sync.Map简述
简单来说,sync.Map是并发版本的map,golang自带的map在并发操作下会触发panic。sync.Map支持Load,Store, LoadOrStore,Range,Delete操作。其中Range支持在多goroutine下运作,能确保每个key最多被处理一次,但是无法保证遍历过程中实时同步其他goroutine的增删操作。
使用sync.Map
你真的需要sync.Map吗?
比起sync.Map如何使用,一个更重要的问题在于我们是否真的需要sync.Map。的确如我们之前所说,sync.Map支持并发而map不支持,但是我们可以很轻松的用RWMutex或者Mutex结合map来支持并发,而且比起sync.Map,这两种方案更好的支持类型安全,而且在绝大多数时候性能更优。一个简单的答案是,如果你不知道为什么需要sync.Map,那么很可能你不需要sync.Map。
那么什么时候我们需要sync.Map呢?要解答这个问题,我们不妨回顾下sync.Map被提出的原因。简单来说,sync.Map被提出是因为google发现,RWLock配合map方案在高读取+多核cpu上表现不佳(具体可以翻看overview of sync map)。因此,snyc.Map就是为了改善多核高读取低写入时候的性能而引入。
具体来说,如果你的应用有以下的属性,那么可以考虑使用,否则更加建议使用RWMutex或者Mutex结合map的方案
- 如果写入的key是稳定的(极少)
- 如果不同goroutine对key的访问是不同的
如何更好地使用sync.Map
sync.Map有着非常简单的API,如果你需要存储新的键值对,你可以使用Store,如果你需要读取键值对,你可以使用Load;如果需要删除某个键值对,那么使用Delete;如果你需要遍历整个map,Range在那里等你。
但是我们如果观察sync.Map的API,我们会发现,为了考虑通用性,所有的key和value都是interface{},换言之,我们失去了类型检查提供的安全性而且被迫更多的使用类型断言。于是你面临着两种选择:在每次调用API后都小心翼翼地使用类型断言,你的代码里面出现无数的if v,ok=value.(xxType);!ok{};亦或者每一次都直接使用v.(xxType)直到你的进程在某些关键时刻宕机让你抓耳挠腮为止。那么我们还有第三种方案吗?庆幸的是,答案是有的,不过需要我们做出一些小小的努力。
如果你的map在使用的时候有明确类型,一个简单的思路是封装snyc.Map并且对外提供指定类型的Load,Delete、Store等等
type StringMap struct{
m sync.Map
}
func (s *StringMap) Store(key,value string){
s.m.Store(key,value)
}
func (s *StringMap) Load(key string)(value string,ok bool){
v, ok := s.m.Load(key)
if v != nil {
value = v.(string)
}
return
}
//以此类推
你可能会对这个方案不太满意,因为如果类型一旦改变,比方说简单的将键类型改为int,你就需要重新创建一个结构体和方法。这也是go没有泛型所带来的烦恼之一,不过如果你真的迫切的需要,我们也还是有办法的, 不过接下来的方案就需要牺牲一点性能——因此你也许应该往上翻翻,再好好考虑是否还需要使用sync.Map
