之前的爬取用一些简单的库就可以完成了,其实就是一个http请求得到一个response,然后对响应内容进行处理,响应的内容其实就是文本,http协议都是基于文本完成的,对文本完成分析,最简单方式就是正则表达式,但是在正则表达式有局限,(搞成html的解析器,按树型解析)
xml和html有相似之处,都是标签语言,这些标签之前是用树形结构来组织的,有父标签,有子标签。
html是来解决格式的问题的,但是在异构平台如何找到数据传输的方法。以前都是socket编程,你说第一个字节做什么第二个字节做什么,二进制的效率是高,但是二进制在通信的时候有时候不需要这么高效。
使用文本来通信,就会遇到格式如何定义,html是定义格式的,能不能基于它来定义传输数据的方式,传输数据的时候就不太在意格式了,就发明了xml,扩展标记语言,这里的标记不是为了表示数据在网页显示的位置。是告诉你,这个数据 结构什么样子,有没有关系,还有每个标签所表示数据是代表什么业务内容。
xml不是为了代替html,是为了描述数据。
到最后都会被解析成dom树,文档对象模型。浏览器内置了文档对象模型,是对html进行解析,就它转换成dom的,xml解析不了,一般只能按文本显示。
html和xml的区别:
html是做数据格式的显示的,里面的数据都是为了用标签在,浏览器页面绘制出来的。xml创造就不是为了显示,是为了在系统之间传输文本
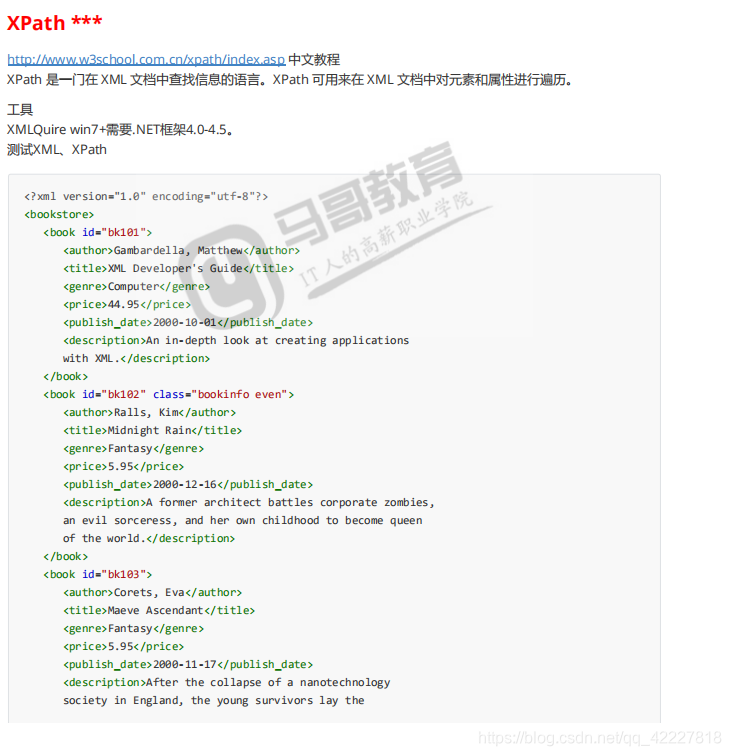
xml的标签都是自定义的,符合标签规范即可,结构也是自己定义,愿意多少层就多少层
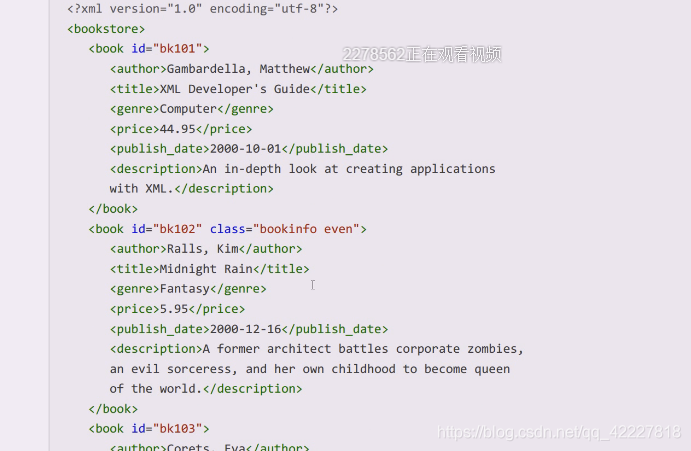
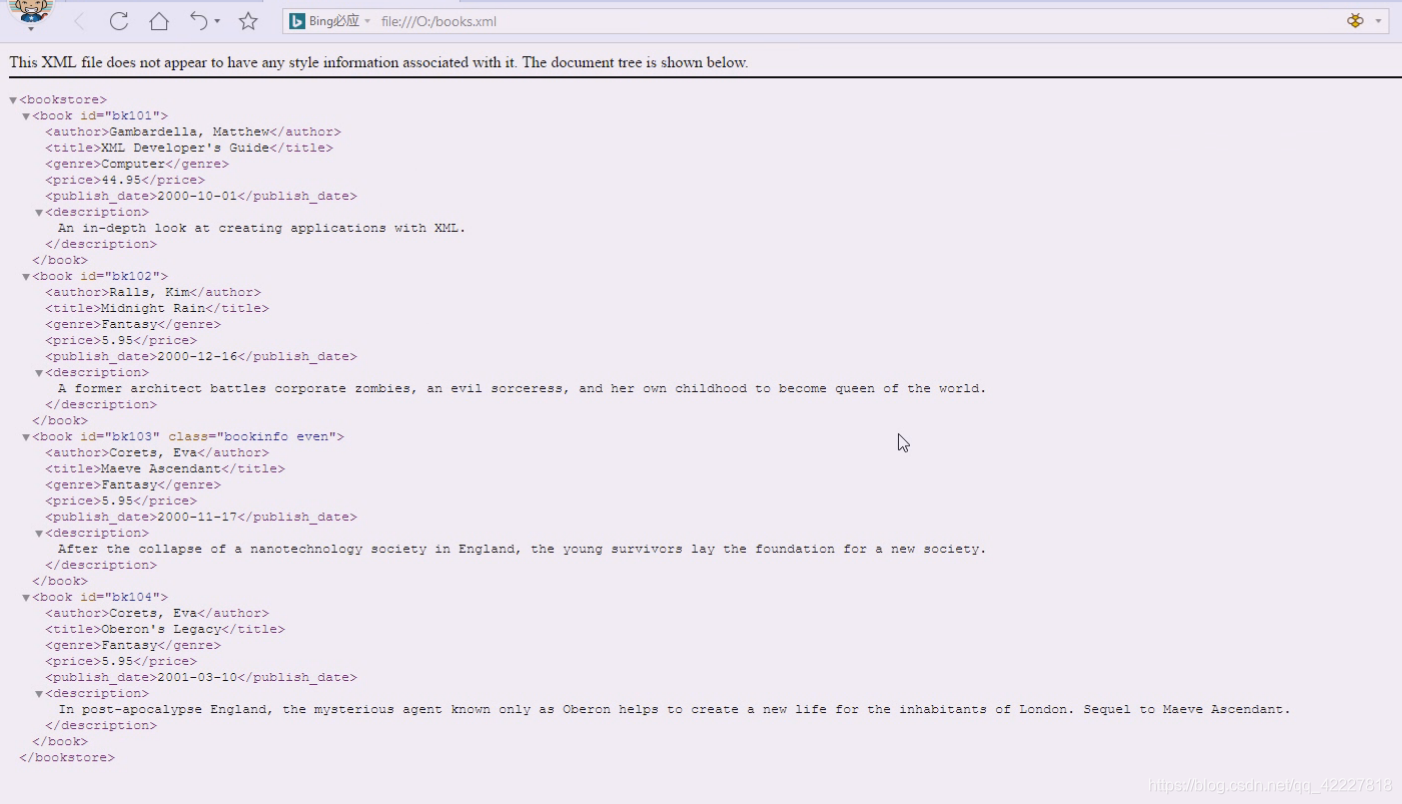
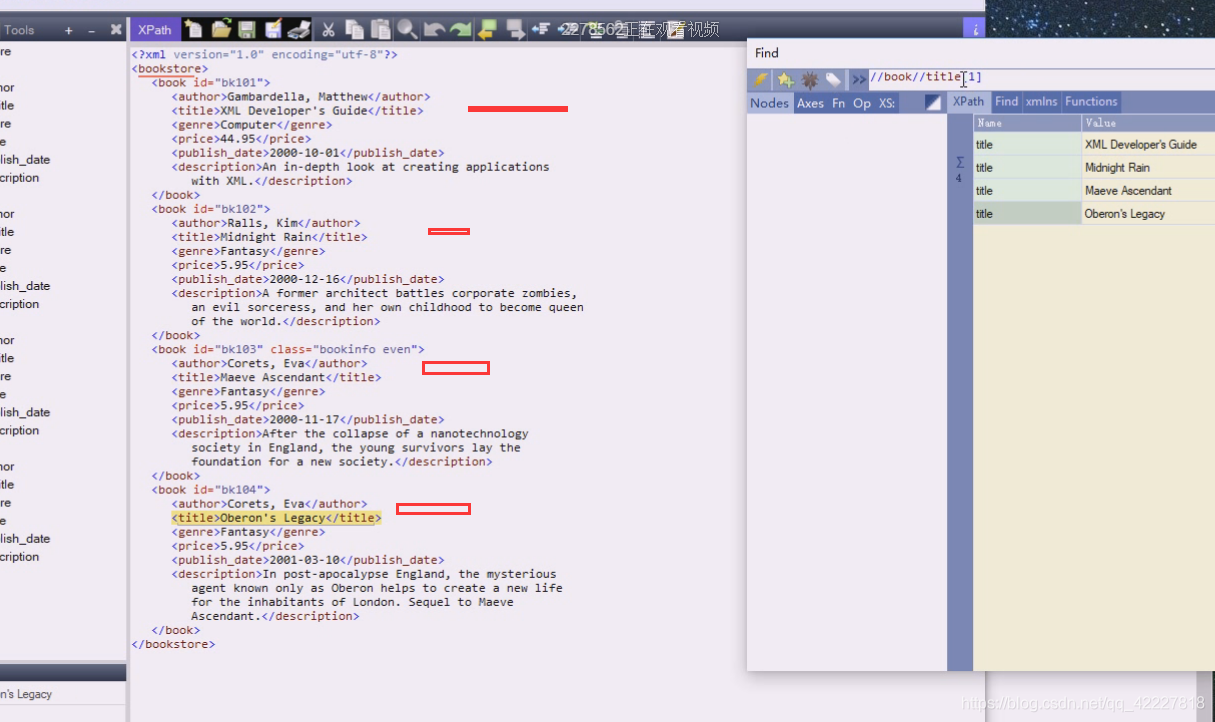
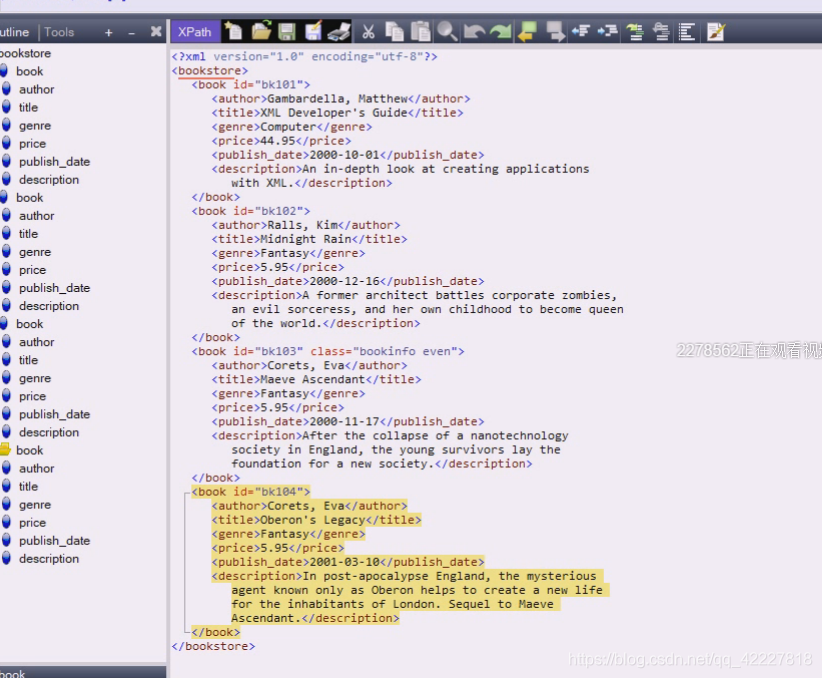
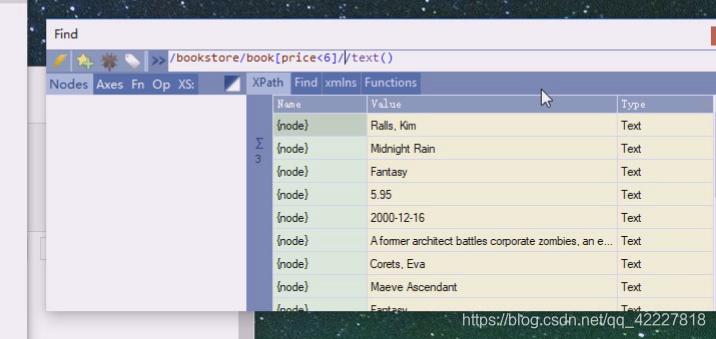
可以理解为bookstore是列表,里面装了好几本书,book01含有自己的信息
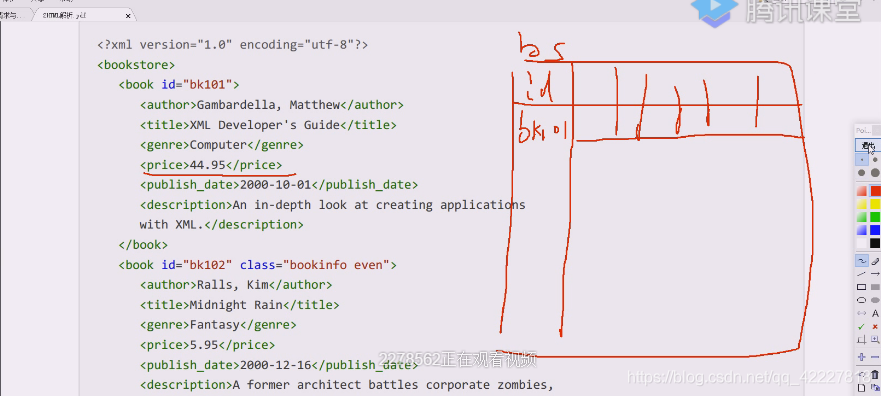
