
用另外的模板试试,大部分查的数据都是越多越好,不仅仅是拿到标题,比如电影,查找7分以上的电影有哪些。可以把详情页的url拿到,构造成request放到scheduler,要对电影的详情页做分析,比如对热点新闻做分析。
比如书的好评很多,但是不知道好在哪里,就可以分析评论里出现的重点词汇,才知道好在哪里

如何scrapay提供的另外模板,提取这里的链接,刚才是手动的建立链接,来构造request开始爬取的

再创建一个项目

这里就多了一个项目,blog12是项目根目录。mspider就是项目包目录

先修改settings,不遵从协议,否在会下载这个网站的robots协议,下载之后如果你发起的链接,如果是符合你协议里禁止的,就不去爬取 了

修改user-agent

网站如果发现你短时间内同一个ip频繁去链接,而且是一下子发送这么多并发链接,就要考虑是否把你禁止掉了,所以这里暂时不加

不用cookie

这两项其实可以测试的时候先配置,比如限制浏览器一共发送给5个,模拟浏览器3,4个都没什么问题,当你下载网页的时候碰到css,script,图片。其实就是发送新的请求

首先把item两个写一下,这样item写好了

下面写spider,指定crawl模板,book爬虫名字,再douban。com域里

这次跟上次不一样了,以前基于scrapy。spider,现在是crawlspider

crawlspider是基于spider的

spider是scrapy下的spider

crawlspider就是spider的子类,spider的名称,域,start_url是少不了的

看一下parse_item

父类里有个parse,没看到parse_item

之前的book,这个paese是父类spider里有的,有的就是在做overwrite

crawlspider里重写了parse方法

这个类机车给自spider,没有parse_item,但是有parse,父类没实现,子类来实现

bookspider相当于孙子类,可以不写parse,因为crawlspider已经继承了,有了parse
这个是callback回调,这是一个规则

这是一个规则,叫链接提取器,它只关心a标签,a标签叫链接,他去访问a标签,然后把a标签抽取出来,会把链接中的href属性抽取出来,抽取处理会将这个东西扔给scheduler,但是之前要封装成request,然后request被调度到downloader,由downloader下载后由response,response谁来解析,就是callback。这个callback的意思是,你抽取出来的链接,下载完之后,内容谁来解析的回调,其实是下载后的内容解析回调函数

就是前面这个链接一旦去下载后生成的response,这个response交给callback来管理

follow指的是,这个链接下载完之后,链接对应的页面被下载了,这里面的链接要不要再次提取,follow,如果是false就是当前页面再也不提取了

这是来定义这个规则的,你要抽取谁,抽取之后下载的内容要回调,你面的链接继续跟踪

这个方法是上一部分内容下载后的内容的回调,这个模板跟之前的模板的工作方式完全不同

**这个response还是scrapy.http.response只不过为了方便加了html。其实就是htmlresponse
**

这个东西不是parse,parse是父类的方法

这边可以随便写,但是左边不可以 随便写


这样就是在页面里不抽取链接了,以后就没什么可以链接了,就不会调用回调函数,现在相当于没有抽取任何链接,既然没有链接,就不存在链接被下载封装回调的事情


现在的配置文件时mspider的,不会到firstpro里去
来试试,list由谁的名字就可以去爬谁

这个链接就是start_url

200代表response来了,但是紧接着close掉了,因为现在是无事可做,准备抽取链接,但是你的规则是空的,没写就是没事干,不会抽取url,也就不会调用回调函数


爬虫跑起来,start没什么说的,爬取下来没有做事情,不parse,现在是把整个处理方式改变了,但是这一页拿来了,分析链接,结果一个链接没有

从response中的a标签提取href,如果href符合正则表达式,就会提取出合格的url,并且将这个url再次封装成request对象,放在scheduler中,然后由scheduler放到downloader,然后由downloader拿到response回来,再调用parse_item

