偏差
偏差是衡量模型预测值与实际值的偏离程度,例如某模型的准确度为96%,则说明是低偏差;反之,如果准确度只有70%,则说明是高偏差
方差
方差描述的是训练数据在不同迭代阶段的训练模型中,预测值的变化波动情况(或称之为离散情况)。从数学角度看,可以理解为每个预测值与预测均值差的平方和的再求平均数。
通常在模型训练中,初始阶段模型复杂度不高,为低方差;随着训练量加大,模型逐步拟合训练数据,复杂度开始变高,此时方差会逐渐变高。
过拟合,低偏差,高方差,模型太贴合训练数据,导致泛化能力差(泛化能力比较好,比较稳定,方差较小)
模型误差 = 偏差 + 方差 + 不可避免的误差(噪音)。一般来说,随着模型复杂度的增加,方差会逐渐增大,偏差会逐渐减小,见下图:

过拟合、欠拟合和恰好
偏差的变化趋势相信大家都容易理解,随着模型的不断训练,准确度不断上升,自然偏差逐渐降低。但方差的变化趋势却不易理解,为何训练初始阶段是低方差,训练后期易是高方差?
注意方差的数学公式为:E [(h(x) - h(x))2] ,也就是说为每个预测值与预测均值差的平方和再求平均数,可以表现为一种波动变化,低方差意味低变化,高方差意味高变化。那我们可以通过训练的不同阶段来直观感受方差的变化:

上图为训练初始阶段,我们的模型(蓝线)对训练数据(红点)拟合度很差,是高偏差,但蓝线近似线性组合,其波动变化小,套用数学公式也可知数值较小,故为低方差,这个阶段也称之为欠拟合(underfitting),需要加大训练迭代数。

上图为训练的后期阶段,可明显看出模型的拟合度很好,是低偏差,但蓝线的波动性非常大,为高方差,这个阶段称之为过拟合(overfitting),问题很明显,蓝线模型很适合这套训练数据,但如果用测试数据来检验模型,就会发现泛化能力差,准确度下降。
因此我们需要两者之间的一个模型。

上图这个蓝色模型可认为是“恰好”的一个模型,既能跟训练数据拟合,又离完美拟合保持一定距离,模型更具通用性,用测试数据验证会发现准确度也不错
偏差、方差产生原因
一个模型有偏差,主要的原因可能是对问题本身的假设是不正确的,或者欠拟合。如:针对非线性的问题使用线性回归;或者采用的特征和问题完全没有关系,如用学生姓名预测考试成绩,就会导致高偏差。
方差表现为数据的一点点扰动就会较大地影响模型。即模型没有完全学习到问题的本质,而学习到很多噪音。通常原因可能是使用的模型太复杂,如:使用高阶多项式回归,也就是过拟合。
有一些算法天生就是高方差的算法,如kNN算法。非参数学习算法通常都是高方差,因为不对数据进行任何假设。
有一些算法天生就是高偏差算法,如线性回归。参数学习算法通常都是高偏差算法,因为对数据有迹象。
其实在机器学习领域,主要的挑战来自方差。处理高方差的手段有:
降低模型复杂度
减少数据维度;降噪
增加样本数
使用验证集

正则化
什么是正则化
正则化即为对学习算法的修改,旨在减少泛化误差而不是训练误差。正则化的策略包括:
(1)约束和惩罚被设计为编码特定类型的先验知识
(2)偏好简单模型
(3)其他形式的正则化,如:集成的方法,即结合多个假说解释训练数据
在实践中,过于复杂的模型不一定包含数据的真实的生成过程,甚至也不包括近似过程,这意味着控制模型的复杂程度不是一个很好的方法,或者说不能很好的找到合适的模型的方法。实践中发现的最好的拟合模型通常是一个适当正则化的大型模型
参数范数模型
对于线性模型,譬如线性回归、逻辑回归,可以使用简单有效的参数范数模型进行正则化。许多正则化方法通过对目标函数J添加惩罚项,其中α也被称为惩罚系数,限制模型的学习能力:
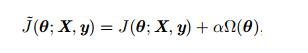
对于神经网络中,参数通常是包括权值w和偏置b,而我们通常对w做惩罚而不对偏置b做处理,这是因为不对b进行处理也不会有太大的影响