加入按照数据库里的表来理解,id=bk101,后面就是一个个字段
这就是浏览器显示的结果,浏览器就不认识这些标签
xml是一种跟html标签很像,用树形结构描述数据的一种格式文件,往往是在异构系统之间用文本传输数据用的东西,但是太费流量,现在一般用json
json是javascript,也就是通过http传输的时候,如果送到前端去,用json,js可以自动解析,因为是js规范之一,艾克码规范之一,所以json发到前端可以自动被解析掉,拿来就可以直接用了。逐渐取代了xml。
xml也火了一段时间,webservice就是基于xml的。现在暴露接口都是restful接口方式,内部传输都是json方式。
还有一些传统的还是用webservice,里面还是xml,xml的解析还是需要了解下
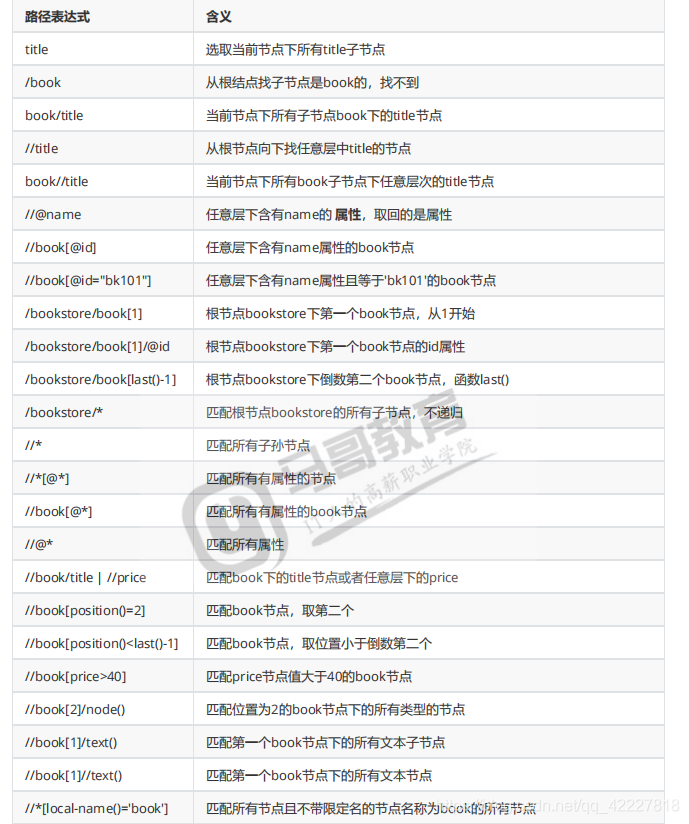
XPath
必须掌握的,xml解析需要用到的技术Xpath
XPath是在xml文档中查找信息的语言。Xpath可用来在xml文档中对元素和属性进行遍历