这个方案其实就是用反射来帮助我们做类型检查(下面的代码来自于极客时间《go核心36讲》附属源代码)
type ConcurrentMap struct {
m sync.Map
keyType reflect.Type
valueType reflect.Type
}
func NewConcurrentMap(keyType, valueType reflect.Type) (*ConcurrentMap, error) {
if keyType == nil {
return nil, errors.New("nil key type")
}
if !keyType.Comparable() {
return nil, fmt.Errorf("incomparable key type: %s", keyType)
}
if valueType == nil {
return nil, errors.New("nil value type")
}
cMap := &ConcurrentMap{
keyType: keyType,
valueType: valueType,
}
return cMap, nil
}
func (cMap *ConcurrentMap) Delete(key interface{}) {
if reflect.TypeOf(key) != cMap.keyType {
return
}
cMap.m.Delete(key)
}
说实在话,考虑到我们引入sync.Map是为了提升性能,而这里为了通用性引用反射又丢失了部分性能。如果真的需要这么做,建议先好好benchmark避免辛苦半天结果是负优化。
sync.Map实现
简述
简单来说,sync.Map面对的优化场景是写特别少(几乎固定)而并发读特别多的场景。针对这个场景,sync.Map通过内部存储的两个map来实现了优化:分别是键固定的read和包含所有键值对的dirty。所有对read上已有的键值对的增删改查都是无锁实现(read中标记删除的例外,我们之后在展开),考虑到之前提到的“写特别少几乎固定”,也就是说我们基本用不上锁,从而大大提高了性能。
具体实现描述
为了理解实际实现,我们需要明白的是,无论是read还是dirty,他们存储的都是值的地址,而且他们是共享地址的。也就是说所有对read的无锁增删改查都会同步反馈在dirty上。这一点非常重要,否则你无法理解为什么增删改查没有经过dirty而dirty却始终反映最新值
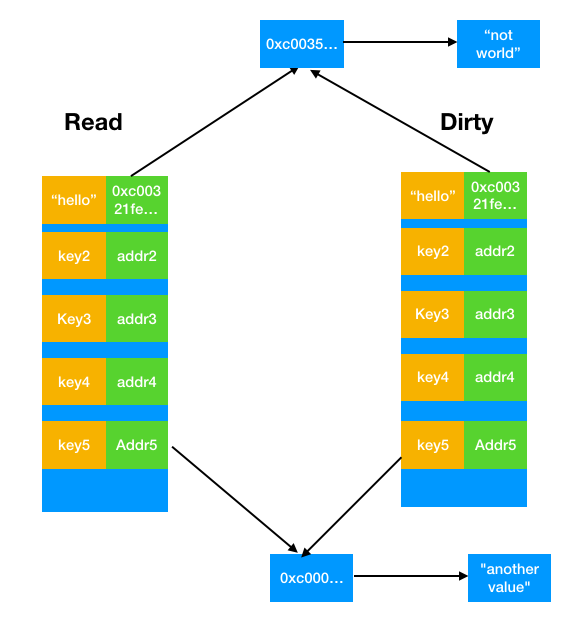
打个比方说,在某个时间点,read和dirty分别存储的内容如下图所示
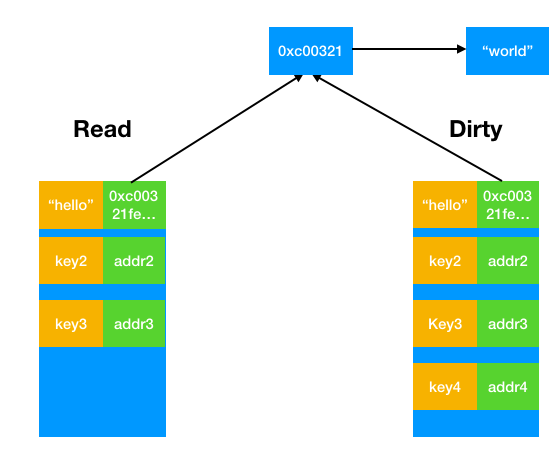
现在,比方说我们调用Store("hello","not world")。我们之前已经提到,如果read中有对应的键,那么不会上锁访问dirty,而是直接无锁替换,也就是说会变成下图所示。可以看到,通过这样的方式,dirty始终反映着最新值,从而为快速切换做准备。
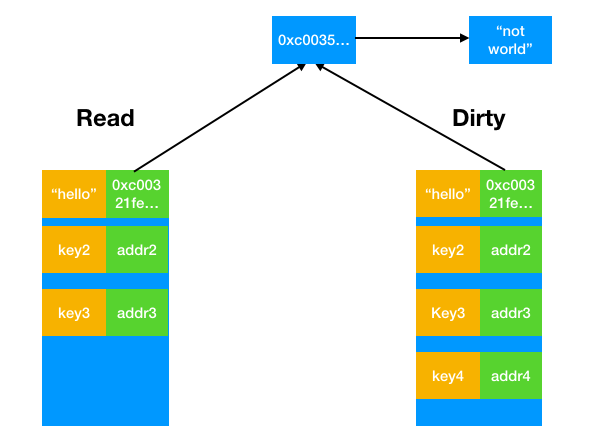
通过上面的分析, 如果我们一直访问read上的键值对,由于不用加锁,性能可以大大提高。但是问题来了,read表是不会更新的,如果后面新增了键值对(写入dirty),然后频繁访问新的键值对,这样不还是不得不加锁访问dirty表吗?而且,read表的数据哪来的呢?难道需要我们在使用sync.Map的时候还要先初始化一个read表吗?
