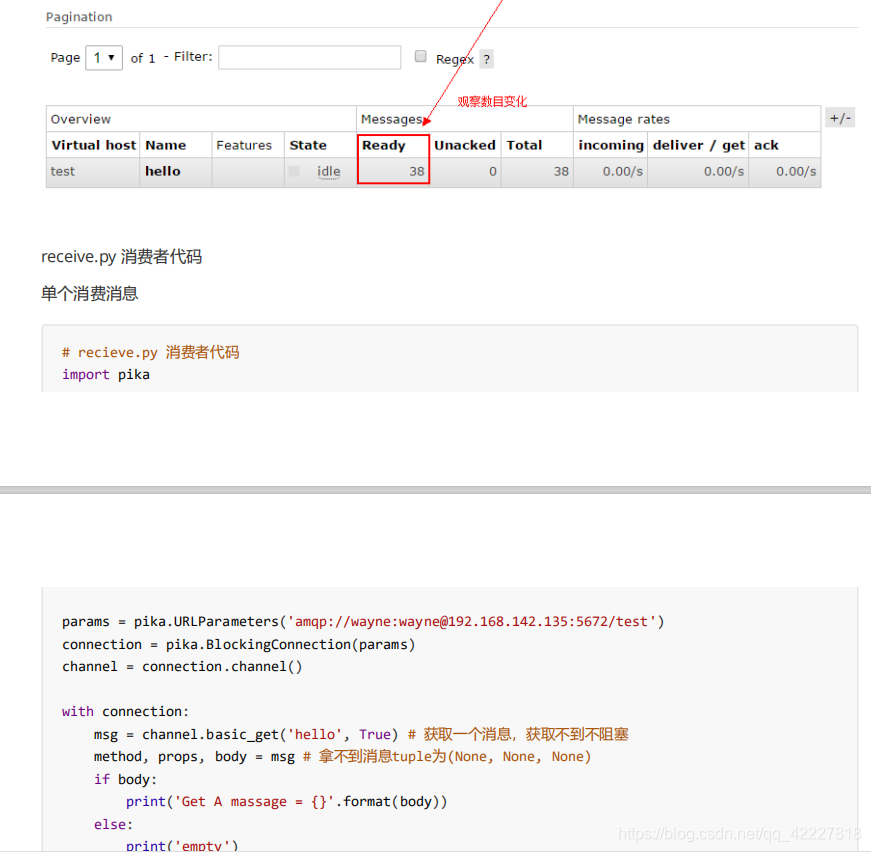
rabbitmq启动端口5672,15672,25672就代表成功了,登录web界面可以看到管理的东西,有一些概念名词;
工作方式有如下几种,1,2,3,4,5是很重要的,在官网上可以看到文档,底下选择相应的语言即可,amqp是标准协议


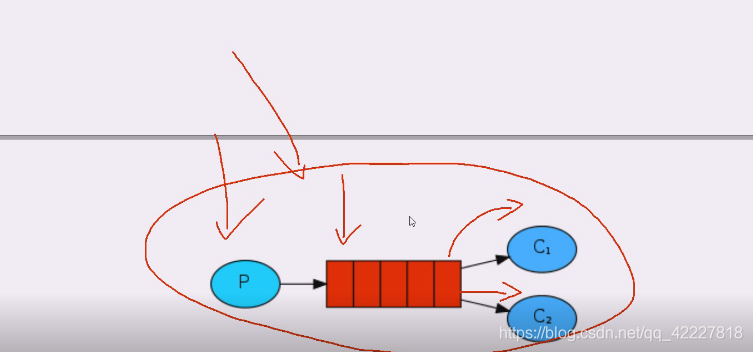
名词有几个概念很重要,生产者和消费者,队列的服务器称为server和broker,建立链接要使用通道,里面有虚拟主机,虚拟主机下可能包含交换机和queue,交换机和queue之间要绑定,好在有一个缺省的虚拟主机

第一种工作方式
第一种工作方式称为队列,使用生产者链接到rabbitmq,链接以后把数据打入到消息队列里去,是一个FIFO先进先出的队列,消费者链接到消息队列,并从里面获取数据
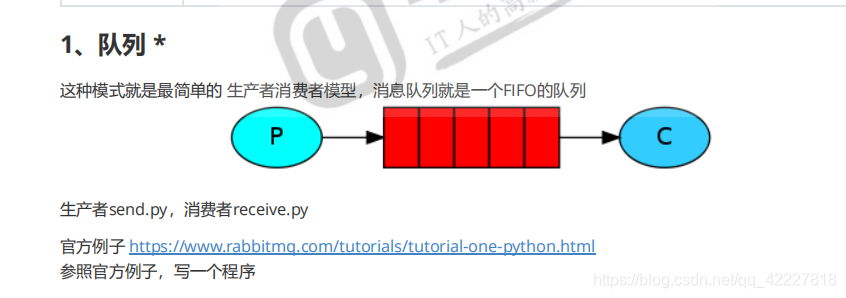
首选要安装pika,安装好就可以使用了
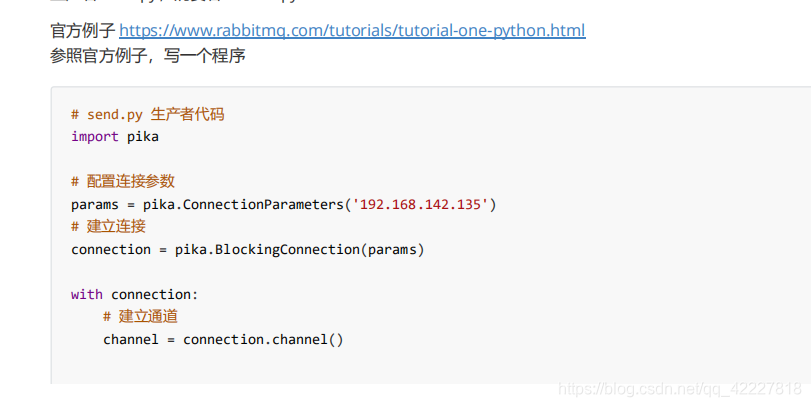