xml并没有表明数据是什么类型,都是在XSLT标准中定义,数据类型还是在这个标准中解决的,还解决了在里面如何查找数据

XPath就是如何在xml中定义你的数据,因为我们做爬虫要把html当xml看

JSX是按照XML的规范来定义的,写html的时候一定要封口,因为xml是要求要封口的,一般写html的没这么规范,所以我们先要转换成规范的才能使用

最终还是要通过XPath语法来找到数据
我们需要用XMLQuire这么个工具,实际上是.net提供的解析库,msxml,微软做的这个库是很好的

直接运行
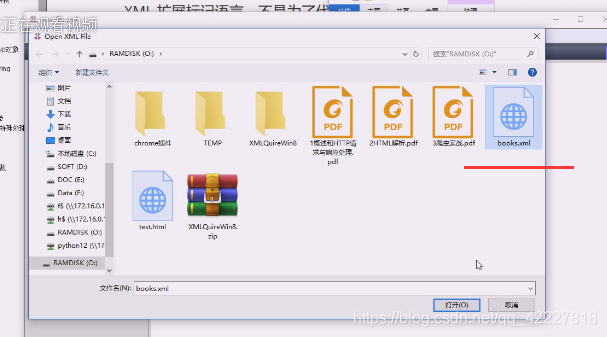
打开文件
books.xml装进去
这就是看到的xml
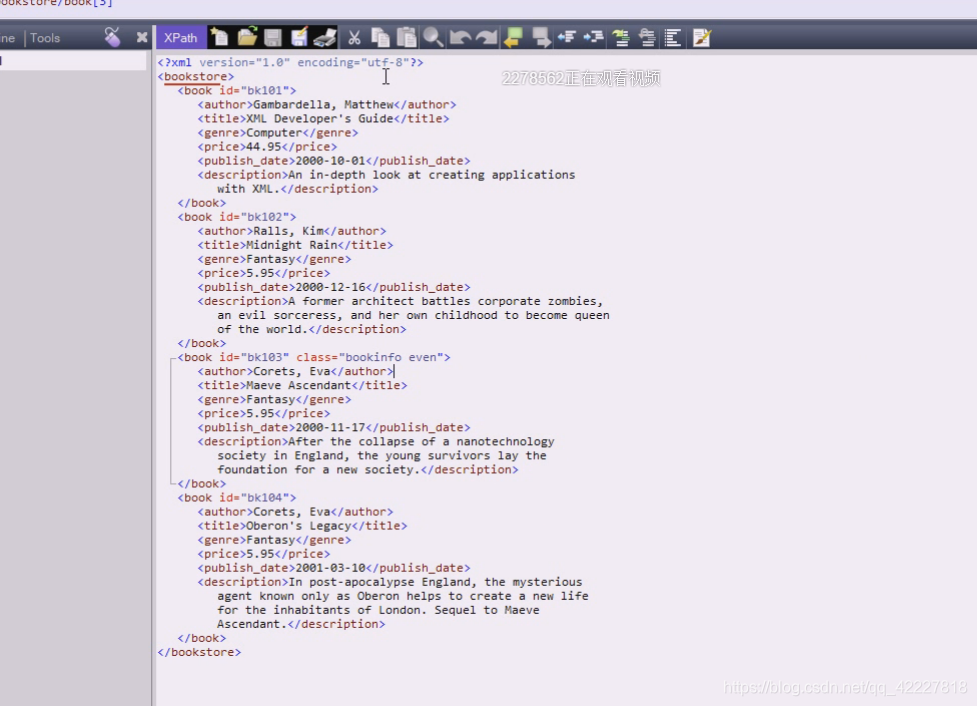
class在这里依然称为属性,谁等于谁依然叫属性
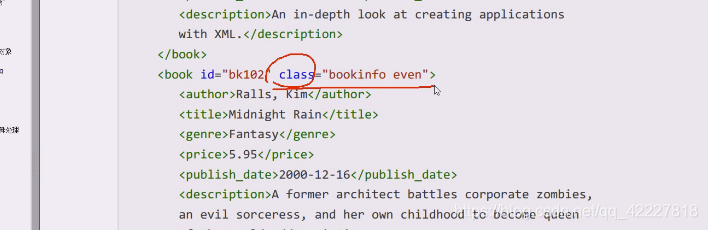
在XPath中有7种类型的节点:元素、属性、文本、命名空间、处理指令、注释以及文档(根)节点。
/代表跟节点
元素节点,book,title这种都是元素节点,里面的id=多少都是属性节点
节点之间的嵌套形成父子关系,因为是树形