显然不可能有这么奇怪的设置。答案是:如果Load方法调用需要加锁的次数达到一定次数(表示read表的数据太少了),那么sync.Map会设置Read表为dirty表,dirty表为nil。用上图的例子,比方说我们一直频繁调用Load(key4),那么sync.Map就会更换read表
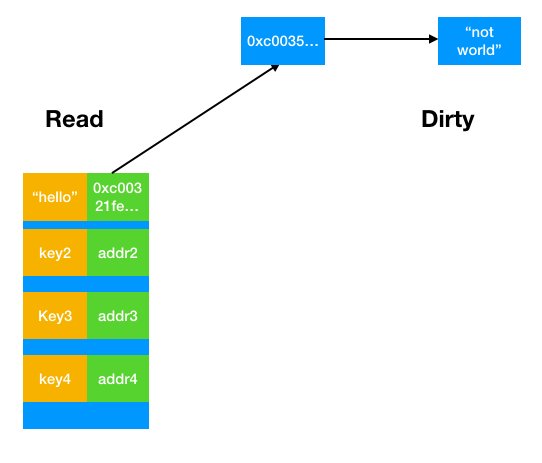
这样我们下次调用Load(key4)的时候,就不再需要加锁访问dirty表了。
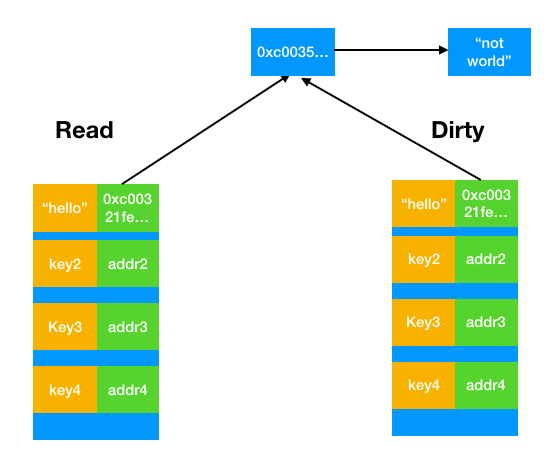
不过可能有些人会奇怪,难道dirty表就会一直为nil状态吗?当然不是,当要求新增read表中没有的键值对的时候,sync.Map会重建新的dirty表。而如果一直没有新增键值对(考虑我们提到的场景,这是很有可能的事情),那么read表就足以应付。
那怎么重建dirty表呢?显然,我们之前提到dirty必须始终包含所有的键值对,因此,我们需要复制read表中的数据,注意这个过程复制的是地址,所以dirty表和read表对同一个键仍然共享地址。
不过我们很快需要处理这么一个问题,由于在没有新增键值对以前,所有的增删改查都在read表中实现。假如说在新增键值对之前我们删除掉了key5,从而使其地址为nil(如下图所示)
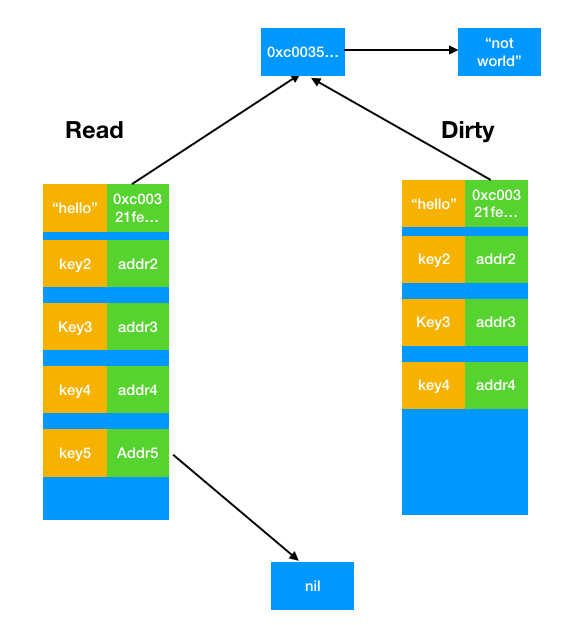
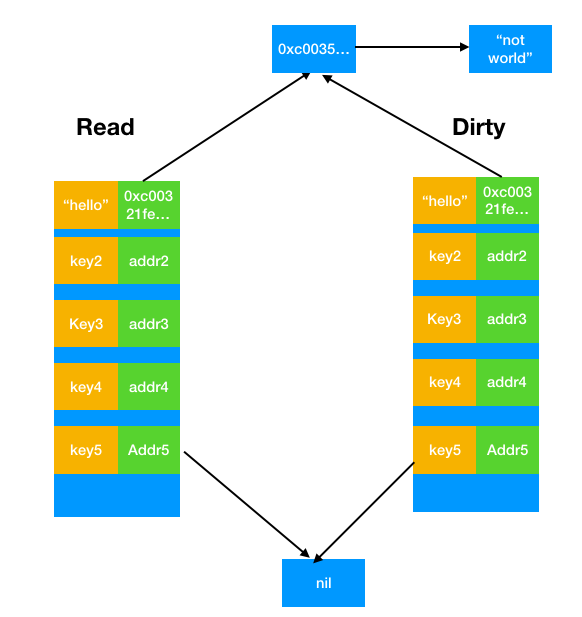
那么重建dirty表的时候我们需要复制key5吗?如果我们选择复制key5,如下图所示,那么当下次出现Store(key5,anotherValue)的时候,我们只需要照常对read表做处理即可实现dirty表的同步更新。但是缺点在于,如果key5再也没有出现过,那么dirty表就会一直保留着一个指针地址(但是用不上),而且考虑到read表从dirty表中转换过来,这意味着这部分内存永远得不到释放,显然是不可接受的。
