为了在不同应用软件、不同平台、不同操作系统之间实现数据共享,我们需要XML文件来进行数据的储存和传输。
如下所示为一个xml文件内容,定义了一个书店,包含两本书的信息
<?xml version="1.0" encoding="UTF-8"?>
<bookstore>
<book id="1">
<name>冰与火之歌</name>
<author>乔治马丁</author>
<year>2014</year>
<price>89</price>
</book>
<book id="2">
<name>安徒生童话</name>
<year>2004</year>
<price>77</price>
<language>English</language>
</book>
</bookstore>1、解析XML文件
DOM解析
DOM是XML官方提供的与平台无关的解析方式,DOM会一次性将XML文档读入内存并形成DOM树结构,当XML文档过大时对内存消耗较大,而且读取速度受影响。
值得注意的是DOM不仅将一个<tag></tag>视为一个Node节点,而且节点的属性以及换行的空白也视为Node类型,所以在第一个<book>节点调用childNode.getLength()方法时返回子节点数为9,即包括四个<tag>和5个回车换行空白,但是二者的NodeType不同,可以根据类型进行区分两种节点。
同理<name></name>之间的文字也被视为节点,所以要获取其中的文字需要获取name节点的子节点然后再获取文本值。也可以通过getText(Content)方法来获取name节点间的文本内容,效果相同。
import org.w3c.dom.*;
import org.xml.sax.SAXException;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException;
import java.io.IOException;
public class DOMParse {
public static void main(String[] args) throws ParserConfigurationException, IOException, SAXException {
// 1、创建DocumentBuilderFactory对象
DocumentBuilderFactory dbf=DocumentBuilderFactory.newInstance();
// 2、创建DocumentBuilder对象
DocumentBuilder db=dbf.newDocumentBuilder();
// 3、加载xml文件为document对象
Document doc=db.parse("src/com/xml/books.xml");
// 获取所有book节点集合
NodeList bookList=doc.getElementsByTagName("book");
int num=bookList.getLength(); // 获取节点集合的长度
for (int i = 0; i < num; i++) {
Node book=bookList.item(i); // 获取集合中的一个节点
NamedNodeMap attrs=book.getAttributes(); // 获取节点的所有属性
for (int j = 0; j < attrs.getLength(); j++) { // 遍历节点的属性集
Node attr=attrs.item(j); // 获取属性集中的一个属性
System.out.println(attr.getNodeName()); // 输出属性名
System.out.println(attr.getNodeValue()); // 输出属性值
}
// 知道具体属性名时可直接通过属性名获取属性值
Element bookElement=(Element)book; // 此时属性类型从Node转换为Element
String s=bookElement.getAttribute("id");
System.out.println(s);
// 遍历book的所有子节点
NodeList childNodes=book.getChildNodes();
for (int j = 0; j < childNodes.getLength(); j++) {
Node childNode=childNodes.item(j);
// 根据Node类型区分元素节点和文本节点
if (childNode.getNodeType()==Node.ELEMENT_NODE){
System.out.println("节点名:"+ childNode.getNodeName());
// 通过取子节点得到文本值
System.out.println("值为:"+childNode.getFirstChild().getNodeValue());
// 直接获取文本值
System.out.println("文本为:"+ childNode.getTextContent());
}
}
}
}
}
2、SAX解析
SAX是Java官方提供的基于事件驱动的XML解析方式,与DOM加载整篇xml文档解析的方式不同,SAX是边加载XML文档边解析,对内存耗费小。但与DOM树结构相比,SAX访问数据没有结构,不便于理解和编码,而且由于其方法异步执行,很难同时访问不同数据。
使用SAX过程如下,首先创建一个Factory实例,再通过它创建一个parser实例,之后创建一个继承自DefaultHandler类的handler对象,然后通过parser.parse()进行文档解析,传入两个参数,第一个是文档路径,第二个为handler。
public static void main(String[] args) throws ParserConfigurationException, SAXException, IOException {
// 1、获取SAXParserFactory实例
SAXParserFactory factory = SAXParserFactory.newInstance();
// 2、获取Parser实例
SAXParser parser = factory.newSAXParser();
// 3、创建handler实例
SAXHandler saxHandler=new SAXHandler();
// 4、解析文档
parser.parse("src/com/xml/books.xml",saxHandler);
}handler从文档开始遍历,依次调用调用startDocument()、startElement()、characters()、endElement()、endDocument()方法。
startElement()方法在遇到开始标签例如<book>、<author>时触发,其参数qName为标签名,attributes为标签的属性数组
characters()方法在遇到标签之间的字符串时触发,可以定义对字符串的的操作,这些字符串也包括无意义的空白换行
endELement()方法在遇到结束标签</book>时触发

如果需要在以上各个方法之间共享变量和参数,可以通过定义全局变量来实现
import org.xml.sax.Attributes;
import org.xml.sax.SAXException;
import org.xml.sax.helpers.DefaultHandler;
