梯度下降(Gradient Descent, GD)是目前机器学习、深度学习解决最优化问题的算法中,最核心、应用最广的方法。它不是一个机器学习算法,而是一种基于搜索的最优化方法。其作用是用来对原始模型的损失函数进行优化,以便寻找到最优的参数,使得损失函数的值最小。也就是,用已知训练集数据寻找最优得参数,从而找到最优得拟合模型。哪什么是梯度下降呢?
一、概念
梯度是向量,和参数维度一样。简单地来说,多元函数的导数(derivative)就是梯度(gradient),分别对每个变量进行微分,然后用逗号分割开,梯度是用括号包括起来,说明梯度其实是一个向量。比如说线性回归损失函数L的梯度为: 。
二、计算过程
1、步骤:
①、对各参数向量求偏导,得出
;
②、设置初始参数向量、学习率 η及阈值threshold ;
③、迭代计算参数向量下
值,若
值小于等于阈值threshold 停止,此时的参数向量为局部最优解;否则,计算下一点参数向量,公式是上一个点参数向量-η*
,进行下一步迭代。
2、一元方程式
一元函数:
第一步,求导数。
第二步,初始化
、η、threshold。
第三步,计算
,并和threshold对比。
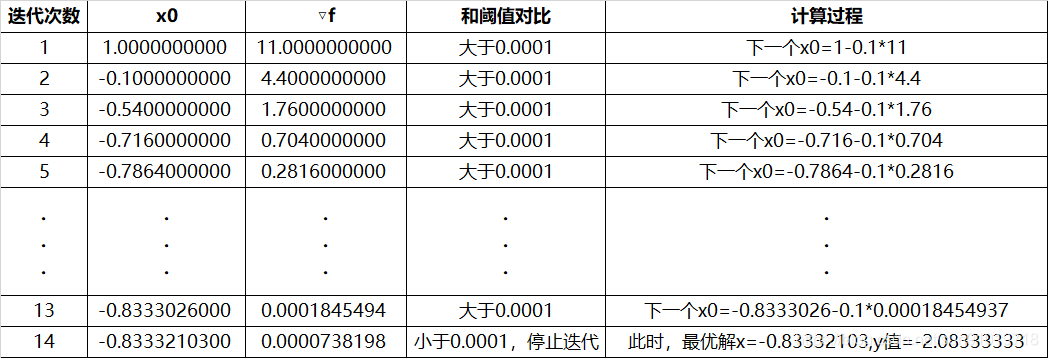
第四步,迭代过程。如下表所示:
2.1 简单代码演示
首先,手工定义原函数和导函数。
def loss_function(x):
return 3*(x**2)+5*x
def det_function(x):
return 6*x+5
然后,定义梯度下降方法。
def get_GD(od_f=None,f=None,x_0=None,eta=0.001,threshold=0):
x_all=[]
od_f_all=[]
det_f_all=[]
count_n=0
while True:
count_n+=1
y=od_f(x_0)
#计算导数在x处的值
det_f=f(x_0)
od_f_all.append(y)
x_all.append(x_0)
det_f_all.append(det_f)
#计算下一个点的值
x_0=x_0-eta*det_f
#判断是否到达目的地
if det_f<=threshold:
break
return x_all,od_f_all,det_f_all,count_n
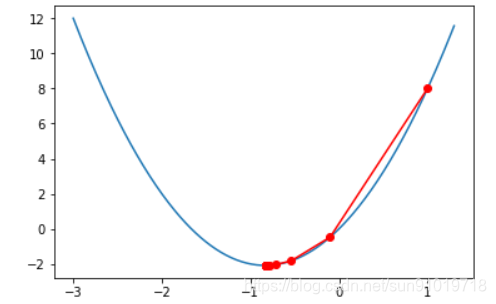
最后,设置x_0=1,eta=0.1,threshold=0.0001。查看图形。
参考文章:https://mp.weixin.qq.com/s/44p8anqiiQV6XYGqH5u-Ug
https://mp.weixin.qq.com/s/nI9IBa4ccfg0xqyn0tbRPA
https://mp.weixin.qq.com/s/8gStYSSBvkXeuaX6Pp9qiQ
https://mp.weixin.qq.com/s/OUslRwKGpS29gncsiyAPyg