改成false,避免封

开4个,做一下延迟


重新运行一下

依然什么都没做

是因为这个正则表达式,里面没有链接

现在这么写

现在就有效果了


它就会分析所有带这个东西的
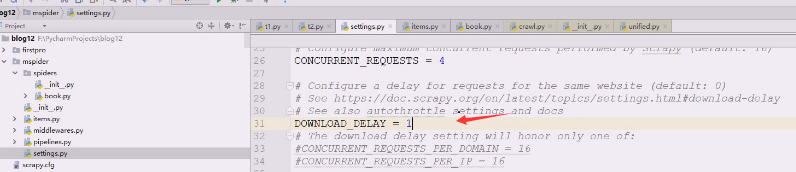
 2太慢了,改成1
2太慢了,改成1
运行一下

看现在的链接是否你想要的

说明当前的response访问的是

response.url是这一页

对起始页提取到的所有的符合外面条件的链接都过了一把,都分别做了请求,,拿到了他们的内容,才能把url打出来

**首页只对链接做了提取,并且将符合的链接扔到了scheduler,由scheduler跑到下载器downloader,由下载器分别下载,一旦response则调用parse_item回调函数。
**
response里面现在会帮你自动 抽取链接,现在可以给需要一个parse函数,新的链接靠这个来解决即可

只要match返回true就封装到scheduler

首页既分析了内容,又抽取了链接,然后抽取链接到第二页,又把首页的链接取回来了,但是现在,第一页就不分析内容,第一页就是抽取起始链接,抽取链接就是分别下载,然后调用回调,如果要跟踪继续跟踪,不跟踪就拉倒

尤其是多页处理可能更愿意用模版

bookitem没有需要重写

重写下bookitem

导入bookitem

该怎么分析还是怎么分析,主要是链接不用管了

现在要存储下来,用custom_settings看看有没有,点击crawlspider查看源码


如果没有就给一个空字典
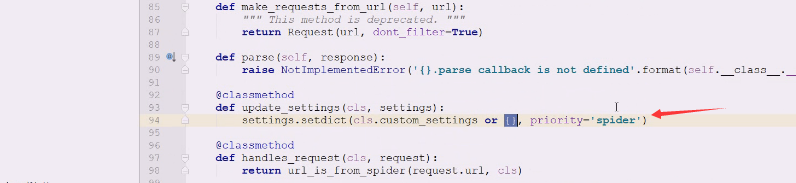
这样就写成字典,临时的配置可以在这里写

把pipeline的东西复制一下

照抄一下

这些spider都将item打个引擎,引擎一看是item就转发给了item pipeline,这里的itempipeline实际上是不知道是哪个spider的,spider有抓取的不同域名

如果有多个spider是要区分一下,不同的spider要做区分

根据当前spider的名称来判断是否能使用这边的代码,在这里必须有文件名

把这里替换掉就可以做处理了

可以打印看一下它是谁
 、是打开spider的函数,跟pipeline初始化无关,所有spider的数据都会经过它,就可以通过spider的一些名称和特殊的值,然后自己来决定如何处理
、是打开spider的函数,跟pipeline初始化无关,所有spider的数据都会经过它,就可以通过spider的一些名称和特殊的值,然后自己来决定如何处理

打开mspider的settings把pipeline打开

最后通过settings把filename也可以拿到

爬完没什么可爬的就停止了


爬了8页,就是160个

这里依然yield,回调函数其实是会被包裹住的,最后还是走parse,直接yield向后扔,扔给engine,engine一看是item就甩到item pipeline里了

最终得到这个文件

这里的字符是unicode字符,不是utf-8的,这些数据加载进来直接变中文了






一开始测试要把并发和链接时长控制下,要看item就可以用表达式就可以看到里面内容了,数据真正用的时候要用dict包一下

可以看一下crawl模版

是对链接的抽取做了规则,怎么去处理就需要靠回调,里面数据是否要再跟踪

这个parse是父类里还有,不要轻易使用这个名字,你使用了就改变了数据的流向方式,链接不需要你处理,在rules里写即可

这里 的rate可能没得分,最后是有点问题

可以改成这样,这样吧数据抽取出来,返回的是列表()前面会的是selectorlist),if rate就是判断里面有没有元素,如果没有评分,这里就是空列表了

没数据就给个0,这个列表所有数据都是文本的,字符串,有数据就取一个元素相当于extract_first

爬取流程,会先发起链接start_urls,只会把response里的内容,按照规则抽取里面的链接,对这些链接封装之后放到scheduler,最后放在下载器里下载,下载之后得到的请求,第一批链接但凡有一个连接response回来,下面就要执行回调