public class SAXHandler extends DefaultHandler {
@Override // 文档开始执行
public void startDocument() throws SAXException {
super.startDocument();
}
@Override // 开始标签执行
public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException {
super.startElement(uri, localName, qName, attributes);
if (qName.equals("book")){ // 解析<book>节点的属性
System.out.println("======book解析开始======");
// 根据具体属性名id获取属性值
String value=attributes.getValue("id");
System.out.println("book的属性值:"+value);
// 未知属性值,遍历所有属性
int num=attributes.getLength();
for (int i = 0; i < num; i++) {
System.out.print(attributes.getQName(i)+" : "); // 获取属性名
System.out.print(attributes.getValue(i)+"---"); // 获取属性值
}
}else {
System.out.print(qName+" : ");
}
}
@Override // 遇到字符
public void characters(char[] ch, int start, int length) throws SAXException {
super.characters(ch, start, length);
String s=new String(ch,start,length);
if (!s.trim().equals("")){ // 排除换行字符串节点
System.out.print(s+" ");
}
}
@Override // 结束标签
public void endElement(String uri, String localName, String qName) throws SAXException {
super.endElement(uri, localName, qName);
if (qName.equals("book")) {
System.out.println();
System.out.println("======book解析结束======");
}
}
@Override // 文档结束执行
public void endDocument() throws SAXException {
super.endDocument();
}
}
运行结果如下:
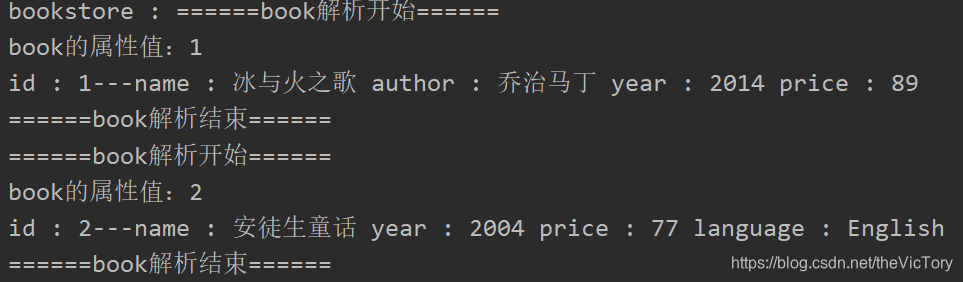
3、JDOM
在SAX基础上,第三方开源组织编写了JDOM与DOM4J两种解析方式,因此在使用JDOM时首先需要首先下载和导入jar包。
通过JDOM的getChildren()方法可以很容易的获取标签的子节点并进行遍历
如下所示从XML中读取到的书籍内容保存到Book对象中,并将对象存储到ArrayList列表中
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.util.ArrayList;
import java.util.List;
import org.jdom2.Attribute;
import org.jdom2.Document;
import org.jdom2.Element;
import org.jdom2.JDOMException;
import org.jdom2.input.SAXBuilder;
import com.imooc.entity.Book; // 引入创建的Book对象
public class JDOMTest {
// 创建用于保存Book对象的列表
private static ArrayList<Book> booksList = new ArrayList<Book>();
public static void main(String[] args) {
// 进行对books.xml文件的JDOM解析
// 准备工作
// 1.创建一个SAXBuilder的对象
SAXBuilder saxBuilder = new SAXBuilder();
InputStream in;
try {
// 2.创建一个输入流,将xml文件加载到输入流中
in = new FileInputStream("src/res/books.xml");
InputStreamReader isr = new InputStreamReader(in, "UTF-8");
// 3.通过saxBuilder的build方法,将输入流加载到saxBuilder中
Document document = saxBuilder.build(isr);
// 4.通过document对象获取xml文件的根节点
Element rootElement = document.getRootElement();
// 5.获取根节点下的子节点的List集合,并进行遍历
List<Element> bookList = rootElement.getChildren();
for (Element book : bookList) {
Book bookEntity = new Book();
System.out.println("======开始解析第" + (bookList.indexOf(book) + 1)+ "书======");
// 解析book的属性集合
List<Attribute> attrList = book.getAttributes();
// //知道节点的属性名称时,获取节点值的方法
// book.getAttributeValue("id");
// 遍历attrList(针对不清楚book节点下属性的名字及数量)
for (Attribute attr : attrList) {
// 获取属性名
String attrName = attr.getName();
// 获取属性值
String attrValue = attr.getValue();
System.out.println("属性名:" + attrName + "----属性值:"+ attrValue);
if (attrName.equals("id")) {
bookEntity.setId(attrValue);
}
}
// 对book节点的子节点的节点名以及节点值的遍历,并将信息保存到Book对象
List<Element> bookChilds = book.getChildren();
for (Element child : bookChilds) {
System.out.println("节点名:" + child.getName() + "----节点值:" + child.getValue());
if (child.getName().equals("name")) {
bookEntity.setName(child.getValue());
}
else if (child.getName().equals("author")) {
