近期看到很多人都在咨询表格转置方面的问题,实际上在之前的博客中,关于数据处理的流程有涉及到通过FME如何进行表格数据的转置处理。既然很多人都在咨询转置的问题,这里就形成一篇定向博客,为大家统一的讲解FME中处理表格转置的几种方法。
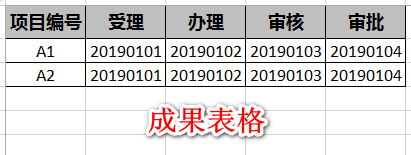
1、原始数据与实现成果

2、FME处理表格转置的方式:
(1)AttributePivoter
(2)Pythoncaller
(3)AttributeTransposer
AttributePivoter
(1) 通过AttributePivoter转换器实现数据的转置,通过Dynamic动态流控制数据输出的结构。
首先想要实现数据转置,在FME里可直接采用AttributePivoter转换器。以测试数据为例,测试数据包括的属性字段:“项目编号”字段为转置的分类字段;“环节”字段为转置后想要输出的属性字段名称;“日期”字段为转置后的属性值。按照测试数据进行数据转置,AttributePivoter转换器的设置如下:

AttributePivoter转换器不仅可以对数据进行转置处理,同时也可对数据进行统计(如上图第4部分参数的内容),如果您在转置的过程中无需进行统计的处理,可以将“Include Grand Total Columns”参数设置为“NO”,即可不输出统计列。
处理后得到的数据如下:

(2)结构输出
根据以上AttributePivoter转换器处理数据的成果大家可以看到,转置之后是不会自动将成果属性字段暴露为用户属性。那么有些用户可能会有疑问,输出的时候如何输出成果字段?
入门一点的方法,可以添加AttributeExposer转换器把需要输出的属性字段都暴露出来再输出。

再通过静态输出到excel表等数据格式中

以上的方式可以得到最终转置后的成果,但是FME经验玩家会发现这种方式不智能,在AttributeExposer转换器时需要手动去设置需要暴露的属性字段,遇到属性字段非常多的时候,这种输出方式过于费时。
大家肯定要疑问,如何有效的解决这种问题?
我们不妨再来分析一下前面的中间结果,对AttributePivoter转换器成果的结果再进行分析,发现本身AttributePivoter转换器转置后生成成果中会自动创建schema属性结构。

不由想到,动态输出方式中支持schema结构输出的方式,是否可以按照动态输出,选择scheme结构的方式动态的保存数据结构。

经过测试,动态输出通过schema保存结构。这种方式解决了AttributeExposer转换器手动暴露字段的烦恼。
当然转置的处理除了AttributePivoter转换器外,还可以采用以下两种方式进行:
Pythoncaller
用PythonCaller转换器调用Python代码来实现。

之前的“FME实现三调地类变化流量表制作”的博客里用的就是PythonCaller转换器编写代码的方式,来完成二调数据结构与三调数据结构不一致时,数据的转换问题。
AttributeTransposer
FME Hub是广大FME爱好者自行封装,分享给大家使用的共享平台。AttributeTransposer为FME Hub所提供的转换器,能够解决简单的表格转置问题。
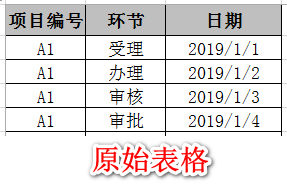

如上图所示,如果数据无需进行分类是,用AttributeTransposer转换器可以直接将表格进行转置,但如果原始数据存在分类,则直接使用AttributeTransposer转换器无法达到正确的效果。
以原始演示数据为例:
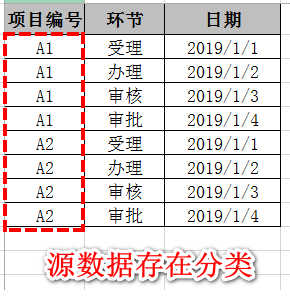
涉及分类的源数据样式无法用AttributeTransposer转换器直接实现。
总结,千人千面,数据是变化多端的,处理方式也是变化多端的,大家可以根据自己的需要进行选择,本篇博客转置的处理方式就介绍到这里。