在回调中,response对象就可以进行处理了,分析出我们要的数据,最后yield出去

一旦改成true,就需要反爬了

这里其实就是告诉你不允许爬了,当你爬取太多,再次登录的时候,你的账号可能就被封了,我们可以用换ip代理

最好由中间件交给代理发起请求,封的也是代理ip不是你自己的ip,就是去往downloader的路上给request请求进行处理

看下中间件,downloader中间件有这么多,

不但能处理请求还能处理downloader响应

现在修改request

复制一下

复制到下面改一下名字


在设置里照着写

downloader发起请求经过proxy,由proxy去访问即可

修改所有请求全部走代理

可以return好结果值,rerurn none相当于继续处理这个请求,相当于现有流程不变化,穿透当前的中间件继续向后走,如果之后的中间件都可以穿透,就可以走downloader了
request的意思 是(返回request相当于半路改变了request,把这个request重新走一遍

现在写了return request对象,直接从中间件回头再来一遍,如果都允许,再downloader,如果再这里return一个request对象,则重新开始,对这个request对象,重新爬取。
你自己封装的request是什么,再走一遍中间件,再来访问downloader,可能里面的url变了,以前访问a,现在可能访问b
、
看一下官方文档

如果是一个response,将不再调用其他的request,或者是异常处理的方法,直接交给downloader函数

它这里直接不处理,交给downloader,downloader看到response都有了,就直接交给parse方法,就把这个response直接解析了

重新写个spider测试

访问get就做这一件事情

再在中间件里写一个

加到配置文件里,在上面的后面

导入一个response

response有了,是所有中间件的process_request就不管了

相当于在中间件的时候就构造出一个response

在请求阶段就告诉response,然后看after如何处理

运行一下

把pipeline关掉

再次运行

现在就看不到after

会把after和处理异常的方法绕过

测试返回response怎么走就在前面加before中间件,就知道怎么走的

中间件就这么写,把after删除

spider中间件也是这么测试

这里有个免费代理,每天20个
用户名密码

生成链接后

点击打开链接

能用的就这么多

复制一个试试

写好代理

每发起一个请求就从ip里随便拿一个

这里是从scheduler拿到就是request请求,所以就是scrapy.http.request的Request类,下面所谓的错误会调用异常处理,很少用

这是相当于把请求头改了

如果代理成功访问这个网站的时候,ip就是代理的

修改下之前的text直接用

只保留这个中间件

这里是选一个代理,然后在meta里加入头,把i请求给代理,由代理请求目标地址

如果家里被封 了,就重启一下路由器

好像不能用


重新打开一次就换掉了

修改地址

中间件return none,IP如果5分钟过期,你就再取刷新一次
 、
、
打印一下日志,是因为没有认证,proxy是谁不认识,所以我们需要把自己的ip放到白名单里去

把自己的ip放到白名单

再次生成一个链接



运行一下

这个代理可能有点问题,换一下


这样就ok了

我们到时候就自己做一个ip列表,下一次随便挑一个

用了代理。这里就可以大胆改成true

数据写出去把book名字修改一下

settings里把并发和延迟时间注释掉,但是合适一点

启用pipeline存一下



50页
可以在item-pipeline可以写第一层做一些过滤,第二层mysql,第三层打入redis

第一个反爬策略就是伪造自己的useragent
第二个尽量模拟人为操作
第三个使用代理,ip池

你一个操作一群proxy,都可以链接那个网站,网站是很难处理的





用户名密码
**这个spider,起始ip只提取url,新的url放到爬取队列里,爬取队列可以去重,可以导出url去downloader,去下载,经过中间件可以改代理,这样发起请求response之后才可以调用回调,就会把第一次爬过来的数据,挨个做解析,如果写了follow=tRUE,就会将你返回的新页面再去抽取url,再去放到待爬取队列里,也会去重,当待爬取队列没有可爬的就可以停止了
**

