Lecture 4:Value Function Approximation
问题引出
为什么要价值函数近似?
现实生活或者更大的游戏中,状态可能非常多,如何在这种情况下运用之前的知识是一个挑战。
之前的方法都可以存放在表格或者向量中,但是当状态多的时候无法保存。
因此避免用table去表征,有效的解决方法是用带参数的函数近似的办法去估计。
价值函数近似

这样的优点可以泛化到没有观察到的状态,更新参数可以用MC,TD的方法近似估计。
近似的类别有如下三种方式:

函数估计的模型
可以有多种,比如
线性模型(线性叠加模型);
神经网络;
决策树;
k近邻。
前两种可微分,因此可以很好的去优化参数
复习梯度下降:

价值函数的估计也是用这种方式优化
有一个Oracle以后,通过梯度下降来优化价值函数

问题是怎么描述不同状态,一种方法是向量,特征(位置,速度,加速度等)。
线性模型
首先选取线性模型来拟合价值函数
 线性函数的时候会得到接近全局最小点的值。
线性函数的时候会得到接近全局最小点的值。
一种特殊的特征的定义,类似独热编码的形式。这种情况下估计的就是Wk

在没有Oracle的情况下怎么优化拟合函数?
优化
在model-free的方法中,我们采用MC或者TD的方法估计价值函数。
所以在这里我们可以采用Target代替Oracle
 MC和价值估计的结合时:
MC和价值估计的结合时:
G时无偏的,但是有noisy,在MC中获取很多S,G的组合,然后用监督的方法更新

TD和价值估计结合时:
有偏差,因为target包含了正在优化的参数,但是也是可用,因此也可以用类似的方法
 semi-gradient,同时可以近似收敛到全局最优。
semi-gradient,同时可以近似收敛到全局最优。

将价值近似用到策略控制中

动作价值函数
 定义对应状态和动作的特征向量,w更新公式见前面。
定义对应状态和动作的特征向量,w更新公式见前面。

 sarsa算法:
sarsa算法:
 小例子
小例子

在这个游戏中,状态为划分为小格子的空间的坐标。
收敛问题
TD中有两个近似的过程,因此优化过程不稳定。同时离线由于目标策略和行为策略一部值,也会造成不稳定。
死亡三角
强化学习中的死亡三角:
1、函数估计中的近似,引入误差;
2、采取自举的方法,引入噪声
3、离线策略引入
收敛性问题
小规模 mc,Q,sarsa,可用table表示,都可以找到最优解;
如果是近似的,线性来说MC,Sarsa,可以找到最优,Q近似最优
非线性都不能保证
更新方法
整体更新优化
数据库D中有s,v,上千对。

也可以从D中随机采样(小批量)得到
DNQ
回忆线性
线性的时候利用函数x(s)可以提取特征,然后利用线性叠加的方式进行近似。

利用target代替真值。
线性拟合的时候只有定义好特征后才能work,同时这种设定很困难。
非线性
优点
而非线性模型可以把特征提取和价值函数学习结合起来(在一步中完成),比如神经网络(多层)。
优化参数的时候用chain rule(链式法则)
卷积神经网络在图像处理中广为流传,有卷积和非线性的操作(正好符合要求)。
因此可以结合深度学习和强化学习。
缺点
神经网络拟合函数(价值函数,策略函数,环境)常用SGD等,效率问题需要考虑,因为参数很多,同时死亡三角问题需要考虑,比如收敛问题,以及是不是最优解。
DNQ
DQN

因为是神经网络,因此是局部解。
然后用target代替

具体工作
神经网络拟合Q函数,输入用游戏界面,连续4帧,输出18个操作,两层卷积网络+一层全连接。
问题
需要克服的问题:
样本的相关度,因为在像素级别,时序之间相关性非常高;
target不稳定
方法
克服的方法:
经验回放
fixed Q targets
1、经验回放
replay memory D
simple的格式:
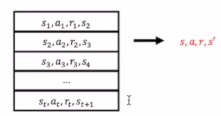
训练的过程中,一个网络一直玩游戏,同时在训练的时候通过采样

2、fixed targets
因为target在更新的时候也是待优化的。
产生target的网络固定weight或者与训练的网络存在时间差,不同的权重。
w- 与w更新存在时间差,w-更新慢

对比

代码

总结

改进
1、改进

2、博客!!!
DNQ的改进集合

3、homwork