链接参数
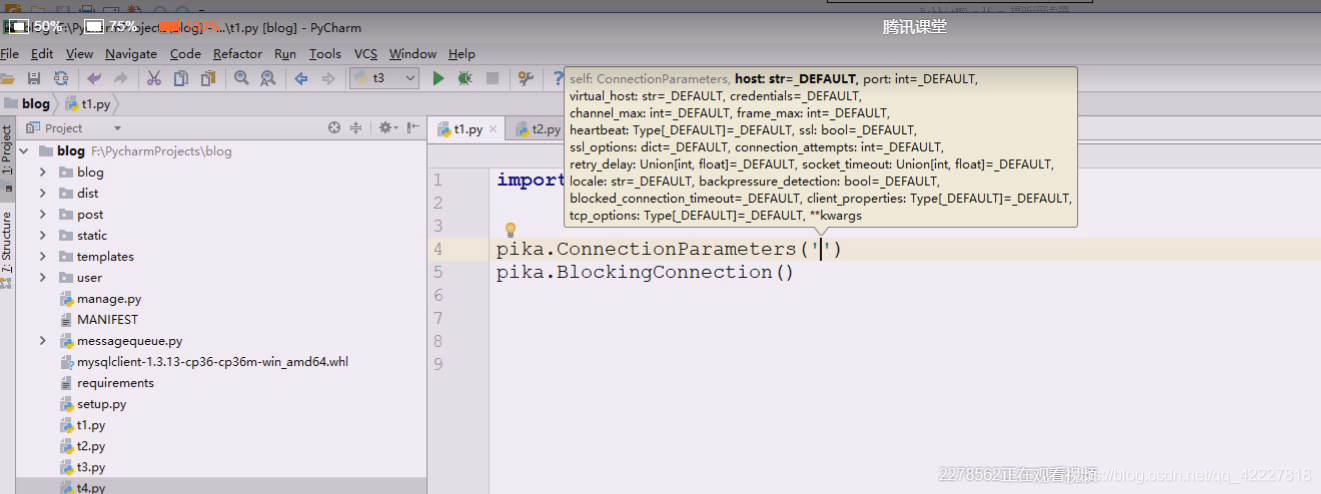
第一步就是创建链接
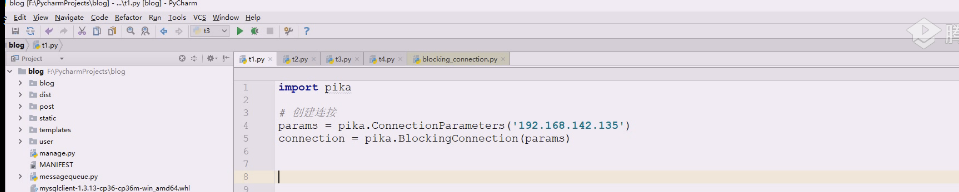
需要得到一个channel,很重要下面所有的操作从channel开始做
看看这个链接
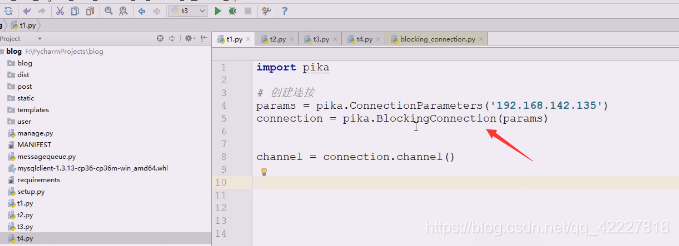
看到enter和exit,链接要还回去资源,所以链接一定会带有这个东西
可以使用with
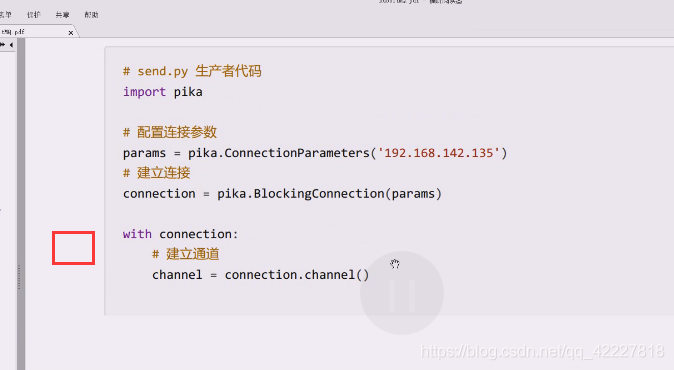
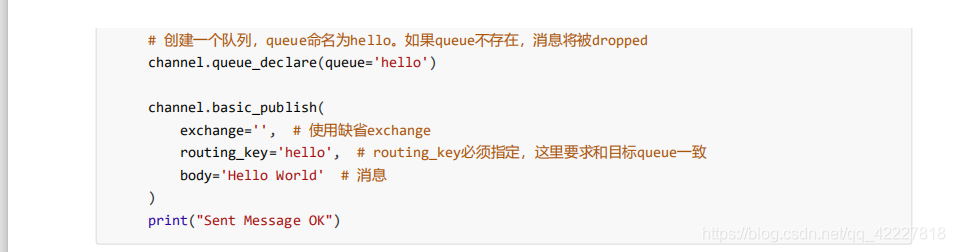
创建一个队列是在channel上做的
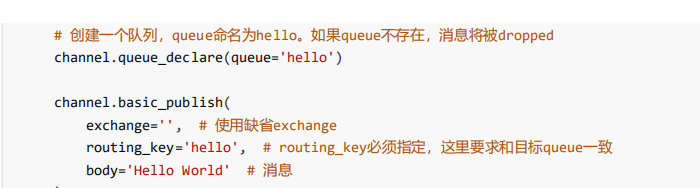
这里不叫定义,叫队列申明
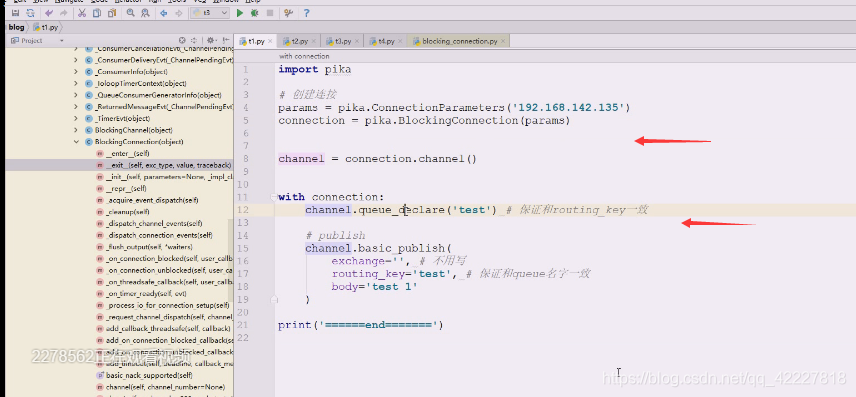
队列下就可以往里面打数据,publish(第一个参数告诉交换机exchange是谁,routing_key
交换机现在不知道,路由的key也不知道,body消息体,body等于你的消息
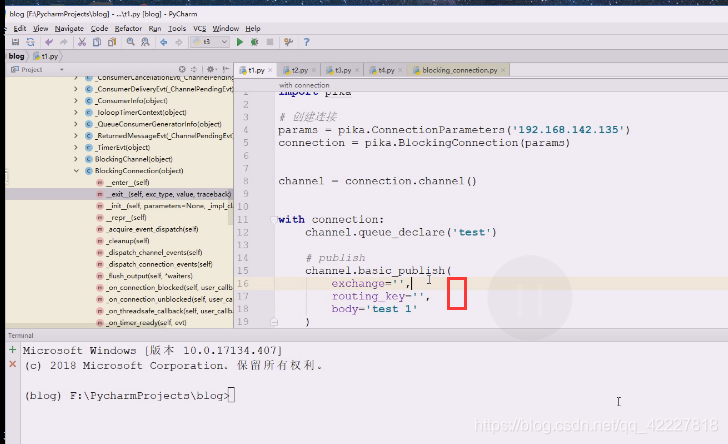

上面这个图目前没有交换机,还不用写,routing-key不写,去哪里都不知道,,在这种情况下保证和routing-key一致
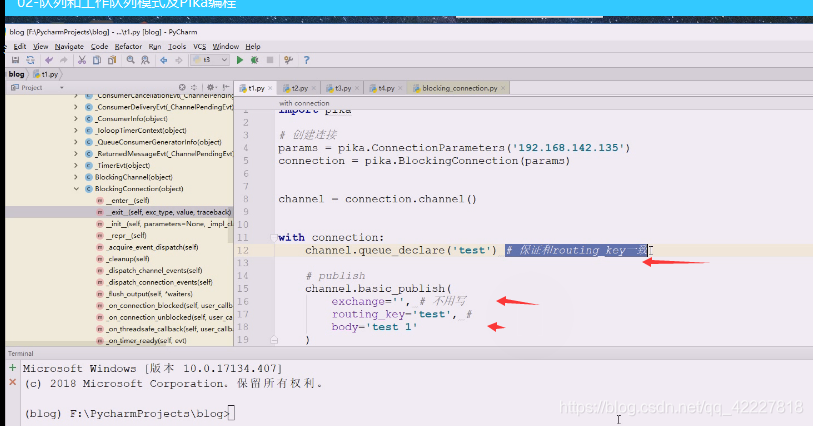
应该routing-key在这种情况下保证和queue名字一致,,上面就是链接之后满足权限,就创建了一个queue
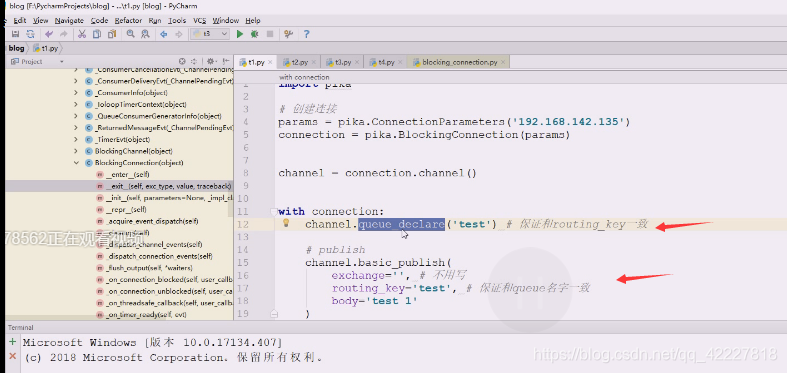 发完了一条消息
发完了一条消息
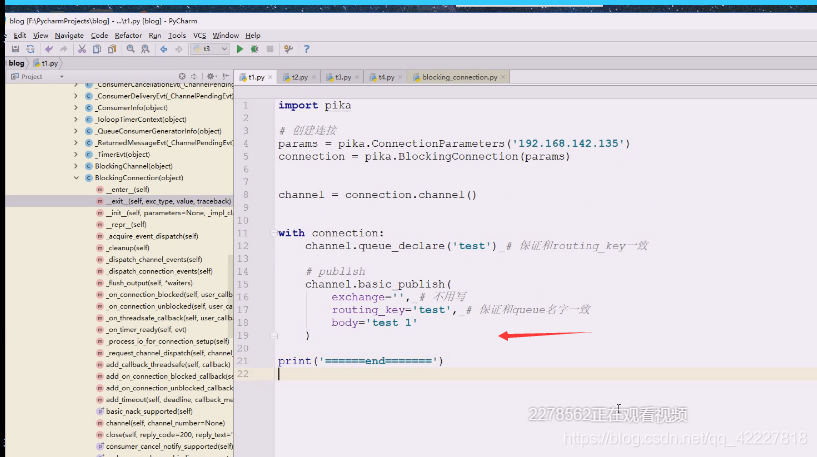
链接到服务器,剩下全是缺省,然后创建channel通道。
在channel通道就可以建立会话,然后创建一个queue出来,最后给里面打入数据
现在没有消费者可以把数据先打入到里面