谓语就是来查找某个特定的节点或者包含某个指定的值的节点,往往被嵌套在方括号中,就是查询的条件

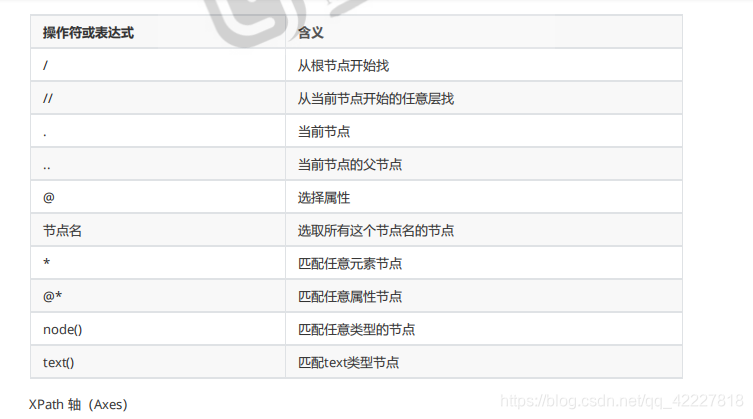
最左边代表跟,在其他地方是路径的分隔符,或者层次的风格符

不管多深都可以找到,放在路径当中就是从 谁开始向下任意层,最左端就是从根开始任意层

代表当前节点

…代表父节点

@符号是属性的选择

选择所有节点名的节点,写个名称就是只要是这个名称的节点就ok了

** *代表任意元素节点 **

*@任意属性的节点

node()匹配任意类型的节点

text()匹配文本类型的节点

另一个概念轴,轴指的是,它的子孙节点和它自己,就是在树的继承关系上的节点
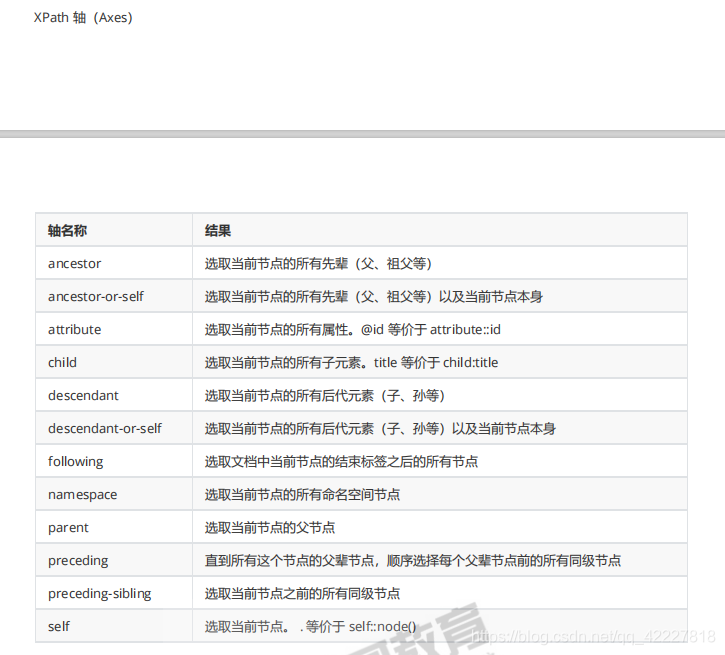
祖先节点

