(present)),
keepdims=True,
name=scope)
return math_ops.reduce_sum(present, name=scope)
def _safe_mean(losses, num_present):
"""Computes a safe mean of the losses.
Args:
losses: `Tensor` whose elements contain individual loss measurements.
num_present: The number of measurable elements in `losses`.
Returns:
A scalar representing the mean of `losses`. If `num_present` is zero,
then zero is returned.
"""
total_loss = math_ops.reduce_sum(losses)
return math_ops.div_no_nan(total_loss, num_present, name="value")
下面是上述方法的简单实现:

4.tf.contrib.layers.optimize_loss()
给定优化器的损失和参数后,返回训练操作。
tf.contrib.layers.optimize_loss(
loss,
global_step,
learning_rate,
optimizer,
gradient_noise_scale=None,
gradient_multipliers=None,
clip_gradients=None,
learning_rate_decay_fn=None,
update_ops=None,
variables=None,
name=None,
summaries=None,
colocate_gradients_with_ops=False,
increment_global_step=True
)
- loss:标量Tensor。
- global_step:标量int Tensor,步数计数器将更新每个步骤,除非 increment_global_step是False。如果未提供,它将从默认图表中获取(tf.compat.v1.train.get_global_step有关详细信息,请参见)。如果尚未创建,则每次重量更新不会增加任何步骤。learning_rate_decay_fn要求global_step。
- learning_rate:浮动或Tensor,每个训练步骤的更新幅度。可以None。
- optimizer:字符串,类或优化器实例,用作训练器。字符串应为优化程序的名称,例如“ SGD”,“ Adam”,“ Adagrad”。OPTIMIZER_CLS_NAMES常量中的完整列表。class应该是tf.Optimizer 该实现compute_gradients和apply_gradients功能的子类。优化器实例应该是tf.Optimizer子类的实例并且具有compute_gradientsand apply_gradients函数。
- gradient_noise_scale:浮点或无,添加按此值缩放的0均值正常噪声。
- gradient_multipliers:变量或变量名的字典,用于浮点数。如果存在,则将指定变量的梯度乘以给定常数。
- clip_gradients:float,callable或None。如果提供浮点数,则会应用全局裁剪,以防止梯度范数超过此值。可替代地,可以提供可呼叫的,例如 adaptive_clipping_fn()。此可调用对象获取(gradients, variables)元组列表,并返回相同的东西,并修改了渐变。
- learning_rate_decay_fn:函数,取learning_rate和global_step Tensor,返回Tensor。可用于实现任何学习速率衰减功能。例如:tf.compat.v1.train.exponential_decay。如果learning_rate未提供,则忽略。
