注意: 在IDEA上运行WordCount实例之前我们要在本地Windows上配置Hadoop环境。
一、环境配置
(1)在windows上安装hadoop之后,把hadoop文件放到和JAVA文件一致的目录中:

(2)配置hadoop环境变量:

二、创建项目
(1)新建Maven


(2)导入pom文件:
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>RELEASE</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.8.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.2</version>
</dependency>
</dependencies>(3)新建三个class:
WCMap.java
WCReduce.java
WCDriver.java
WCMap.java:
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* Author : 若清 and wgh
* Version : 2020/4/12 & 1.0
*/
public class WCMap extends Mapper<LongWritable, Text,Text, IntWritable> {
//实现父类的快捷键 alt+insert(INS)
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//获取一行数据
String line = value.toString();
//切分数据,按照空格切分
String[] fields = line.split(" ");
//遍历获取每个单词
for (String field : fields){
//输出,每个单词拼接 1(标记) (java(K) 1(V))
context.write(new Text(field),new IntWritable(1));
}
}
}WCReduce.java:
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* Author : 若清 and wgh
* Version : 2020/4/12 & 1.0
*/
public class WCReduce extends Reducer<Text, IntWritable,Text, IntWritable> {
//实现父类方法快捷键 ctrl+o
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
//定义一个计数器
int count = 0;
//累加计数
for (IntWritable intWritable : values){
//intWritable转化成int
count+=intWritable.get();
}
//输出
context.write(key,new IntWritable(count));
}
}WCDriver.java:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
* Author : 若清 and wgh
* Version : 2020/4/12 & 1.0
*/
public class WCDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//实例化配置文件
Configuration configuration = new Configuration();
//定义一个job任务
Job job = Job.getInstance(configuration);
//配置job的信息
job.setJarByClass(WCDriver.class);
//指定自定义的mapper类以及mapper的输出数据类型到job
job.setMapperClass(WCMap.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//指定自定义的reduce以及reduce的输出数据类型(总输出的类型)到job
job.setReducerClass(WCReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//配置输入数据的路径
FileInputFormat.setInputPaths(job,new Path("D:\\input\\plus\\wordcount.txt"));
//配置输出数据的路径
FileOutputFormat.setOutputPath(job,new Path("D:\\input\\plus\\output\\0811"));
//提交任务
job.waitForCompletion(true);
}
}(4)运行程序:
 (5)结果显示没出错,查看输出路径是否有文件:
(5)结果显示没出错,查看输出路径是否有文件:

(6)查看生成文件内容“part-r-00000”:
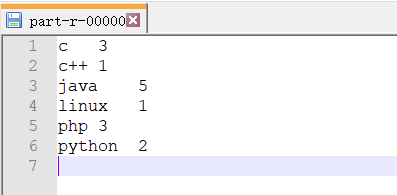
至此,已完成在(Windows)IDEA上运行WordCount实例。