默认都是链接缺省虚拟主机的
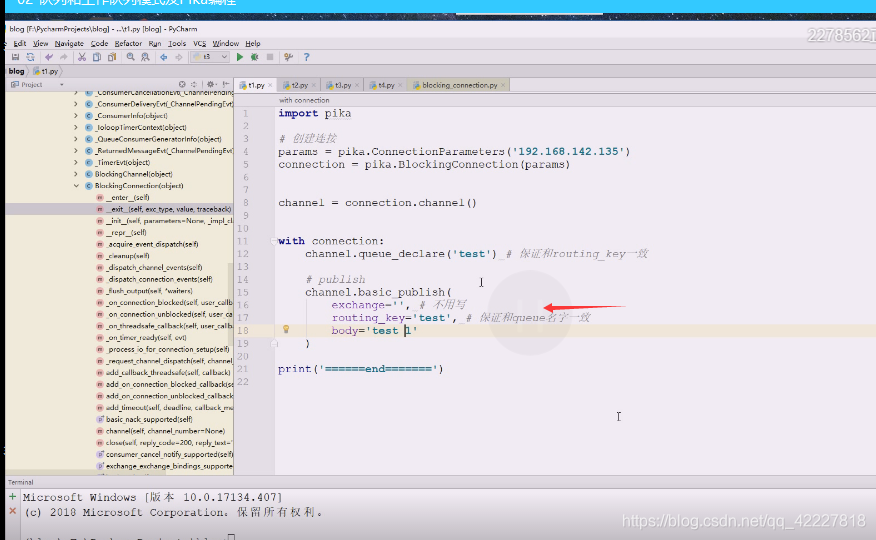
然后需要创建一个queue,把数据打入到queue里,现在执行一下有权限问题,因为使用了缺省用户,不允许访问缺省虚拟主机
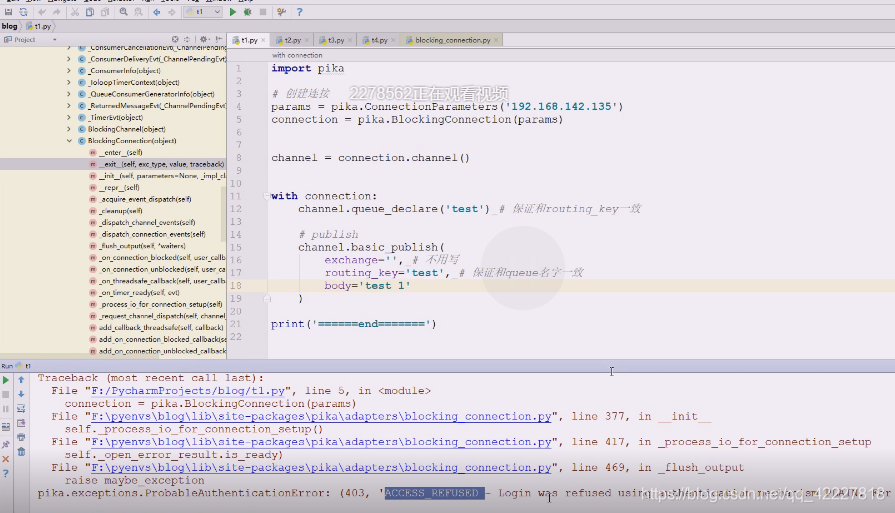
缺省虚拟主机只能用guest访问,guest只能从localhost登录
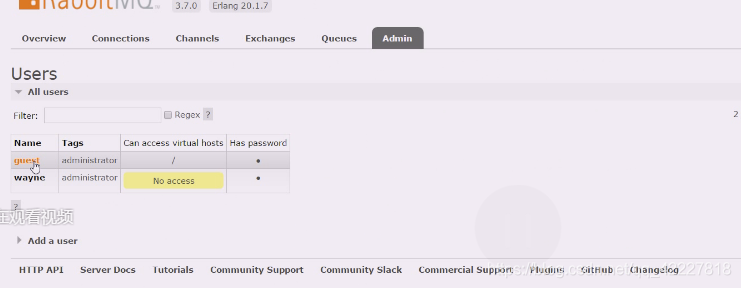
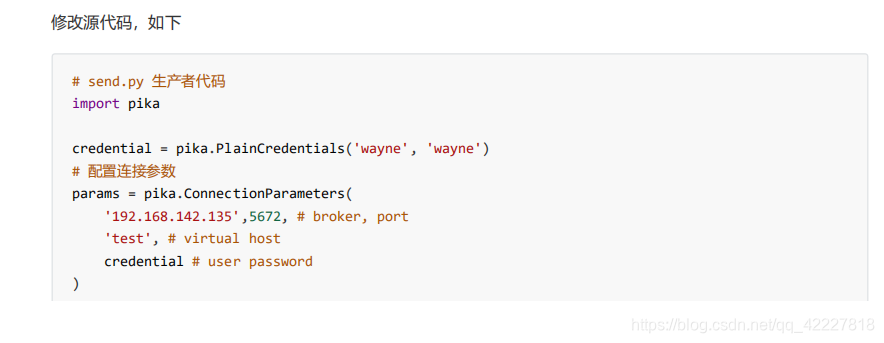
所以在这里要创建用户名和密码