- update_ops:Operation每个步骤要执行的更新列表。如果为None,则使用UPDATE_OPS集合的元素。update_ops和之间的执行顺序 loss是不确定的。
- variables:优化或None使用所有可训练变量的变量列表。
- name:此操作的名称用于范围操作和汇总。
- summaries:在张量板上可视化的内部数量列表。如果未设置,将报告梯度的损失,学习率和全局范数。可能值的完整列表在OPTIMIZER_SUMMARIES中。
- colocate_gradients_with_ops:如果为True,请尝试将渐变与相应的op并置。
- increment_global_step:是否增加global_step。如果您的模型在optimize_loss每个训练步骤中调用了多次(例如,优化模型的不同部分),请使用此arg避免增加 global_step不必要的次数。
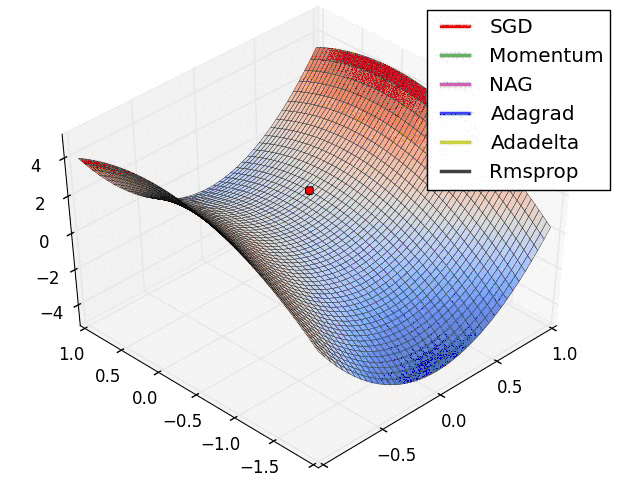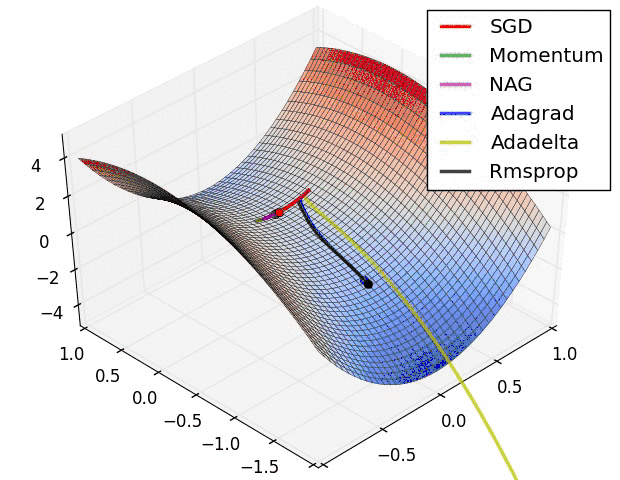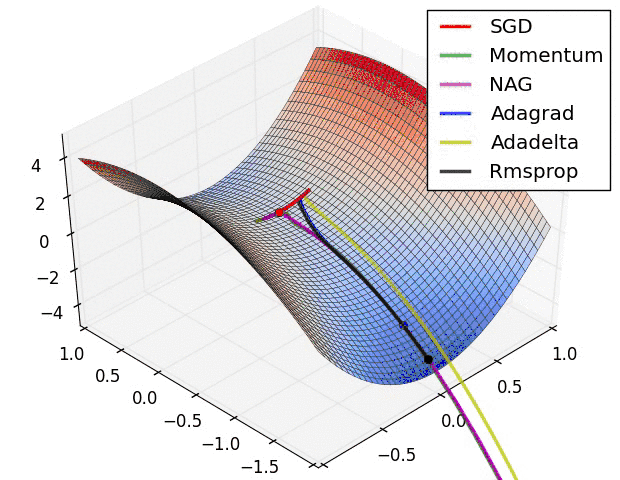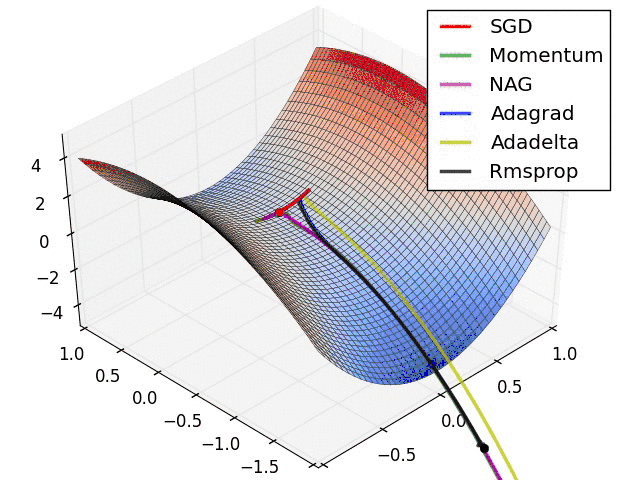
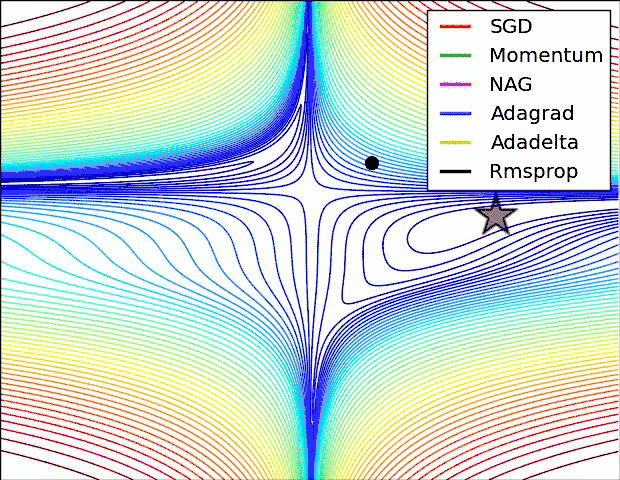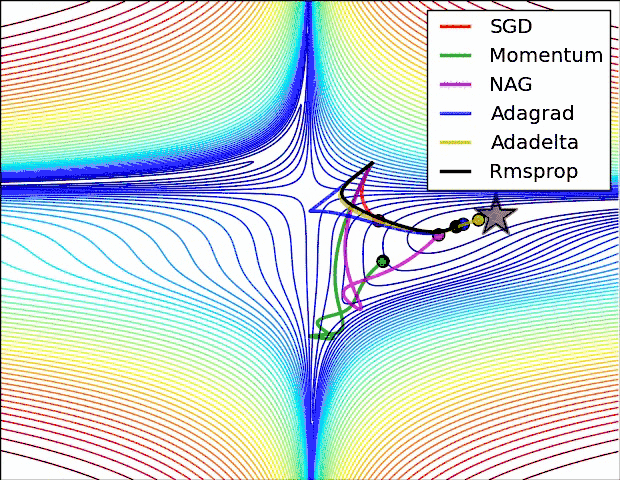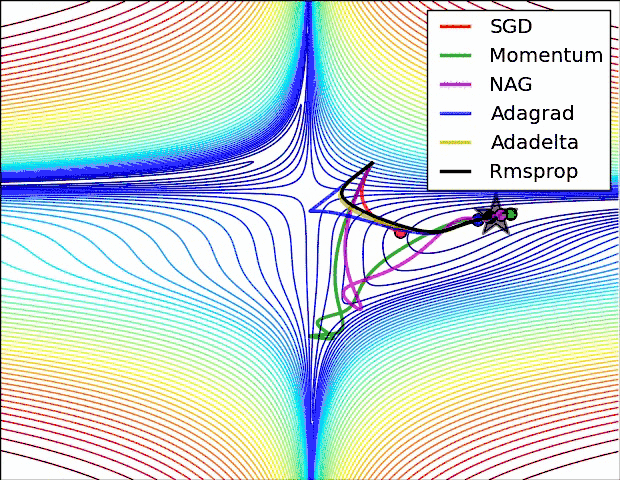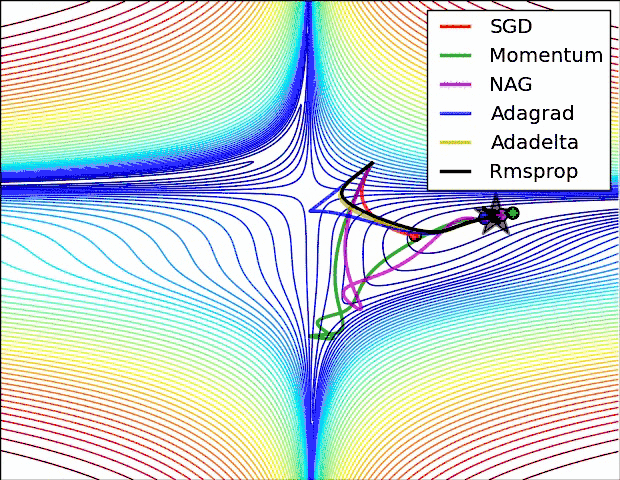
上图是几种optimizer优化器的学习效果,可以看出,Adagrad, Adadelta, RMSprop优化器几乎很快就找到了正确的方向并前进,收敛速度也相当快,而SGD的收敛速度较慢,Momentum和NAG优化器走了很多弯路才能找到全局最优值。几种优化器的具体详解可以看这篇论文梯度下降优化算法的概述。
