1:准备customers.csv
scala> val dfCustomers=spark.read.format("csv").option("delimiter",",").option("quote","\"").option("escape","\"").load("file:///home/data/customers.csv")
dfCustomers: org.apache.spark.sql.DataFrame = [_c0: string, _c1: string ... 7 more fields]
scala> dfCustomers.show

2:导入包:
scala> import org.apache.spark.sql.functions._
import org.apache.spark.sql.functions._
scala> import org.apache.spark.sql.types._
import org.apache.spark.sql.types._
3:根据csv文件格式生成DF
3.1转换customers.csv
scala> val dfCustomers=spark.read.format("csv").option("delimiter",",").option("qoute","\"").option("escape","\"").load("file:///home/data/customers.csv").withColumn("ID",col("_c0").cast(IntegerType)).withColumnRenamed("_c1","FirstName").withColumnRenamed("_c2","LastName").withColumnRenamed("_c3","HomePhone").withColumnRenamed("_c4","WorkPhone").withColumnRenamed("_c5","Address").withColumnRenamed("_c6","City").withColumnRenamed("_c7","State").withColumnRenamed("_c8","Zipcode").drop("_c0")
dfCustomers: org.apache.spark.sql.DataFrame = [FirstName: string, LastName: string ... 7 more fields]
scala> dfCustomers.show(5)

3.2转换orders.csv
scala> val dfOrders=spark.read.format("csv").option("delimiter",",").option("qoute","\"").option("escape","\"").load("file:///home/data/orders.csv").withColumn("OrderID",col("_c0").cast(IntegerType)).withColumnRenamed("_c1","OrderDate").withColumn("OrderCustomerID",col("_c2").cast(IntegerType)).withColumnRenamed("_c3","OrderStatus").drop("_c0").drop("_c2")
dfOrders: org.apache.spark.sql.DataFrame = [OrderDate: string, OrderStatus: string ... 2 more fields]
scala> dfOrders.show(false)

4把生成的DF转化为临时表:
scala> dfCustomers.createOrReplaceTempView("customers")
scala> dfOrders.createOrReplaceTempView("orders")
5联合join查询:
scala> val dfSQLResult=spark.sql("select c.FirstName,c.LastName,o.OrderDate,o.OrderStatus from customers c inner join orders o on c.ID = o.OrderCustomerID")
dfSQLResult: org.apache.spark.sql.DataFrame = [FirstName: string, LastName: string ... 2 more fields]
查询结果:
scala> dfSQLResult.show(10,false)

6DF方式联合查询:
scala> val dfResult=dfCustomers.alias("c").join(dfOrders.alias("o"),col("c.ID")===col("o.OrderCustomerID"),"inner").select(col("c.FirstName"),col("c.LastName"),col("o.OrderDate"),col("o.OrderStatus"))
dfResult: org.apache.spark.sql.DataFrame = [FirstName: string, LastName: string ... 2 more fields]
scala> dfResult.show(false)

7 Left_outer:
scala> val dfleftResult=dfCustomers.alias("c").join(dfOrders.alias("o"),col("c.ID")===col("o.OrderCustomerID"),"left_outer").select(col("c.FirstName"),col("c.LastName"),col("o.OrderDate"),col("o.OrderStatus"))
dfleftResult: org.apache.spark.sql.DataFrame = [FirstName: string, LastName: string ... 2 more fields]
scala> dfleftResult.show(5,false)
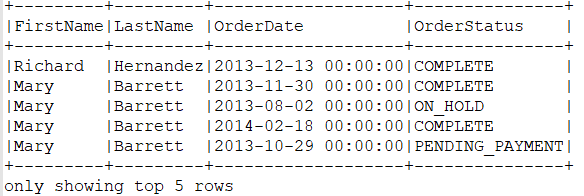
8准备order_items表,为三表联查做准备:
scala> val dfItems=spark.read.format("csv").option("header","false").option("delimiter",",").option("quote","\"").option("escape","\"").load("file:///home/data/order_items.csv")
dfItems: org.apache.spark.sql.DataFrame = [_c0: string, _c1: string ... 4 more fields]
scala> dfItems.show(2)
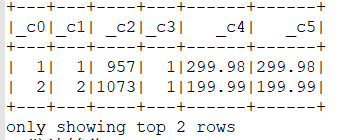
继续转化:
scala> val dfItems=spark.read.format("csv").option("header","false").option("delimiter",",").option("quote","\"").option("escape","\"").load("file:///home/data/order_items.csv").withColumn("ItemOrderID",col("_c1").cast(IntegerType)).withColumn("Quantity",col("_c3").cast(IntegerType)).withColumn("SubTotal",col("_c4").cast(DoubleType)).withColumn("ProductPrice",col("_c5").cast(DoubleType)).select("ItemOrderID","Quantity","SubTotal","ProductPrice")
dfItems: org.apache.spark.sql.DataFrame = [ItemOrderID: int, Quantity: int ... 2 more fields]
scala> dfItems.show()

三表联查(SQL实现):
scala> dfItems.createOrReplaceTempView("items")
scala> val dfSQLResult=spark.sql("select * from customers c inner join orders o on c.ID=o.OrderCustomerID inner join items i on o.OrderID=i.ItemOrderID")
dfSQLResult: org.apache.spark.sql.DataFrame = [FirstName: string, LastName: string ... 15 more fields]
scala> dfSQLResult.show

三表查询消费最多的人:
scala> val dfSQLResult=spark.sql("select c.FirstName,c.LastName,sum(i.SubTotal) as TotalPurchase from customers c inner join orders o on c.ID=o.OrderCustomerID inner join items i on o.OrderID=i.ItemOrderID group by c.FirstName,c.LastName order by TotalPurchase desc")
dfSQLResult: org.apache.spark.sql.DataFrame = [FirstName: string, LastName: string ... 1 more field]
scala> dfSQLResult.show

DF方式实现:
scala> val dfResult=dfCustomers.alias("c").join(dfOrders.alias("o"),col("c.ID")===col("o.OrderCustomerID"),"inner").join(dfItems.alias("i"),col("o.OrderID")===col("i.ItemOrderID"),"inner")
dfResult: org.apache.spark.sql.DataFrame = [FirstName: string, LastName: string ... 15 more fields]
scala> dfResult.show

继续 转化格式:
scala> val dfResult=dfCustomers.alias("c").join(dfOrders.alias("o"),col("c.ID")===col("o.OrderCustomerID"),"inner").join(dfItems.alias("i"),col("o.OrderID")===col("i.ItemOrderID"),"inner").select(col("c.FirstName"),col("c.LastName"),col("i.SubTotal"))
dfResult: org.apache.spark.sql.DataFrame = [FirstName: string, LastName: string ... 1 more field]
scala> dfResult.printSchema
root
|-- FirstName: string (nullable = true)
|-- LastName: string (nullable = true)
|-- SubTotal: double (nullable = true)
实现:
scala> val dfResult=dfCustomers.alias("c").join(dfOrders.alias("o"),col("c.ID")===col("o.OrderCustomerID"),"inner").join(dfItems.alias("i"),col("o.OrderID")===col("i.ItemOrderID"),"inner").select(col("c.FirstName"),col("c.LastName"),col("i.SubTotal")).groupBy(col("FirstName"),col("LastName")).agg(sum(col("SubTotal")).as("TotalPurchase")).sort(col("TotalPurchase").desc)
dfResult: org.apache.spark.sql.Dataset[org.apache.spark.sql.Row] = [FirstName: string, LastName: string ... 1 more field]
scala> dfResult.show