没看到用户名密码,但是看到了credentials(用户名密码和权限的问题了)
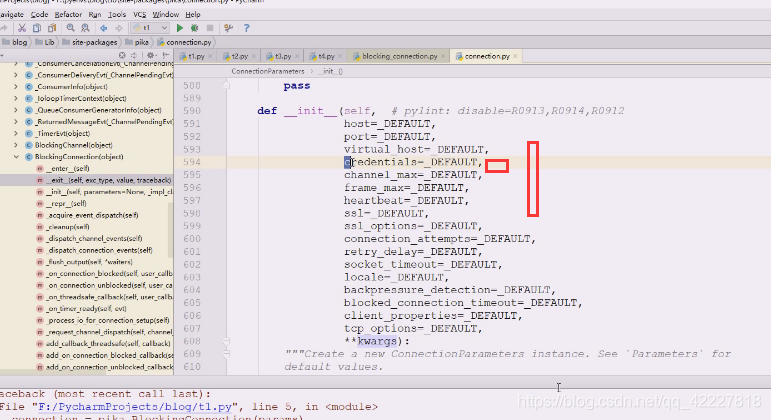
pika里有关于credentials的
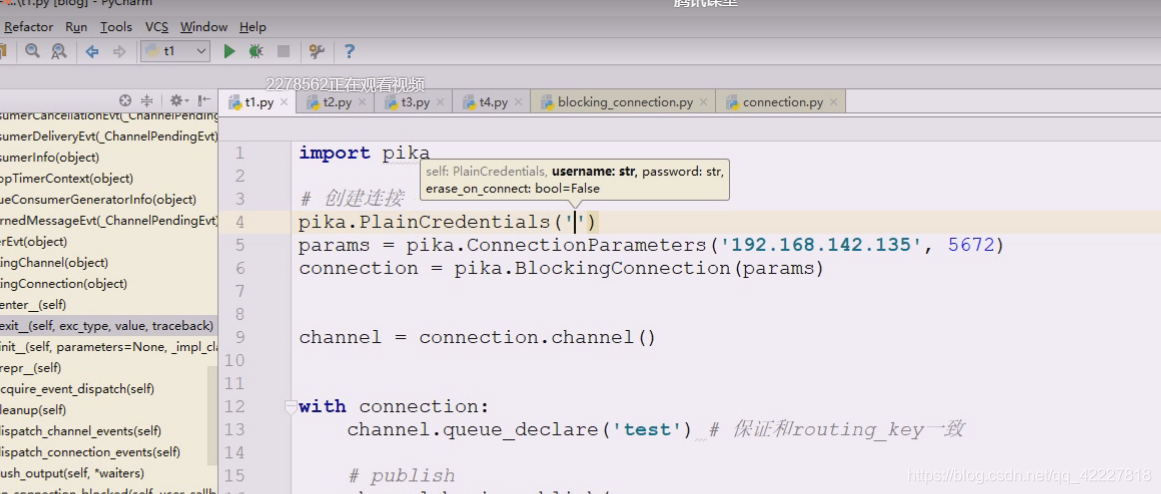
现在就把第四个参数也补上了
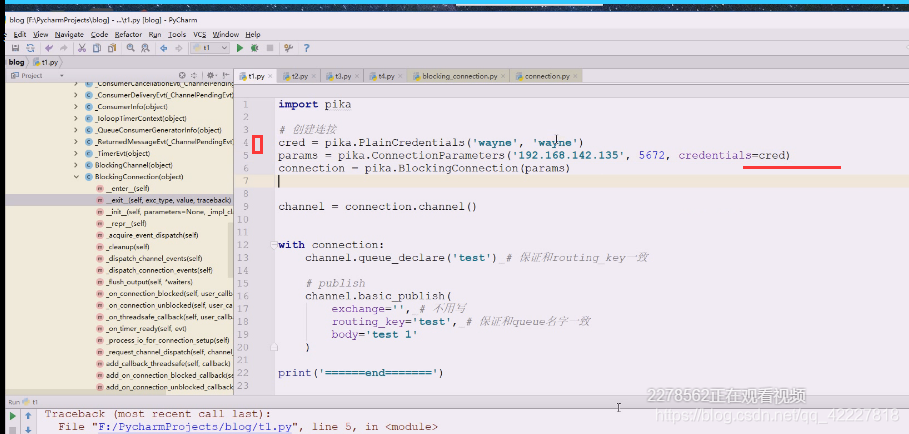
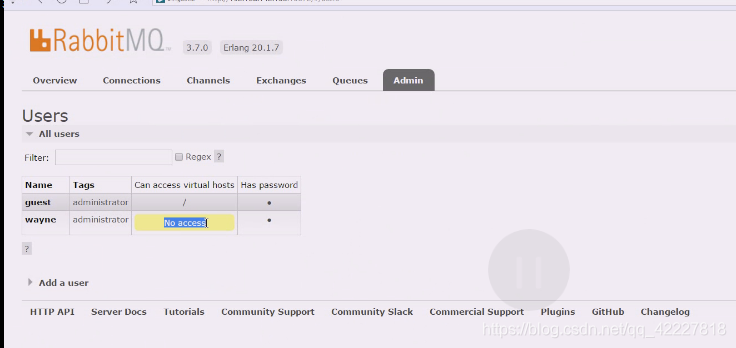
缺省虚拟主机现在访问不了
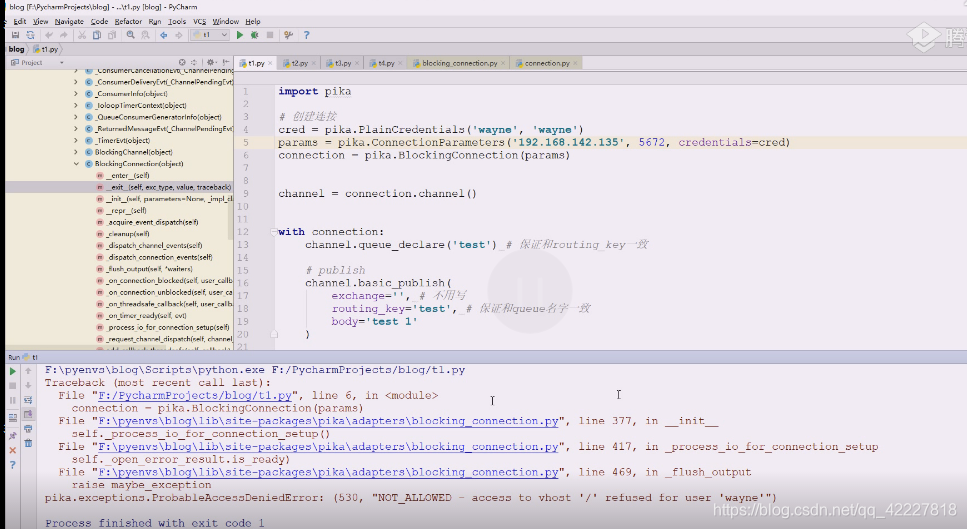
wayne用户是什么虚拟主机都访问不了
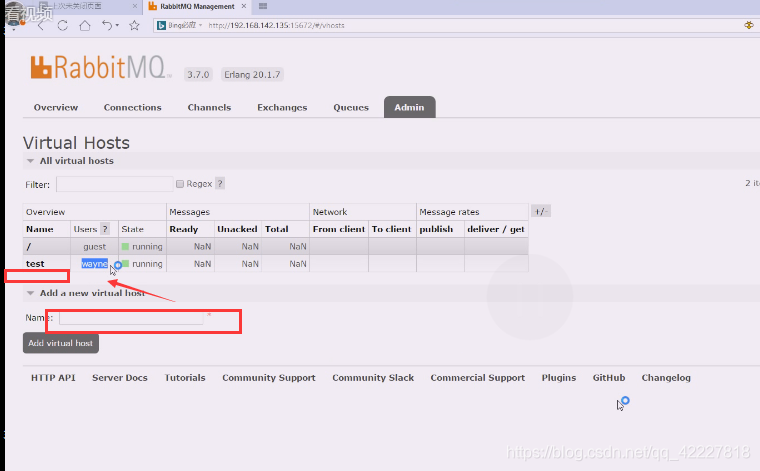
可以创建一个虚拟主机
第三个参数访问哪个虚拟主机
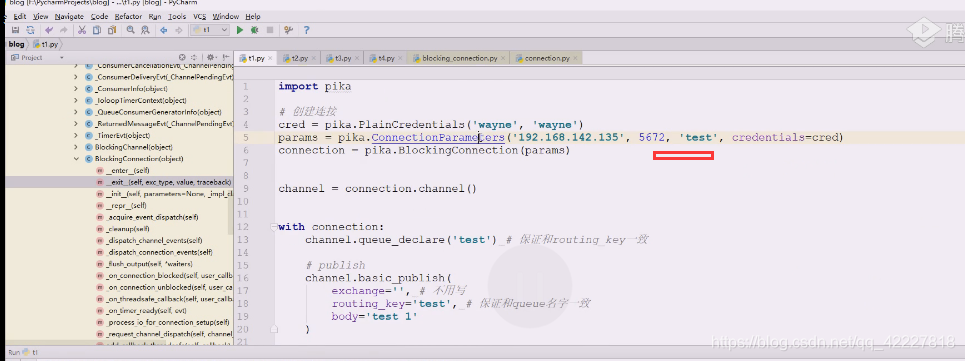
改成hello
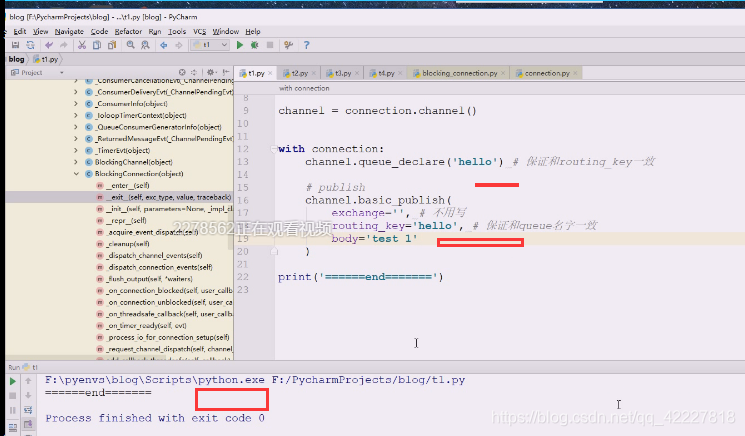
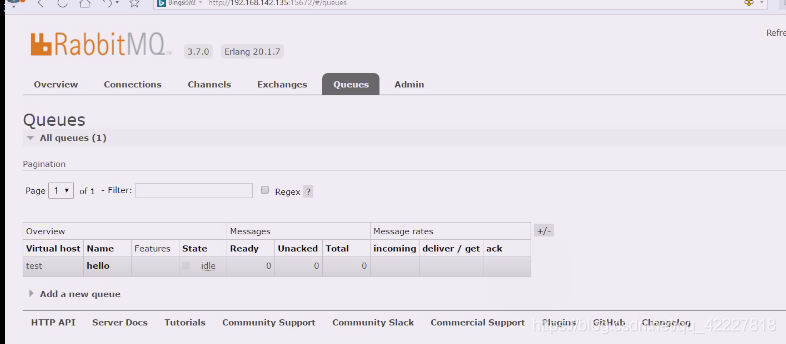
现在有一条消息,等着消费者来消息
这就是生产者
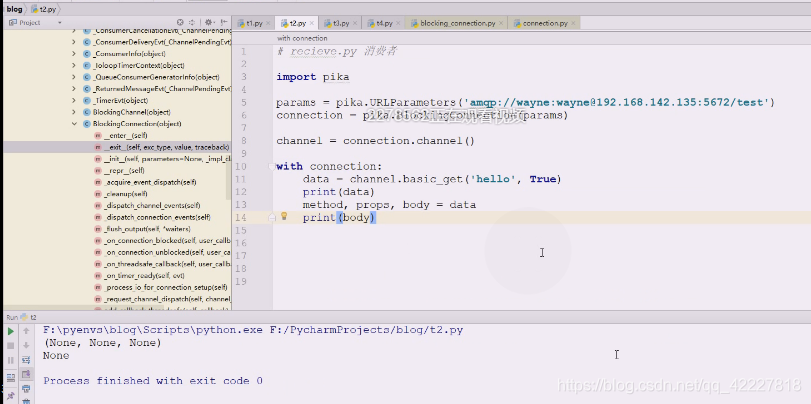
现在要写消费者receive.py,amqp高级消息队列协议,这里依然拿到connection
channel可以直接去拿数据,到底是生产者还是消费者取决于你的方法,如果是publish你就是生产者,如果是get就是消费者,get,输入queue的名称
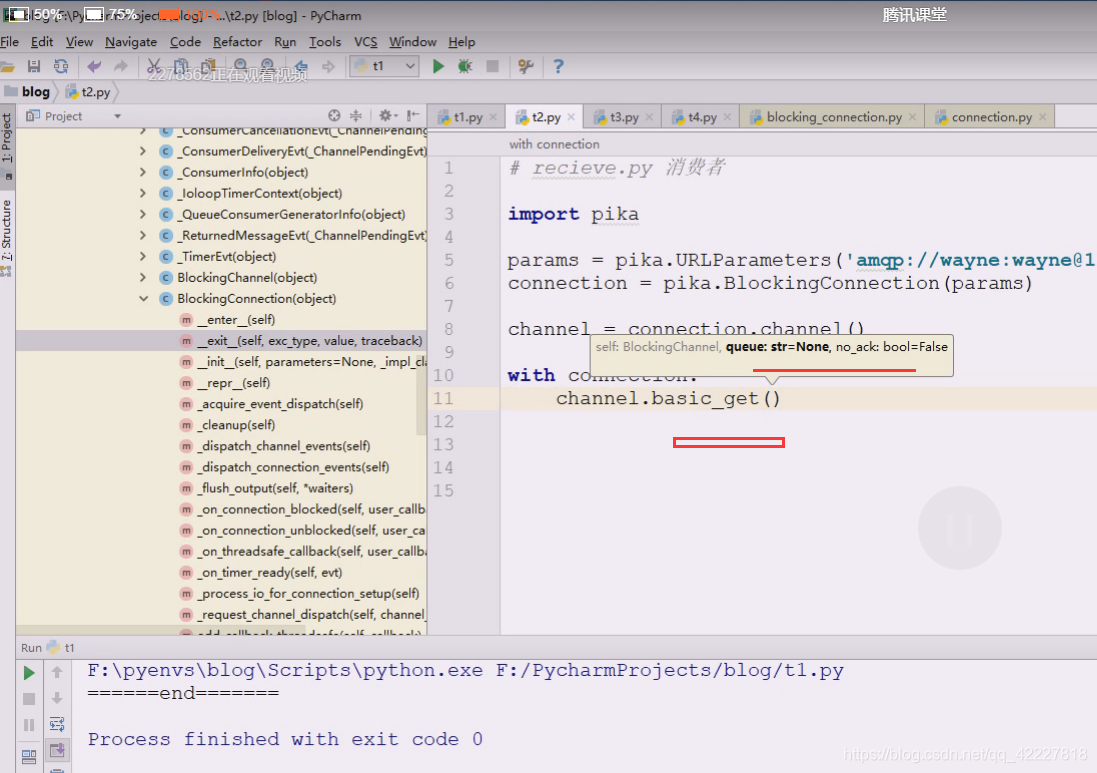
写个no_ack,等于true即可
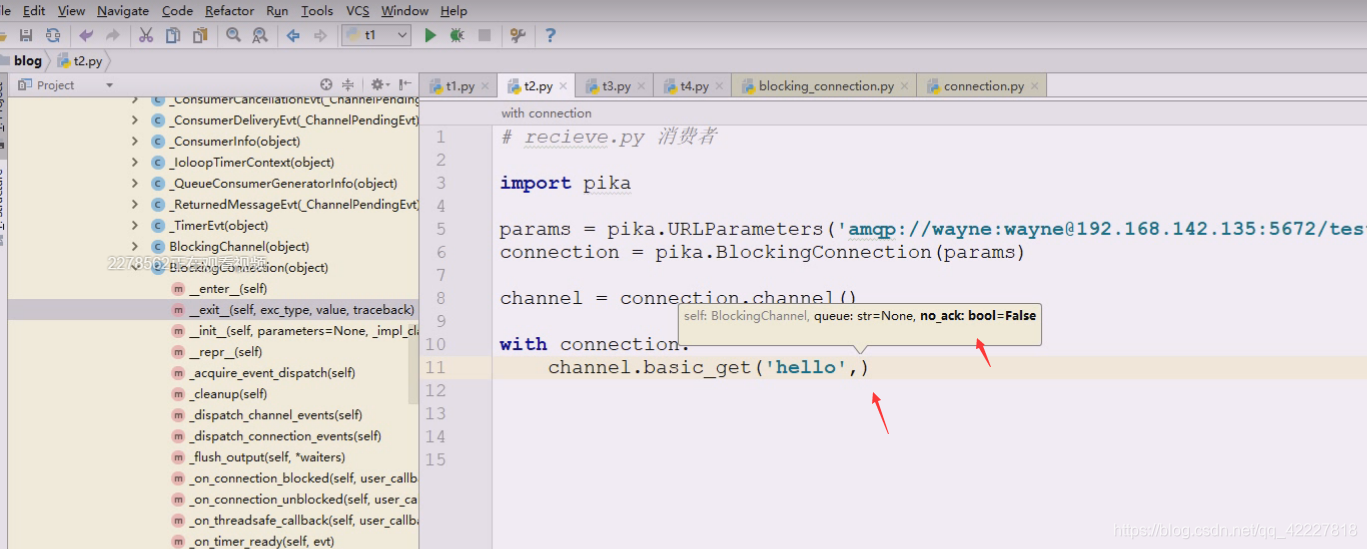
纯粹就是看参数
get拿回来的数据,打印看看,消费者拿到数据了,队列里的数据就没了
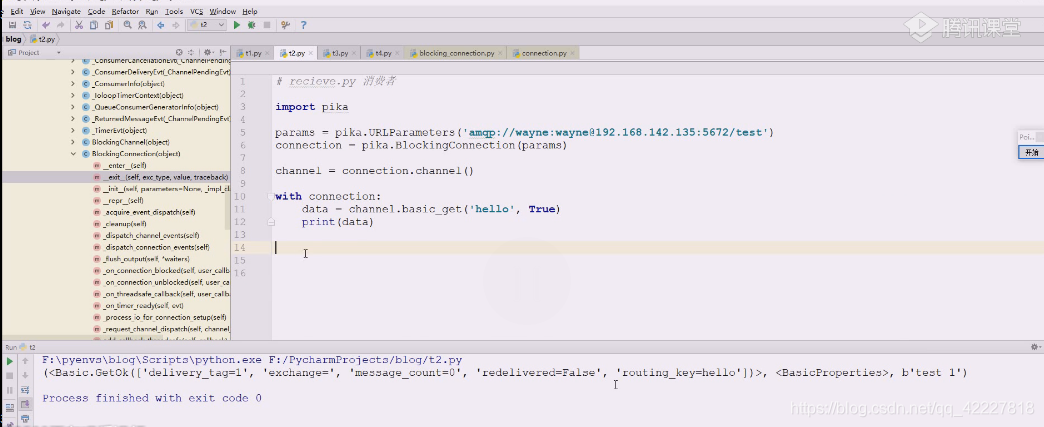
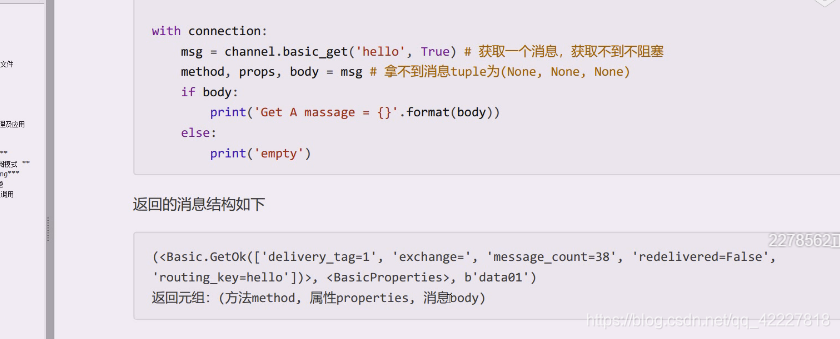
data是个很复杂的结构,是个元组,由三部分组成,第一部分可以认为是信息,第二个部分是属性信息,第三个是body