祖先节点及自己

属性

孩子节点

子孙节点

子孙节点和自己

当前节点的父节点

找到所有的父辈节点

选取当前节点之前的所有同级节点

直接用.就行了

不太使用轴,在特定的时候使用才用轴
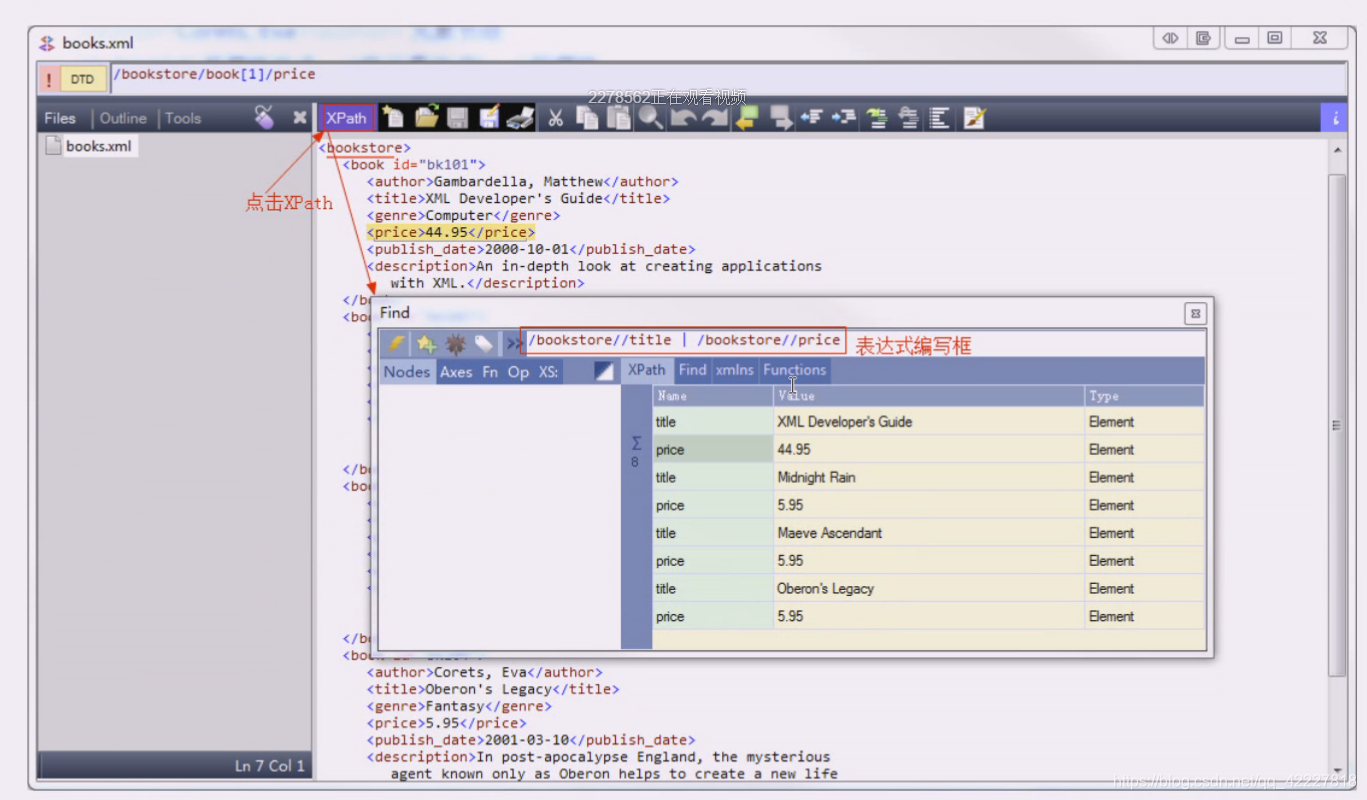
点击XPath,会有搜索框,不要轻易敲回车,你以为没有,实际上变成上一行了,这里只能显示上一行
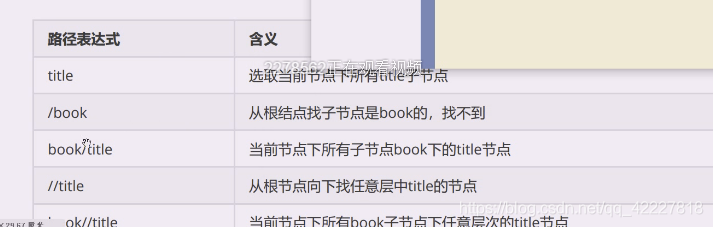
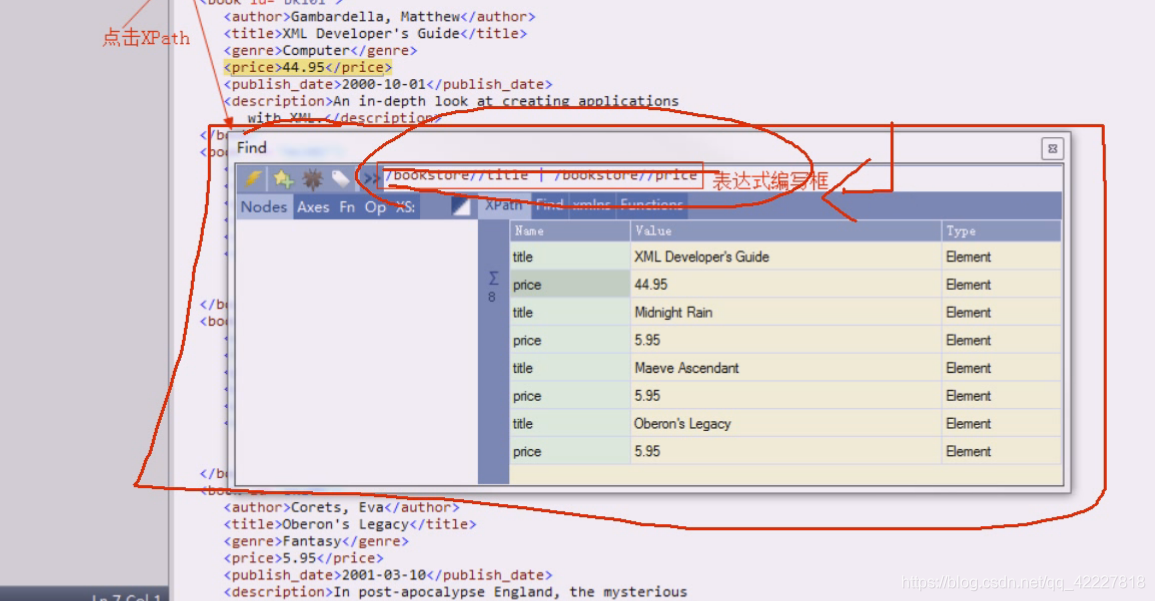 、这个例子就是从跟/开始,跟下的bookstore,在bookstore任意层次下的title或者跟下的bookstore任意层次下的price
、这个例子就是从跟/开始,跟下的bookstore,在bookstore任意层次下的title或者跟下的bookstore任意层次下的price
