前言
第二章的内容是介绍了一个线性分类器:感知机。第二章的重点内容我认为有以下几点:
- 感知机的基本信息(输入,输出,适用范围,假设空间)
- 感知机的学习策略
- 感知机的算法过程
- 感知机收敛性证明
- 感知机的对偶形式的理解
1.感知机的基本信息
| 输入 | 向量 |
|---|---|
| 输出 | 标签(+1,-1) |
| 适用范围 | 二分类问题,且数据集线性可分 |
| 假设空间 | y=sign(w*x+b) |
2.感知机的学习策略
- 损失函数定义:
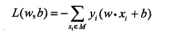
这个函数怎么来的呢? 引用书中的一段话:
损失函数的一个自然选择是误分类的点的总数,但是这样的损失函数不是参数w的连续可导函数,不易优化损失函数的的另一个选择是误分类点超平面s的总距离。
一个点到超平面s的距离表示为:
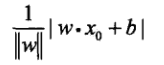
其中,wxi+b表示的xi这个点是当前模型下的输出值,输出共有三种情况:大于0,等于0,小于0。对于误分类点:(因为误判,所以符号相反,取个负号又变正了)
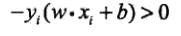
结合||w||永远为正式,所以就最终得到损失函数:
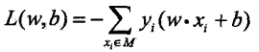
2. 优化方法:梯度下降法(这个方法比较经典)
3. 感知机的算法过程

算法也不是很难,特点是:逐点遍历,每当有数据点被误分类,就更新参数,直到所有点都分类正确为止。
4. 感知机收敛性的推导
 这个定理主要讲了两件事:
这个定理主要讲了两件事:
(1) 在所有数据线性可分的前提下,存在一个超平面,而且模型输出值会有一个最小值。
(2) 误分类次数会有一个上限值,这个上限值跟(1)中提到的最小值,和数据中模值最大的样本有关
证明过程可以自己看书,在文末也会附上推导解释,这里我想谈一下对证明过程的思考。
- 为什么要求要数据集线性可分?
这简直就是收敛的大前提啊!如果线性不可分,那么就不存在理想的超平面把数据分开,那么就不存在定理(1)中的最小值,而这个最小值正是与迭代次数k的上限有关的。 - 为什么要采用随机梯度算法?
这也是跟定理(2)的证明有关,梯度下降法使wk和wk-1的关心正好能凑成下图圆圈的那个部分,从而使公式可以一直递推下去(这种精妙感太难以言表)
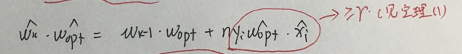
5. 感知机的对偶形式的理解
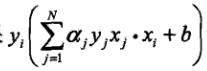
-
对偶形式是怎么来的?
基本形式是 y=wx+b,其实对偶形式也就是
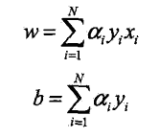
-
这两个公式怎么理解呢?
对偶形式,实际上就是从增量的角度来看问题,
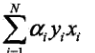 实质上就是w最终的增量,如果把这一堆东西看成w1,那么上式就变成了w= w0+w1,因为初始值变为0了,所以就有了上式。其中,ai=学习率*ni,ni表示第i个样本被误判的次数,这说算法会着重关注那些经常被误判的一些点。
实质上就是w最终的增量,如果把这一堆东西看成w1,那么上式就变成了w= w0+w1,因为初始值变为0了,所以就有了上式。其中,ai=学习率*ni,ni表示第i个样本被误判的次数,这说算法会着重关注那些经常被误判的一些点。 -
迭代过程
在实际实现中,a是一个向量,长度为样本点的数目。在迭代更新时,不会更新a的所有分量。如果xi这个样本点被误判,那么只需要更新ai这个分量。
4. 与基本形式的对比
更新时只更新一个分量,效率更高。
5. 为什么在计算第xi个样本点时,也要计算其他的样本点呢?例如:
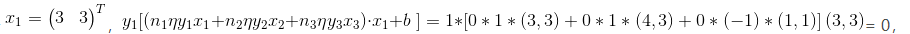
我是这样考虑的:这跟误判次数ni很有关系。当算法一开始时,每个ai都是0(误判次数为0),到了第一个样本点x1,如果x1这个点有问题,超平面就挪一下。经过不断迭代后,如果x2也有问题,那在移动超平面时,也把a2考虑在内(n2不为0了,a2也就不为0了),所以算法是重点关注那些老被误判的点,综合起来做调整的超平面的,效率也就更高。
6 附录
-
点到平面的距离公式推导

-
感知机收敛推导

-
参考:
https://blog.csdn.net/qq_26826585/article/details/87967520
统计学习方法第二版