看下get方法,这里说返回一个三元组,如果拿不到信息,三元组全部返回none,否则将返回methtod,properties,body
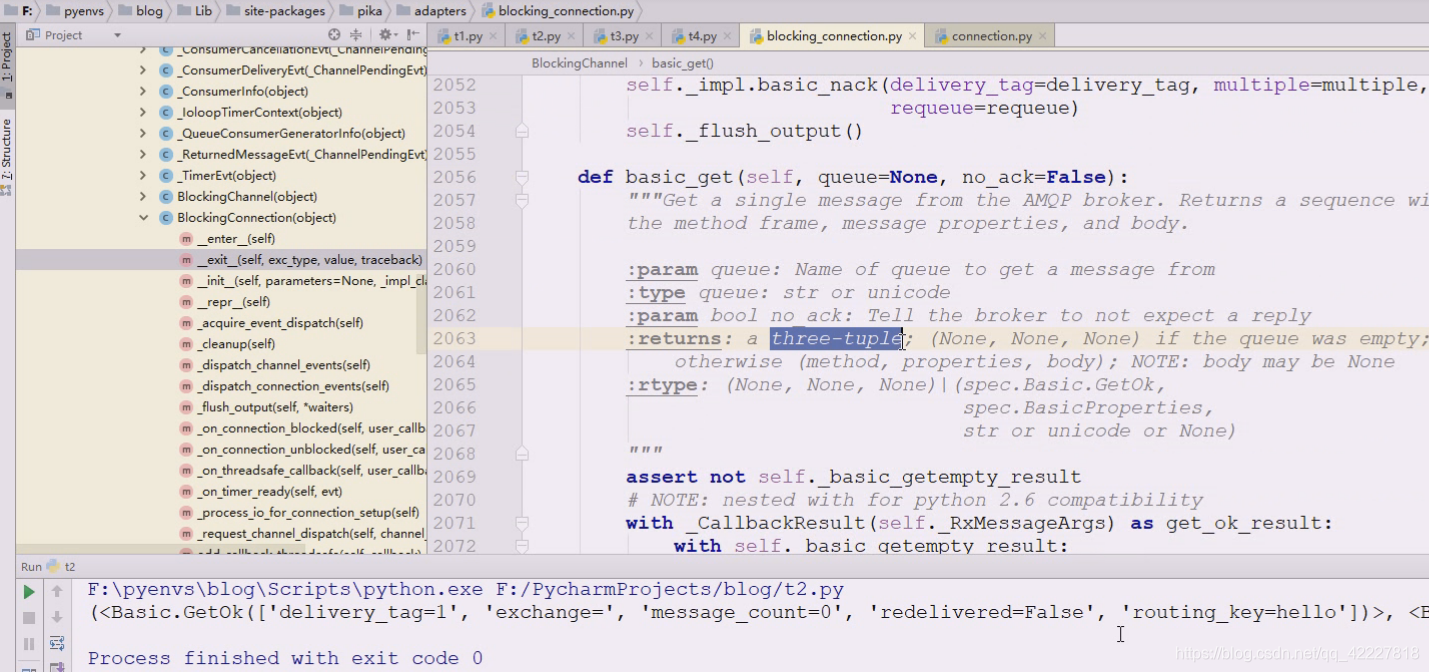
这里解构一下,再拿一次,因为没人生产所以都是none,如果里面没数据,此方法是不会阻塞的,并且返回一个全是none的三元组,如果要看拿没拿到数据,就可以看body里是否是none
同样建立链接拿到channel之后,可以自己创建队列将自己生产的消息打入到队列当中,就可以再rabbitmq的管理端看到队列创建里面有数据,然后等消费者来消息。
一般生产者和消费者都是不同链接,不同链接的消费者又链接到rabbitmq种,然后去找这个queue,从里面读取信息,最后把信息读取走,消息就消费掉了

