Hadoop2之HDFS2介绍
一、简介
HDFS全称是Hadoop Distributed File System,是一个旨在运行在普通机器上的分布式的文件系统。HDFS与其他分布式文件系统最要的区别在于其可以在廉价的机器上发挥出极其出色的性能。
二、特点
- 特点
HDFS主要具有以下特点:
1、支持超大文件;
2、检测和快速应对硬件故障;
3、高吞吐量,批量处理数据;
4、简化一致性模型,write-once-read-many处理模型 - 不适合的场景
HDFS不适合的场景:低延迟数据访问、大量小文件、对文件元数据产生修改操作。
三、NameNode and DataNodes
- 简介
HDFS是一个主从结构的架构,一台HDFS的集群主要由一个NameNode单点节点和一群DataNodes组成,架构如图3.1所示。
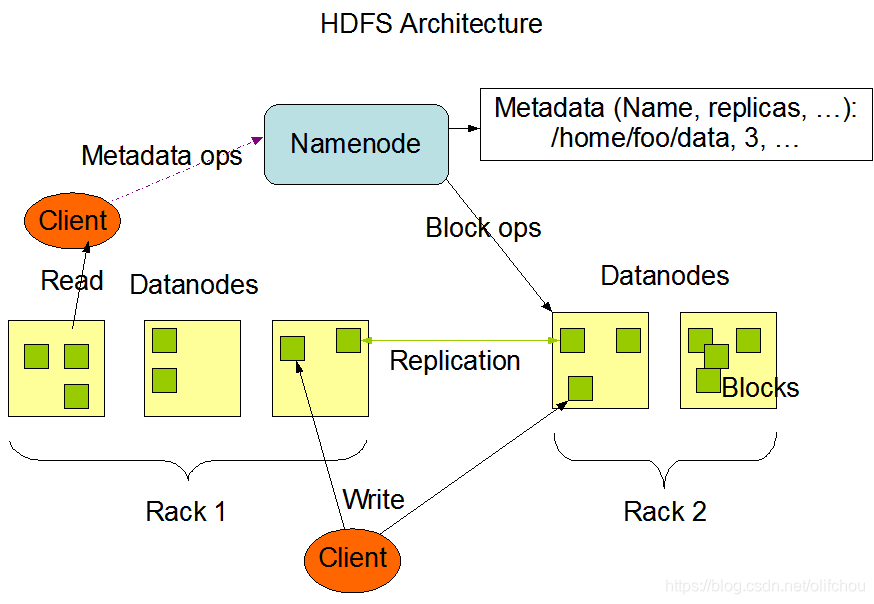
图3.1 HDFS架构图-
NameNode
主要工作:
(1)管理者文件系统命名空间
维护文件系统树及树中的所有文件和目录
(2)存储元数据
元数据:文件名、目录名及层级关系;文件目录所有者及其权限;每个文件块的名及文件有哪些块组成。元数据一般保存在内存中。
(3)保存文件、block、datanode之间的映射关系
NameNode高可用:
(1)主备方式
HDFS通过在同一个集群中运行两个NameNode(acitve NameNode和standby NameNode)来实现,在任何时间里只有一台机器处于Active状态,另一台处于standby状态(随时提供故障恢复服务),如图3.2所示。
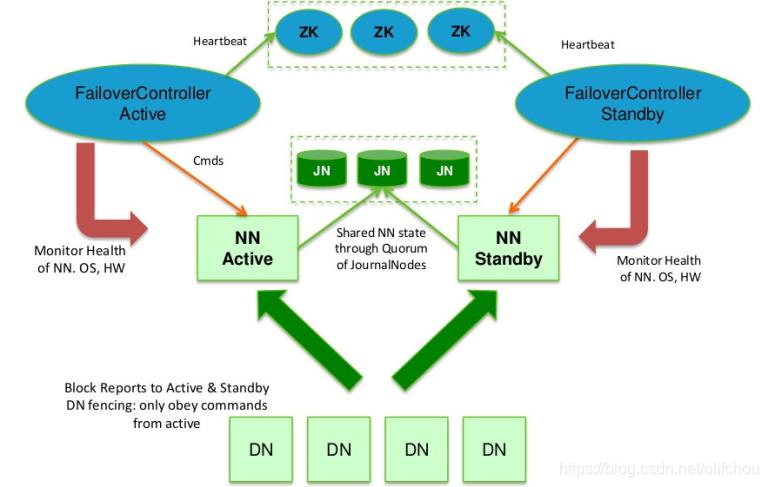