bookEntity.setAuthor(child.getValue());
}
else if (child.getName().equals("year")) {
bookEntity.setYear(child.getValue());
}
else if (child.getName().equals("price")) {
bookEntity.setPrice(child.getValue());
}
else if (child.getName().equals("language")) {
bookEntity.setLanguage(child.getValue());
}
}
System.out.println("======结束解析第" + (bookList.indexOf(book) + 1)+ "书======");
booksList.add(bookEntity);
bookEntity = null;
System.out.println(booksList.size());
// 输出保存在列表中的第一个对象的id和name
System.out.println(booksList.get(0).getId());
system.out.println(booksList.get(0).getName());
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (JDOMException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
4、DOM4J
DOM4J也是第三方开源的工具包,与JDOM相比拥有更快的执行速度和灵活性
可以通过elementIterator()方法获取标签的子节点迭代器,从而实现对节点的遍历,其使用方法如下:
package com.imooc.dom4jtest;
import java.io.File;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
import org.dom4j.Attribute;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
public class DOM4JTest {
public static void main(String[] args) {
// 创建SAXReader的对象reader
SAXReader reader = new SAXReader();
try {
// 通过reader对象的read方法加载books.xml文件,获取docuemnt对象。
Document document = reader.read(new File("src/res/books.xml"));
// 通过document对象获取根节点bookstore
Element bookStore = document.getRootElement();
// 通过element对象的elementIterator方法获取迭代器
Iterator it = bookStore.elementIterator();
// 遍历迭代器,获取根节点中的信息(书籍)
while (it.hasNext()) {
System.out.println("=====开始遍历某一本书=====");
Element book = (Element) it.next();
// 获取book的属性名以及 属性值
List<Attribute> bookAttrs = book.attributes();
for (Attribute attr : bookAttrs) {
System.out.println("属性名:" + attr.getName() + "--属性值:"
+ attr.getValue());
}
Iterator itt = book.elementIterator();
while (itt.hasNext()) {
Element bookChild = (Element) itt.next();
System.out.println("节点名:" + bookChild.getName() + "--节点值:" + bookChild.getStringValue());
}
System.out.println("=====结束遍历某一本书=====");
}
} catch (DocumentException e) {
e.printStackTrace();
}
}
}
2、生成XML
DOM生成
DOM会在内存中创建DOM树来暂存节点结构,因此如果需要频繁修改DOM结构的话使用DOM比SAX更合适,但相应地,其创建速度是四种方法中最慢的,SAX方法则是最快的。
使用DOM首先还是需要生成document对象,然后通过document创建节点,之后使用父节点添加子节点。
最后通过Transformer对象的transform()方法生成XML文件,transform()需要两个参数,第一个为要输出的源文档,第二个为输出文件流
public static void main(String[] args) throws ParserConfigurationException, TransformerException {
// 通过嵌套定义创建一个DOM文档对象doc
DocumentBuilderFactory dbf=DocumentBuilderFactory.newInstance();
DocumentBuilder db=dbf.newDocumentBuilder();
Document doc=db.newDocument();
// 通过doc创建节点
Element bookstore=doc.createElement("bookstore");
Element book=doc.createElement("book");
book.setAttribute("id","1"); // 为节点添加属性
Element name=doc.createElement("name");
name.setTextContent("百年孤独"); // 添加节点之间的文本内容
// 将子节点添加到父节点
book.appendChild(name);
bookstore.appendChild(book);
doc.appendChild(bookstore);
// 通过Transformer对象输出xml文件
TransformerFactory tff=TransformerFactory.newInstance();
Transformer tf=tff.newTransformer();
tf.setOutputProperty(OutputKeys.INDENT,"yes"); // 设置输出xml文件换行
DOMSource domSource=new DOMSource(doc); // 要输出的文档对象
StreamResult streamResult=new StreamResult(new File("src/com/xml/DOMout.xml")); // 输出的目标文件
tf.transform(domSource,streamResult);
}SAX生成
使用SAX生成同样需要首先通过嵌套定义生成一个handler与Transformer对象,通过transformer可以对输出文件进行设置,通过handler可以对文档进行操作。在操作文档之前需要将handler和输出文件流进行关联。