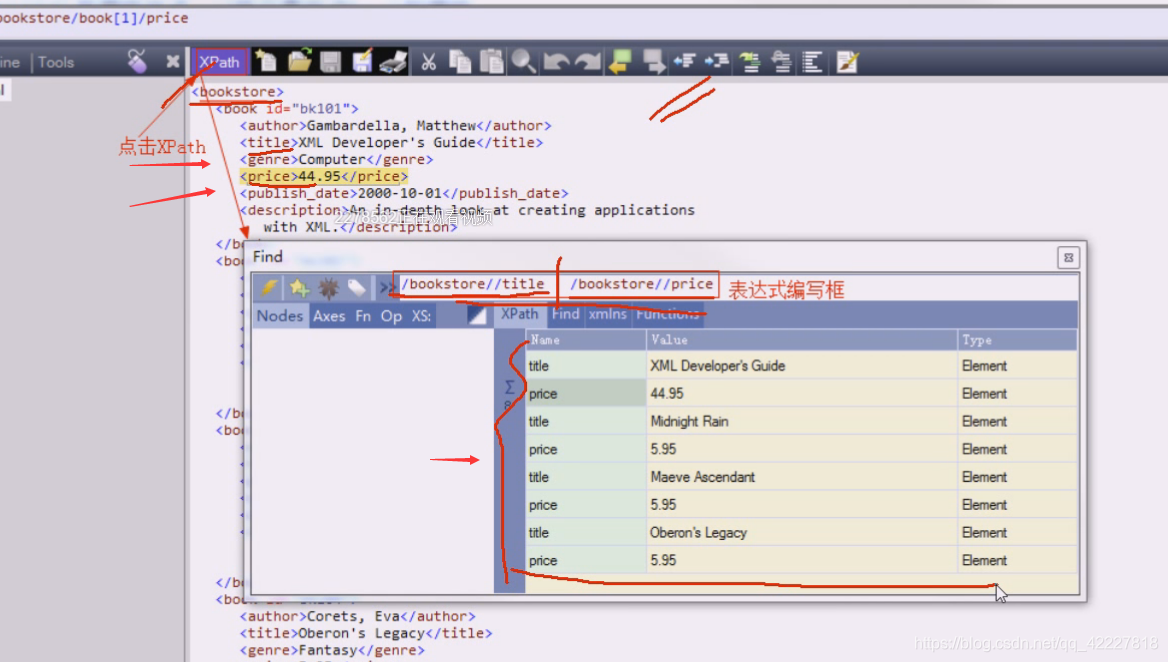
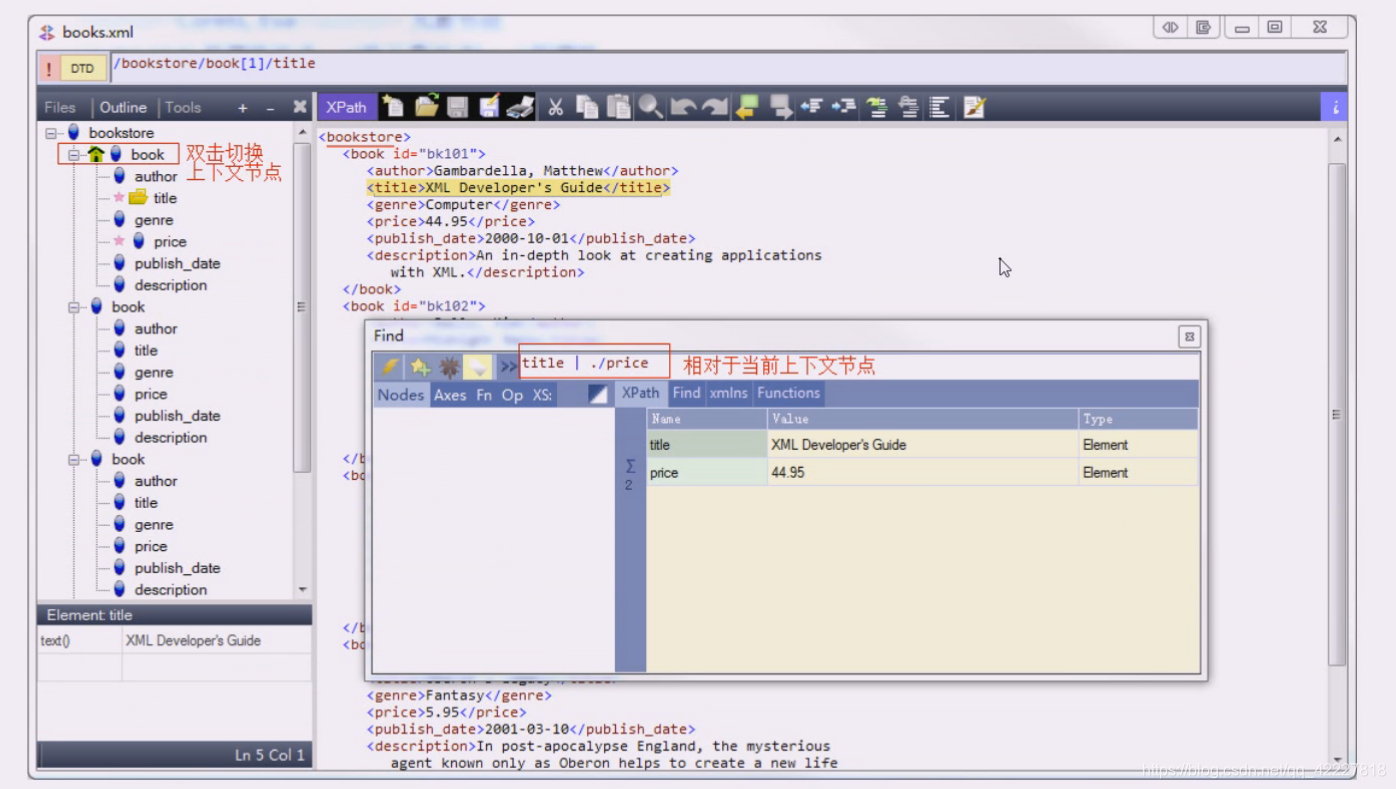
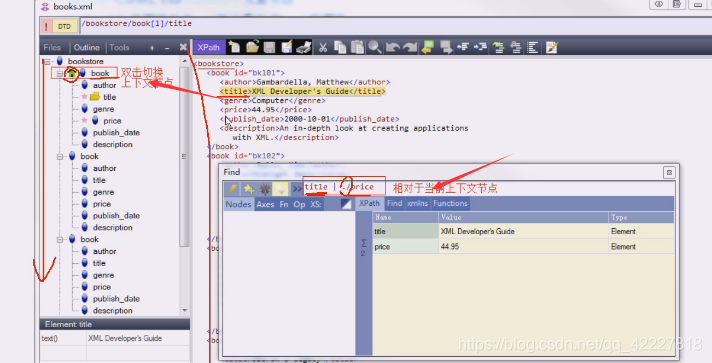
在你在这个小房子任意双击节点,这个时候就是当前节点
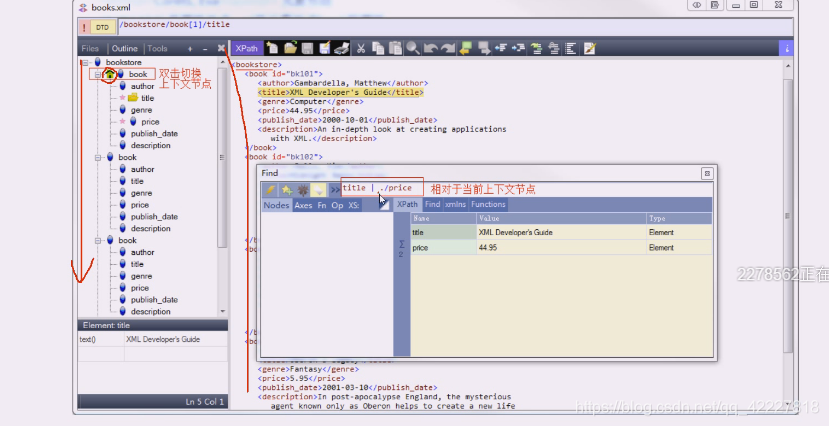
当前节点下找title和price
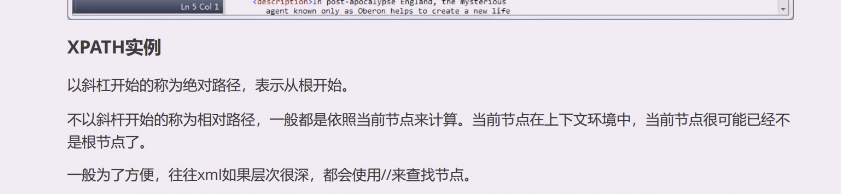
最左端以/斜杠开始称为绝对路径,表示从跟开始。
相对路径都是当前节点,在这个工具里,双击哪个节点就称为home,意思就是当前节点。
一般我们都会使用//双斜杠,这样可以在任意层次找到想要的内容

