大家好,这是我们xgboost系列的第二篇,上一篇讲述了xgboost的数学理论部分,包括目标函数、正则化、如何优化目标函数、分裂点的度量。
本小节在上一节的基础上,讲述xgboost如何从根节点分裂树。当我们想找到一个分裂点的时候,我们需要干两件事情,第一件事情是遍历所有的特征,第二件事是从每个特征中找出最优的分裂点。在实际实现中就是两个for循环的事。
一、最简单的分裂方式:贪心法
这种方法是在找分裂点的第二步,直接遍历每个特征的所有特征值。也就是说假如有一个连续特征,有1亿个值,它就计算1亿次,每次将特征小于当前划分点的放树的一边,将大于的放树的另一边。
当然在具体计算的时候,这种方法是先把特征都排好序,然后再从小到大或者从大到小一个个遍历,划分好左右节点后,计算收益,最后选择收益最大的点。在第一节提到收益计算的方法为:
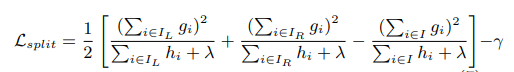
也就是损失函数减少得最多的分裂方法。
二、优化的分裂方式:近似算法
近似算法就是选择特征的部分值进行分裂,比如随机选择几个点,但是这种随机肯定不行,因为乱了。
一种方法是用直方图的方式,画直方图(histograms)的时候我们会指定几个直方,称为bin。lightgbm使用了这种方法。
xgboost使用了一种分位图的方法(quantile),1/4分位图是说小于它的数占1/4,同理1/2,3/4也是一个意思。
这种方法分两种,一种是全局的分位图,一种是局部的。大白话就是说分为图在一开始算一次,后续都按照这个分裂,局部是说分位图随着分裂重新算。
三、xgboost的分裂方式: Weighted Quantile Sketch
这种算法是计算样本的权重,然后根据样本权重进行分位图的计算,那么xgboost中如何确定样本的权重呢?
如果对lightgbm有一定的了解,lightgbm是根据样本的梯度确定它的重要性。xgboost也采取了类似的算法。
从上一节中xgbosot的目标函数为:
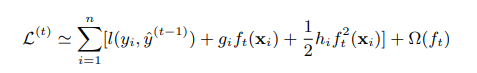
可以简写为:
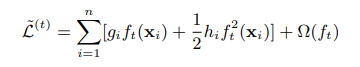
进一步,可以简写为:
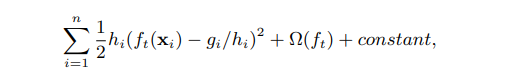
PS: 上面这个简写的式子貌似第一个减号得修改成加号或者减去负的 -g/h。
式子中hi为对损失函数的二阶导,gi为对损失函数的一阶导。
如果了解带权回归,上面的式子跟它长得很像,此时,hi就可以当作是样本的权重。
至此样本权重已确定。
总结:本节讲述了树的分割方法,下一节将讲述xgboost如何利用带权数据进行带权分位图的分割
参考文献
[1] https://www.kdd.org/kdd2016/papers/files/rfp0697-chenAemb.pdf
[2] https://homes.cs.washington.edu/~tqchen/data/pdf/xgboost-supp.pdf