之后通过handler调用相关方法对文档进行编辑,像tag标签一样,startElement/endElement方法成对使用。通过attr对象来设置和添加标签的属性。通过characters()方法来添加标签之间的文本内容。
public static void main(String[] args) throws TransformerConfigurationException, FileNotFoundException, SAXException {
// 生成SAX的Transformer对象
SAXTransformerFactory stf=(SAXTransformerFactory)SAXTransformerFactory.newInstance();
TransformerHandler handler=stf.newTransformerHandler();
Transformer transformer=handler.getTransformer();
transformer.setOutputProperty(OutputKeys.ENCODING,"UTF-8"); // 设置输出属性
// 创建Result对象并与handler关联
Result result=new StreamResult(new FileOutputStream(new File("src/com/xml/SAXout.xml")));
handler.setResult(result);
// 通过handler编辑xml文件
handler.startDocument();
AttributesImpl attr=new AttributesImpl(); // 创建用于编辑节点属性的attr对象
handler.startElement("","","bookstore",attr); // 结点开始
attr.clear(); // 每次新设置一个属性attr之前都需要清空之前的
attr.addAttribute("","","id","","1"); // 定义attr并添加到节点
handler.startElement("","","book",attr);
attr.clear();
handler.startElement("","","name",attr);
String s="平凡的世界";
handler.characters(s.toCharArray(),0,s.length()); // 向节点间添加文本
handler.endElement("","","name"); // 结束节点
handler.endElement("","","book");
handler.endElement("","","bookstore");
handler.endDocument();
}DOM4J生成
DOM4J创建速度虽然慢于SAX,但是快于JDOM,而且其代码较为简洁,是开发中常用的解析与生成方式。
DOM4J创建document对象之后可以直接添加节点,而且由于是封装好的库,代码调用相比之前SAX与DOM方式来说十分简洁。节点的创建和属性的添加等操作只需要一行代码。通过XMLWriter将文档输出,writer()接受两个参数,第一个为文档输出流,第二个可选参数为format对象,通过format可以自动设置好输出的回车换行等空格。
package com.xml;
import org.dom4j.Document;
import org.dom4j.DocumentHelper;
import org.dom4j.Element;
import org.dom4j.io.OutputFormat;
import org.dom4j.io.XMLWriter;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
public class DOM4jGenerator {
public static void main(String[] args) throws IOException {
// 创建DOM4J文档对象
Document document=DocumentHelper.createDocument();
// 从上到下创建节点
Element bookstore=document.addElement("bookstore"); // 创建并添加子节点
Element book=bookstore.addElement("book");
book.addAttribute("id","1"); // 添加节点属性
Element name=book.addElement("name");
name.setText("冰与火之歌"); // 设置标签之间的文本
OutputFormat format= OutputFormat.createPrettyPrint(); // 设置输出文档的格式
format.setEncoding("UTF-8");
// 将文档输出
FileOutputStream outputStream=new FileOutputStream(new File("src/com/xml/DOM4Jout.xml"));
XMLWriter writer=new XMLWriter(outputStream, format);
writer.write(document);
writer.close();
}
}
JDOM生成
和DOM4J一样JDOM也是库,不过它需要先new节点,然后通过父节点调用addContent()添加子节点
import org.jdom2.Document;
import org.jdom2.Element;
import org.jdom2.output.Format;
import org.jdom2.output.XMLOutputter;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
public class JDOMGenerator {
public static void main(String[] args) throws IOException {
Element bookstore = new Element("bookstore"); //创建根节点
Document document = new Document(bookstore); // 将根节点添加到document对象
// 创建并添加子节点
Element book = new Element("book");
book.setAttribute("id", "1"); // 为节点添加属性
bookstore.addContent(book); // 父节点添加子节点
Element name = new Element("name");
name.setText("冰与火之歌");
book.addContent(name);
// 输出文档
Format format = Format.getPrettyFormat(); // 设置输出格式
format.setEncoding("GBK");
XMLOutputter outputter = new XMLOutputter(format); // 可以传入格式设置对象作为参数
FileOutputStream outputStream = new FileOutputStream(new File("src/com/xml/JDOMout.xml"));
outputter.output(document, outputStream);
}
}