为什么通过L1正则、L2正则能够防止过拟合
解释:
过拟合产生的原因通常是因为参数比较大导致的,通过添加正则项,假设某个参数比较大,目标函数加上正则项后,也就会变大,因此该参数就不是最优解了。
问:为什么过拟合产生的原因是参数比较大导致的?
答:过拟合,就是拟合函数需要顾忌每一个点,当存在噪声的时候,原本平滑的拟合曲线会变得波动很大。在某些很小的区间里,函数值的变化很剧烈,这就意味着函数在某些小区间里的导数值(绝对值)非常大,由于自变量值可大可小,所以只有系数足够大,才能保证导数值很大。
2.3 L
L1正则化
所谓的L1正则化,就是在目标函数中加了L1范数这一项。使用L1正则化的模型叫做LASSO回归。
思想:
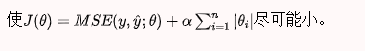 )
)
如果模型过拟合的话,参数θ就会非常大。为了限制参数θ,我们改变损失函数,加入模型正则化,当出现过拟合时,惩罚项也会跟着变大,那么此时代价函数就不是最优解了,θ就被限制住了
在这里有几个细节需要注意:
θ,取值范围是1~n,即不包含。这是因为,不是任何一个参数的系数,是截距。反映到图形上就是反映了曲线的高低,而不决定曲线每一部分的陡峭与缓和。所以模型正则化时不需要。
对于超参数\alpha系数,在模型正则化的新的损失函数中,要让每个都尽可能小的程度占整个优化损失函数程度的多少。即\alpha的大小表示优化的侧重。
L1正则化与稀疏性
这里面有一个特征选择的部分,或者说L1正则化可以使得参数稀疏化,即得到的参数是一个稀疏矩阵。
**所谓稀疏性,说白了就是模型的很多参数是0。**通常机器学习中特征数量很多,例如文本处理时,如果将一个词组(term)作为一个特征,那么特征数量会达到上万个(bigram)。在预测或分类时,那么多特征显然难以选择,但是如果代入这些特征得到的模型是一个稀疏模型,很多参数是0,表示只有少数特征对这个模型有贡献,绝大部分特征是没有贡献的,即使去掉对模型也没有什么影响,此时我们就可以只关注系数是非零值的特征。
这相当于对模型进行了一次特征选择,只留下一些比较重要的特征,提高模型的泛化能力,降低过拟合的可能。
假设在二维参数空间中,损失函数的等高线如下图所示:

此时,L1正则化为|θ1|+|θ2|,对应的等高线是一个菱形(我们可以画出多个这样的菱形):

首先来看一下不加L1正则的情况:我们使用梯度下降法去优化损失函数,随机选择一点,沿着梯度方向下降,得到一个近似的最优解M:

下面加上L1正则,情况则会有所不同。
P,Q两点在同一等高线上,即P与Q两个点的损失函数这一项上是相同的。但是OP的距离要大于OQ距离:

可以得到经验损失函数(损失函数+正则项):
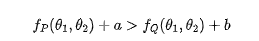
因为Q点的L1范数小于P点的L1范数,因此我们更倾向于选择Q点,而不是P点。
而如果选择Q点,在直角的顶点上,对应的参数θ1=0,这就体现了稀疏性。因此L1正则化会产生系数模型,好处是应用的特征比较小,模型更简单,运算更快。
由此可见:加入L1正则项相当于倾向将参数向离原点近的方向去压缩。直观上来说,就是加上正则项,参数空间会被缩小,意味着模型的复杂度会变小。
L2正则化
岭回归
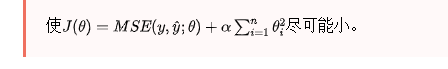
要使代价函数尽可能的小,也要同时使系数θ的和的平方达到尽可能的小
同样地,在二维参数空间中,L2正则项为:
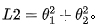 即L2等高线是一个个的同心圆。
即L2等高线是一个个的同心圆。


L2正则求解比较稳定
如图,可以看到,对于L2正则,如果原始的目标函数由于噪声的影响,发生偏移,可以看到,由于L2的约束函数的梯度存在一个变化的范围,比L1正则更容易在原最优解附近找到最优解,而L1正则则求解的变化比较大,因此L2求解更加稳定