出现的一些问题可以这么解决,不要在缺省主机加东西,自己创建一个虚拟主机test,test和wayne用户进行关联,就可以使用wayne用户访问test虚拟主机


urlparameters通过url来创建这些参数
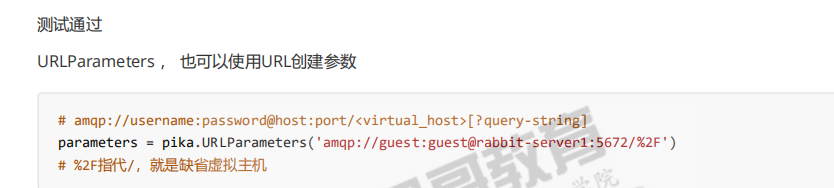
这是%2F编码过的,不编码就是//,无法理解,由于缺省是/斜杠,为了不引起冲突
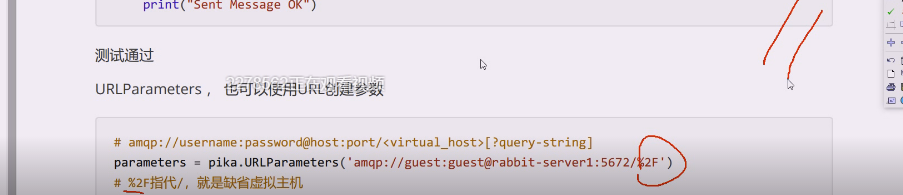
所以访问缺省虚拟主机,为了不冲突,就用%2F
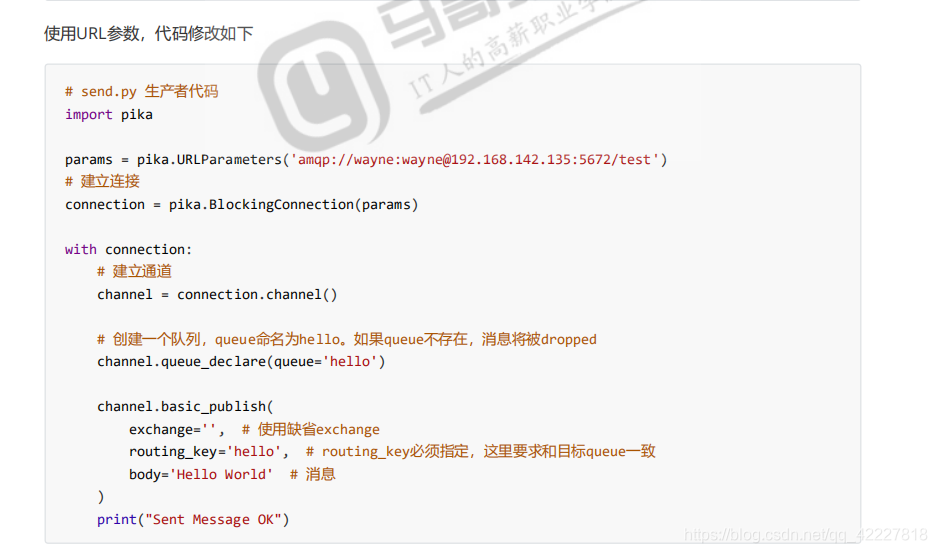
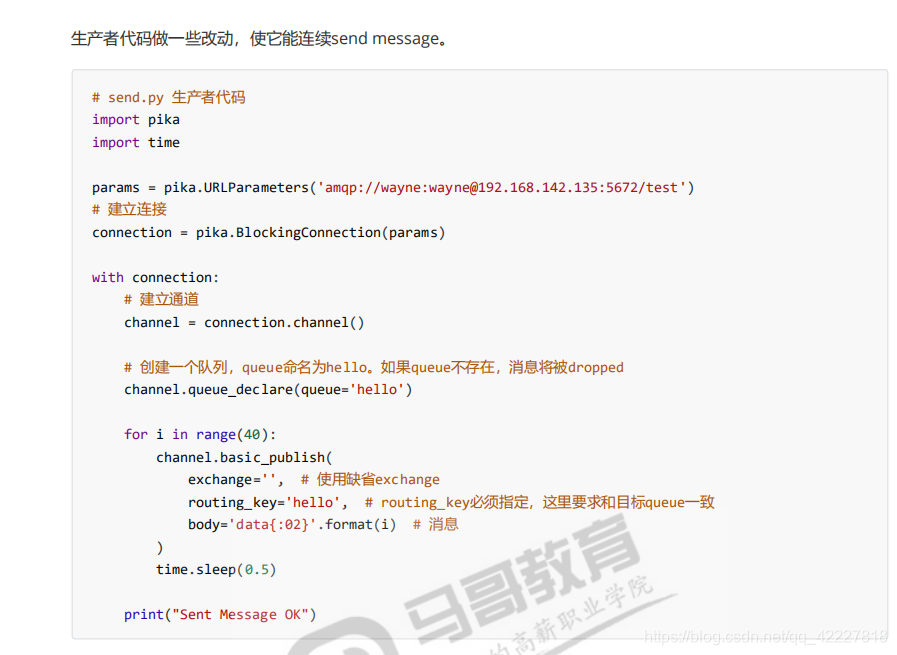
生产者这边建立链接,建立通道,建立队列,发布消息

生产者结束了也没看到队列消亡,现在队列是空的也没消亡,消费者过来就需要指定队列,已经有了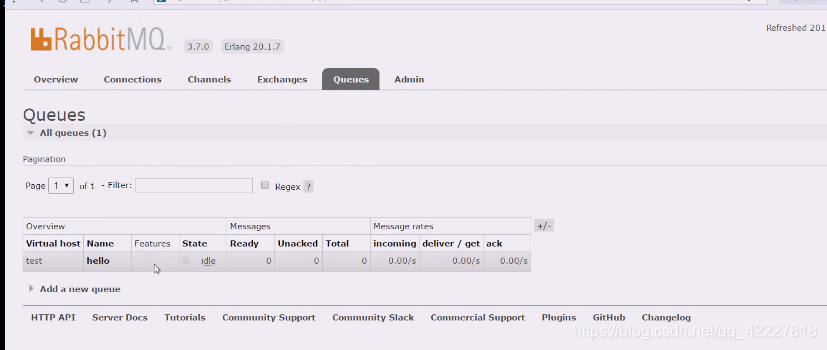
生产者再发一个消息
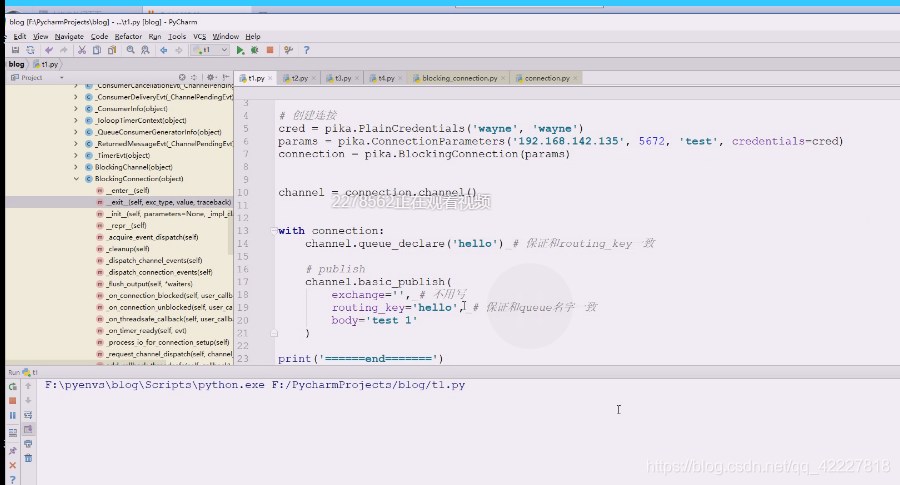
消费者还没消费,就还没消亡,已经建立过了,再来创建就说明已经有了,直接用
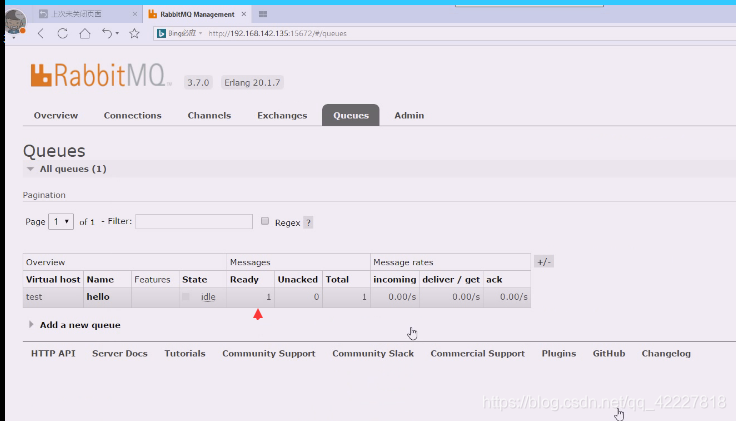
消费者没创建,是直接使用,就把消息拿走了
点一下这个队列
点击delete
现在就没了
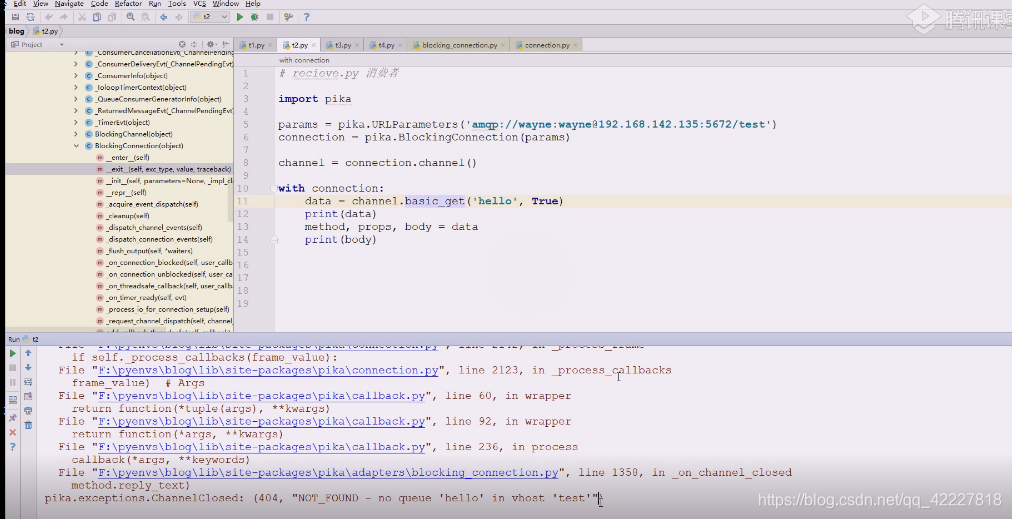
刚才是有这个队列,没数据可以拿到3个none,现在队列删掉了,没有队列,还是问他要数据,告诉你队列找不到
创建一个hello,从里面去拿
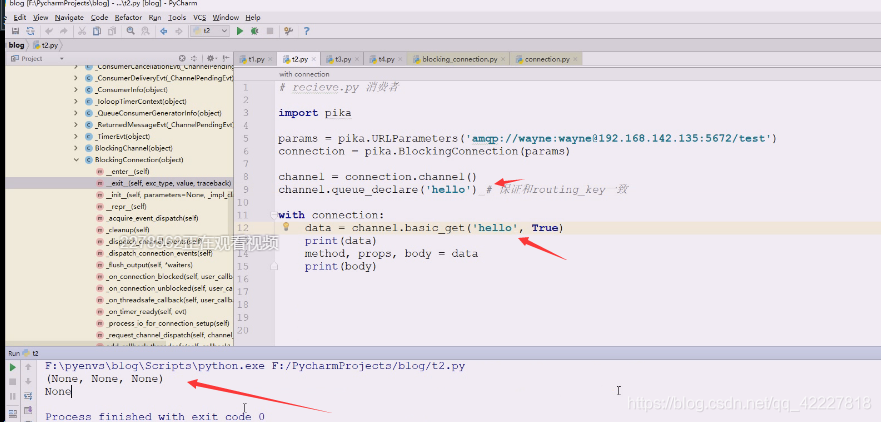
也就是现在这个队列生产者和消费者都可以建立