为了解决这个问题,sync.Map的实现方式是:如果发现read表中有指向nil的,则将其修改为一个特殊标记expunged,然后跳过该键值,如下图所示。
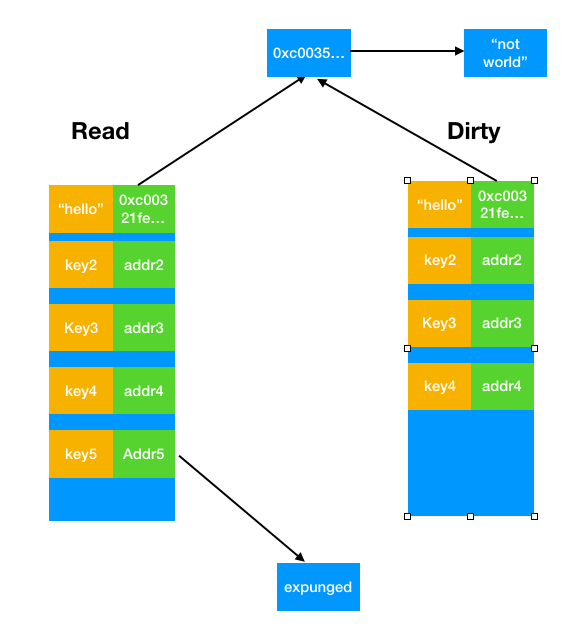
一个可能的情况是key5再也没有出现,这样不仅dirty表节省了空间,而且随着read表转换成dirty表,read表也少了消耗。但是之后出现了Store(key5,"another value")呢?
答案是sync.Map会检查是否有着"expunged"标记,如果是的话,会加锁然后让dirty表先创建对应的键值对(如下图所示)
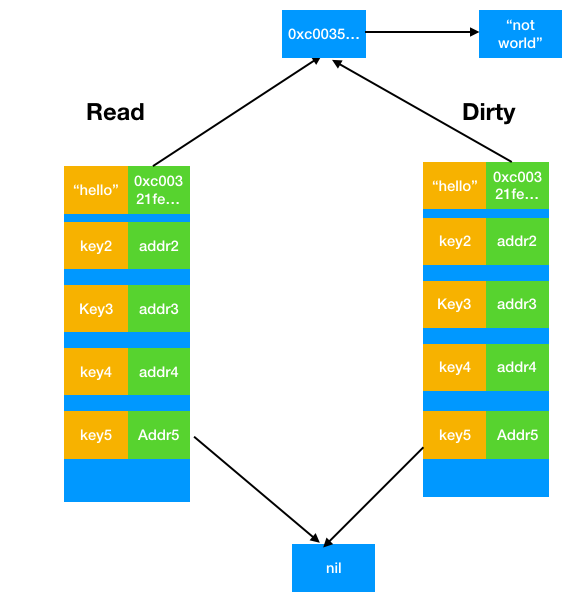
然后在处理更新值的情况
一些其他细节
关于read
具体实现上,read不是一个单纯的map,而是如下图所示的结构体
type readOnly struct {
m map[interface{}]*entry
amended bool // true if the dirty map contains some key not in m.
}
amended的作用是优化,如果amended为false那么dirty表没有新的数据,从而我们可以避免一些不必要的加锁。
关于range
除此之外,Range实现的时候,如果发现read表和dirty表不一致,那么会提前触发一次表替换(因为Range本身时间复杂度为O(N)所以可以分摊部分消耗。Range可以通过返回false提前中断,不过考虑到中间可能涉及到的替换表,时间复杂度不会有太多的变化。
关于kv类型
一般来说,我们尽量避免使用函数、切片、map作为key,因为他们不可比较。
总结
绝大多数时候我们不需要使用sync.Map,sync.Map是基于特定场景高度优化后的结构,如果你不符合上面提到的要求,那么使用map会让生活更轻松点。