图3.2 HDFS高可用架构图
其中,元数据一致性主要由JournalNodes通过同步来实现,如图3.3所示。
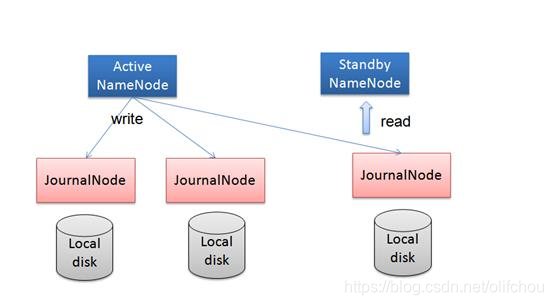
图3.3 元数据同步机制
(2)集群方式
集群中提供多个NameNode,每个NameNode负责管理一部分DataNod,如图3.4、3.5所示。
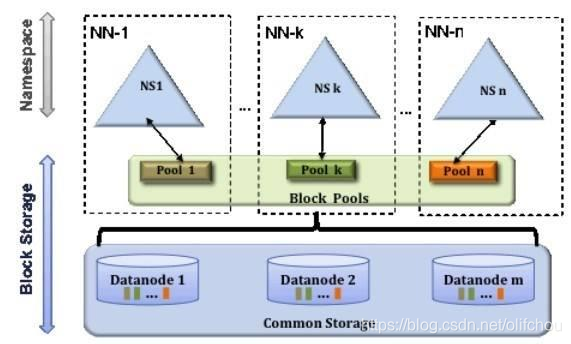
图3.4 高可用集群
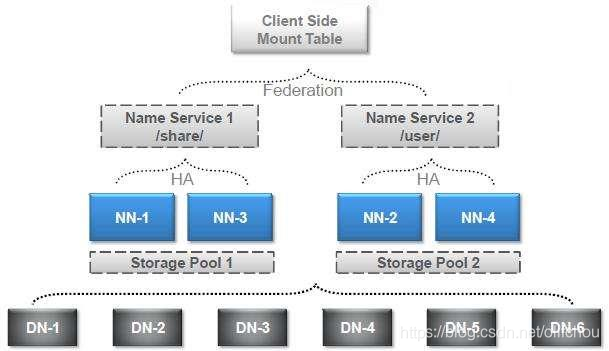
图3.5 高可用集群 -
DataNode
主要工作:
(1)负责存储数据块,负责为系统客户端提供数据块的读写服务
(2)根据NameNode的指示进行创建、删除和复制等操作
(3)通过心跳定期汇报文件块列表信息
(4)DataNode之间进行通信,块的副本处理 -
DataNode副本
(1)数据块副本放置策略的目的是在以下两者之间取得平衡:
a. 使数据的可靠性和可用性最大化
b.使写入数据产生的开销最小化(2)当一个数据块被创建的时候,遵循以下规则:
a. 第一个副本放置于本地节点
b.第二个副本放置于不同机架
c.第三个副本放置于本地机架的不同节点
(3)数据读取
当发生数据读取的时候,NameNode首先检查客户端是否位于集群中,如果是,则按照由近到远的优先次序决定哪个DataNode向客户端发送它需要的数据块。 -
Block
数据块是磁盘读写的基本单位,HDFS默认数据块的大小是64M,磁盘块大小一般为512B。增大块可以有效减少寻址时间。数据块过大也不好,因为MapReduce通常是以一个块作为输入,快过大容易导致任务数量过小,降低作业处理速度。
-