在当前虚拟主机逻辑单位下不要冲突即可
链接现在没有了
channel也断完了,现在就是交换机
除了缺省的,多了test虚拟主机
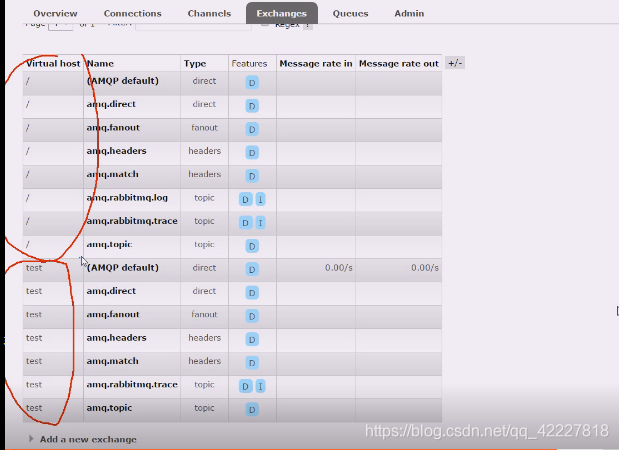
这里用的是缺省的交换机的名字,这个name是交换机的名字
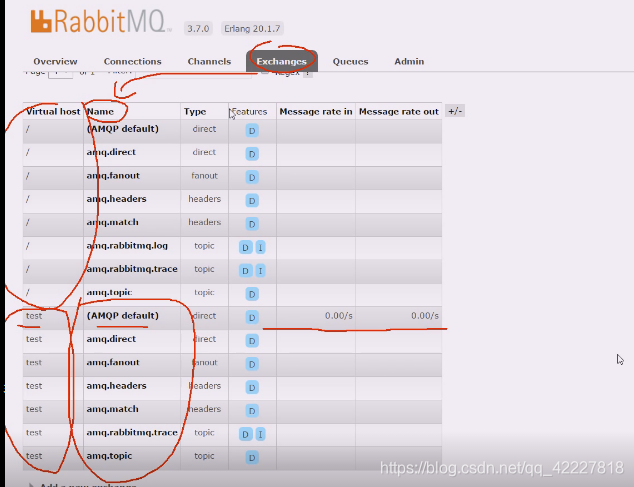
其实这个信息就是路由

比较常用的还有这两个
现在里面没有数据
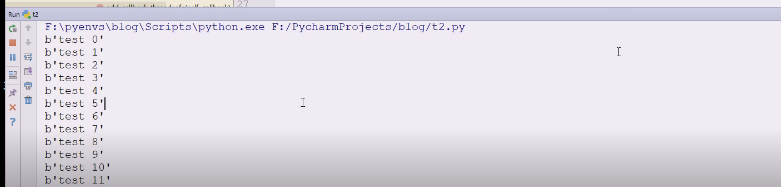
for循环多打入些数据
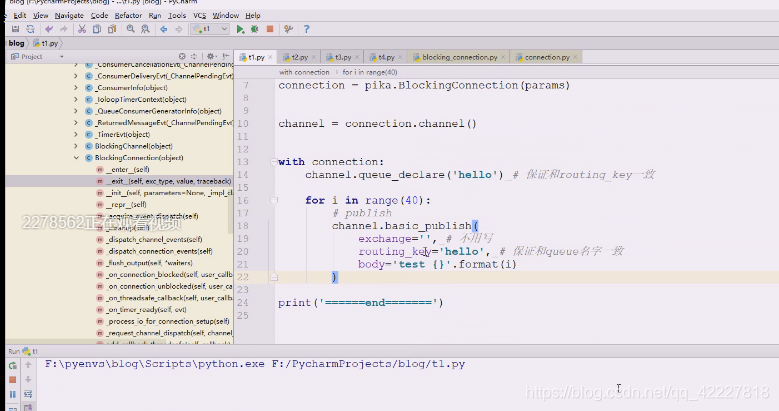
现在有40条消息
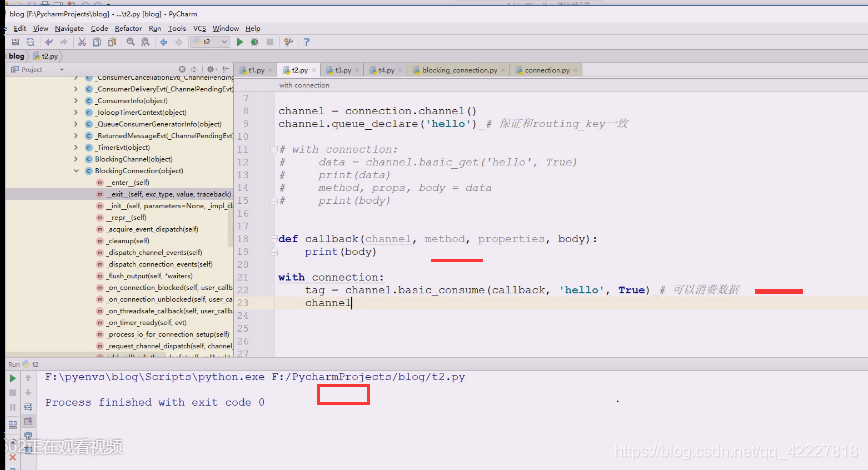
看看多条数据处理,有一个basic_consume消费
第一参数callback先保留,第二个访问hello,no_ack是为了高效不回应你,机制如果好的话,不但需要ack还要判断数据是否准确收到,如果没收到需要重发数据,不能把这个数据删除掉,因为对方没有拿到
callback是回调
第一个就是consumer的回调
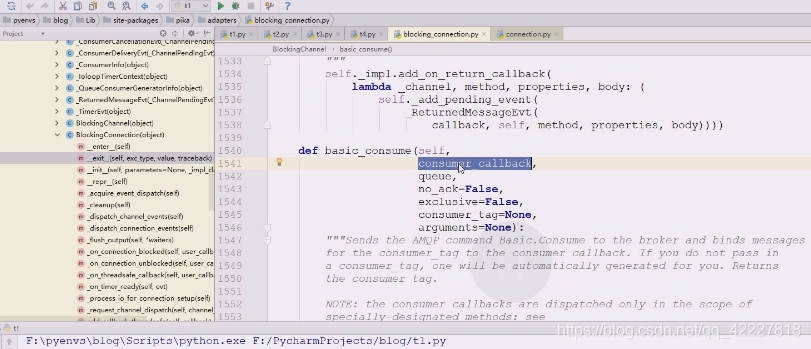
return值是 consumer 的tag,刚才get拿到消息是数据的三元组,返回值是不一样的
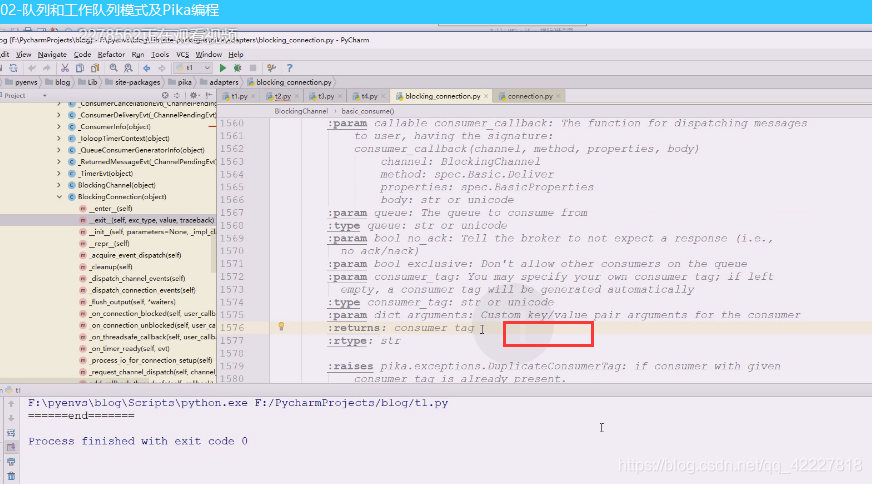
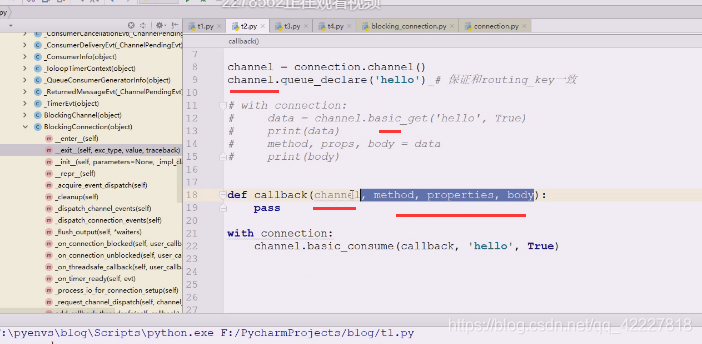
callback是consumer的callback,提供了这样一些参数
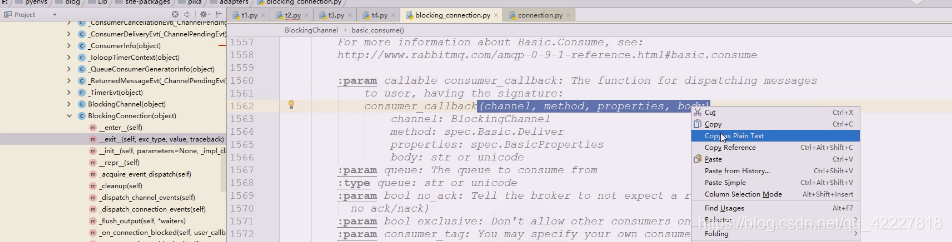
自己写一个消费者回调函数,抄一下帮助文档,callback在别人调用你的时候需要注入参数。get也是消费,consunme也是消费,consume消费的时候会从队列提取数据回来之后,准备调用这个地方。
这几个参数就是刚才解构的东西
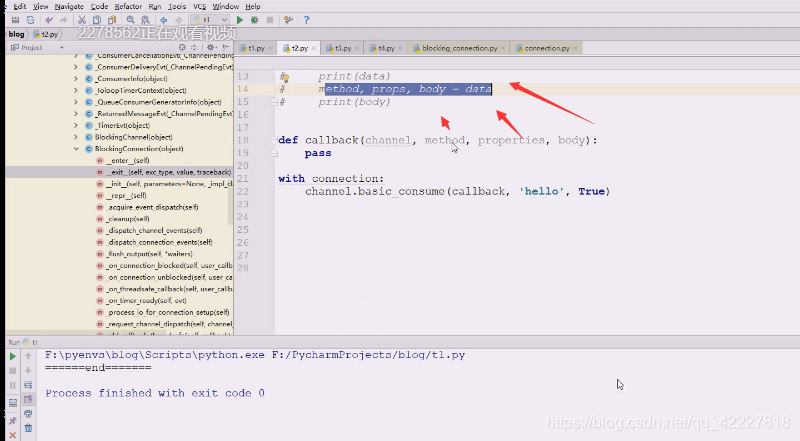
其实就是多了channel加上data,,data就是三部分
官方文档callback就是这么写的
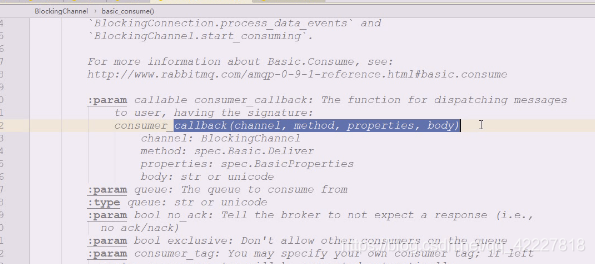
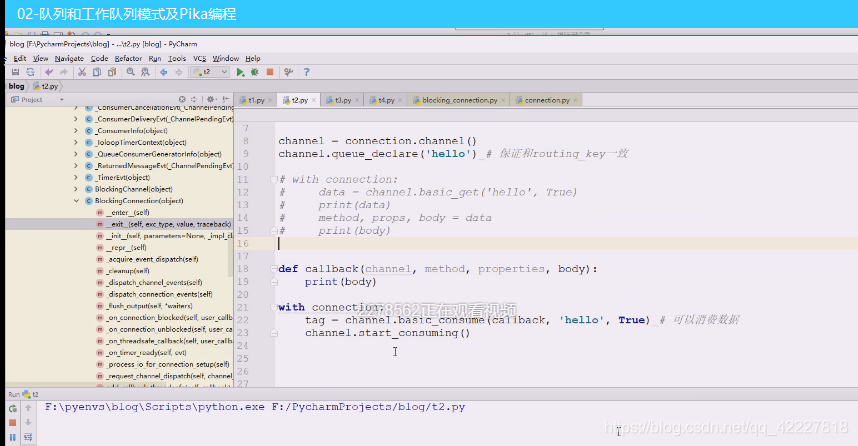
这样就可以把信息拿到,执行一下
消费掉了
 要是执行了应该可以看到print,所以这里不能直接这么用,需要有方法配合,可以消费数据,但是不这么用
要是执行了应该可以看到print,所以这里不能直接这么用,需要有方法配合,可以消费数据,但是不这么用
再产生一次数据
运行消费者
一会就消费掉了
但是t2还没结束,所以可以理解为forever
所有consume被cancel掉会自动停止,现在上面consume还没拿数据就还没停
这里还有一个函数叫basic_cancel,现在阻塞了就不能cancel,一旦阻塞就需要多线程了
start_consuming起来就会让你阻塞去访问,如果你要做其他动作就需要多线程,否则消费者除了消费就没有其他工作了
以后应该消费者一直是等着,是否有数据来,生产者生产数据比较慢,消费者和生产的数据有点不一定。多消费者如何写,多线程是一种解决办法,multiprocessing,多进程process。pool,execute。
如果再启动一个,相当于在同一个节点上,起了两个进程消费同一个,这两用的是不同的链接,而且这两个进程之间不能通信,这是在本机模拟的两个消费者。
如果把程序拷贝到另一台机器运行起来,这就变成跨网络的两个进程消费同一个队列了
一个 生产者在一个节点上,一个消费者在另一个节点上,这就完全分散了,中间就靠一个队列,很容易就把程序分散掉了,写的程序分开了,变成了单独的程序,通过一个队列关联起来了,做了解耦还有生产者和消费者速度匹配问题。
爬虫如果爬的数据很多,应该先扔到队列里,然后另一方从队列取数据,如果还不想进数据库也可以先进队列。只要队列的性能够强,就能解决高并发的问题
现在单个多个消费者都可以,做一下测试
多产生一些数据
启动2个t2相当于用多进程的技术
现在两个链接链接上了
两个进程各自的channel
交换机都链接这个
queue都是链接的同一个
一个t2里全是奇数

另一个全是偶数

这是轮询,再加一个看看是否是轮询,再启动一个t2,本机三进程
继续生产数据
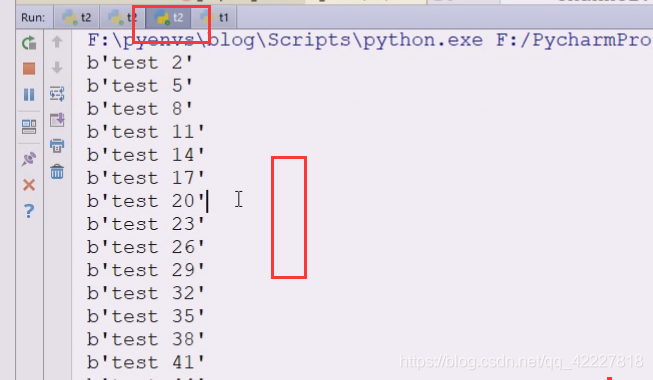
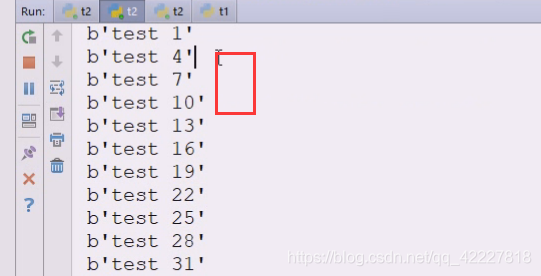
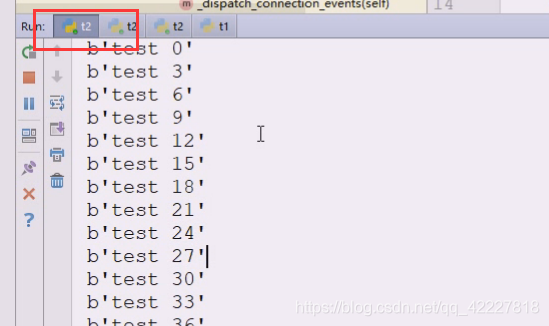
这就是典型的轮询
这里返回的消息是三部分,body里有我们要的数据bytes
批量消费用consume,如果不配合start_consuming就把数据拿走了,根本不做任何处理,但是一加上start_consuming是阻塞行为

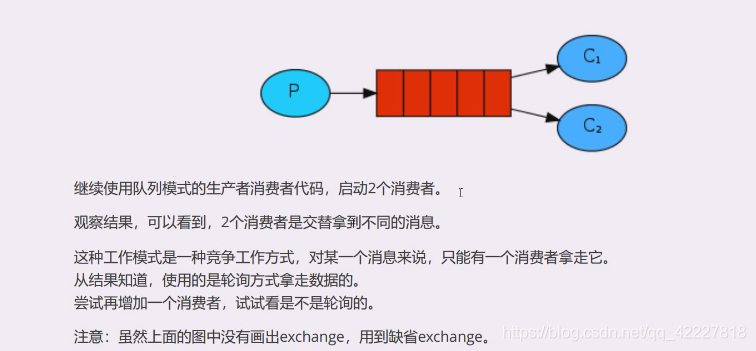
官方提供的第二种方案:工作队列

工作队列是两个消费者消费同一个队列,如果都消费同一个队列,做的事情其实是从队列中拿一个数据,谁拿走就是谁的,数据只有一份,在队列中只能给你一份。
但是并不是所有队列都是这样的,kafka是拿走了还在,拿没拿自己看着办,根本不关心你拿走没。
如果同一份数据要都用,进行不同计算,就需要想其他办法了。
但是在这里,队列里的数据只能提供给一个消费者,拿走就没了,但是并不是所有的消息队列都才用同一种方案
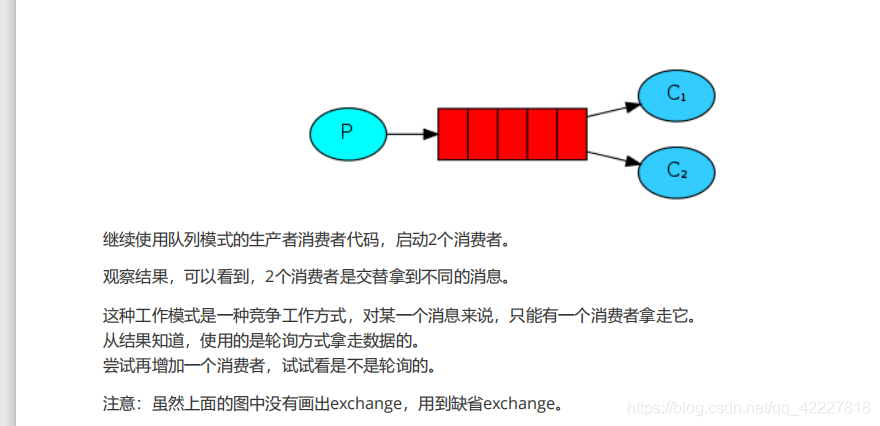
2个消费者,或者3个消费者是轮询拿的

在图中没有交换机,但是在test虚拟主机上,缺省的交换机上有流量的提示,在那个时候已经使用了缺省交换机,我们用的是自己创建的虚拟主机的缺省交换机
这种往往是我们想用的
爬虫去抓取网页生产数据,假如把生产的数据,爬虫返回一个response对象,可以用response.text拿到正文html,同步处理,如果底下的分析没做好,就没法进行下一次爬取,能否把html正文部分先打到队列里,然后起多个消费者从里面拿出来解析,这样生产者有多个,消费者也有多个,很容易就生产起来了