点击Xpath
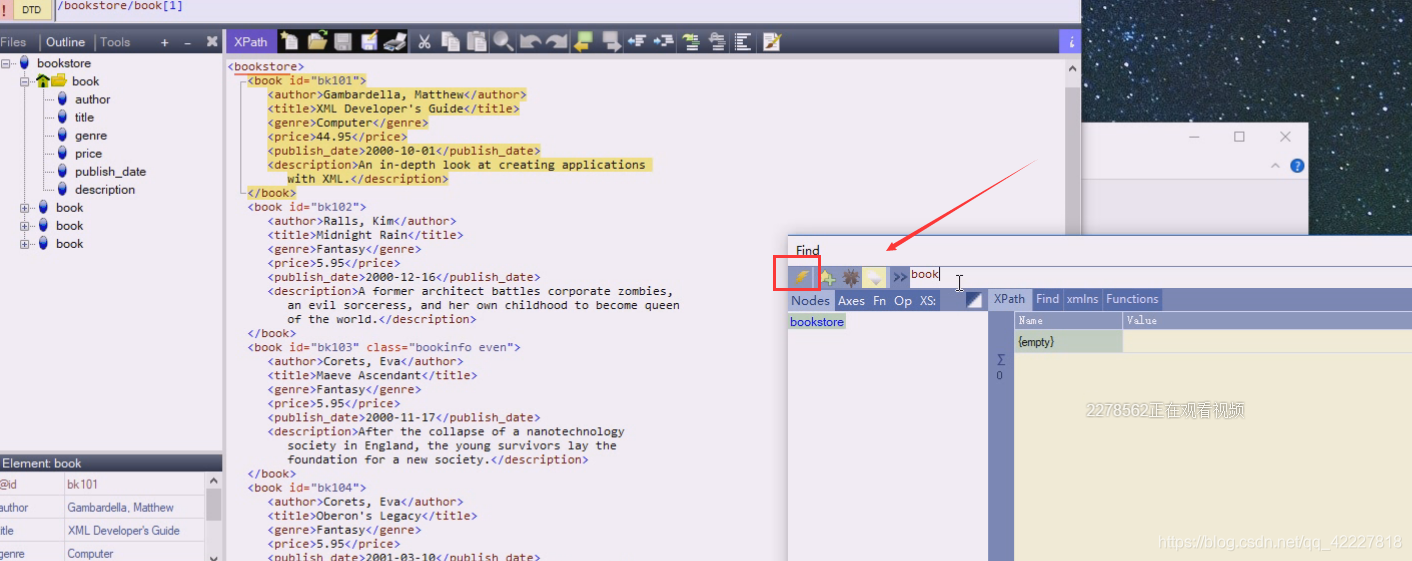
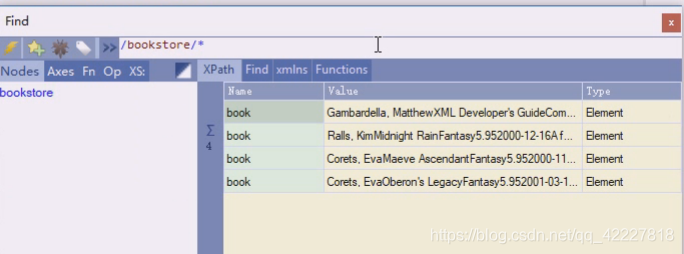
选择了/跟下的直接子节点bookstore,bookstore的子子孙孙都被选中了
当前节点下就没有title
当前家在bookstore
显示的是它,其实现在的家是在跟上
点这个闪电就是计算,现在就是空的
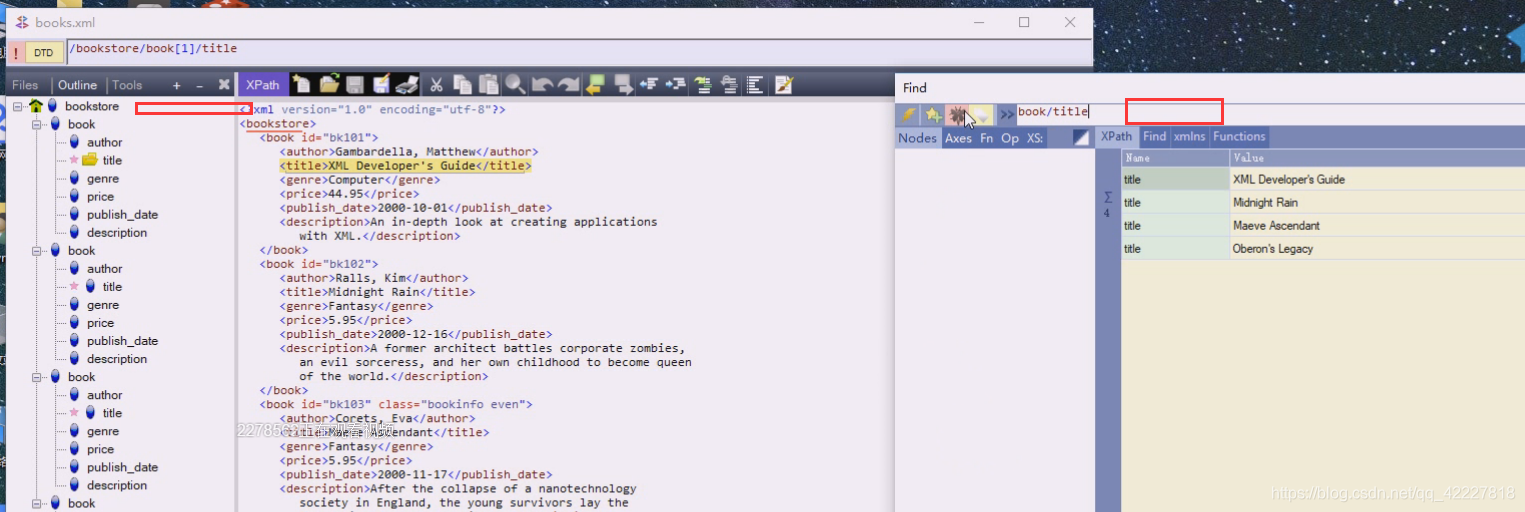
现在title就被选中了,当前book下只有一个title
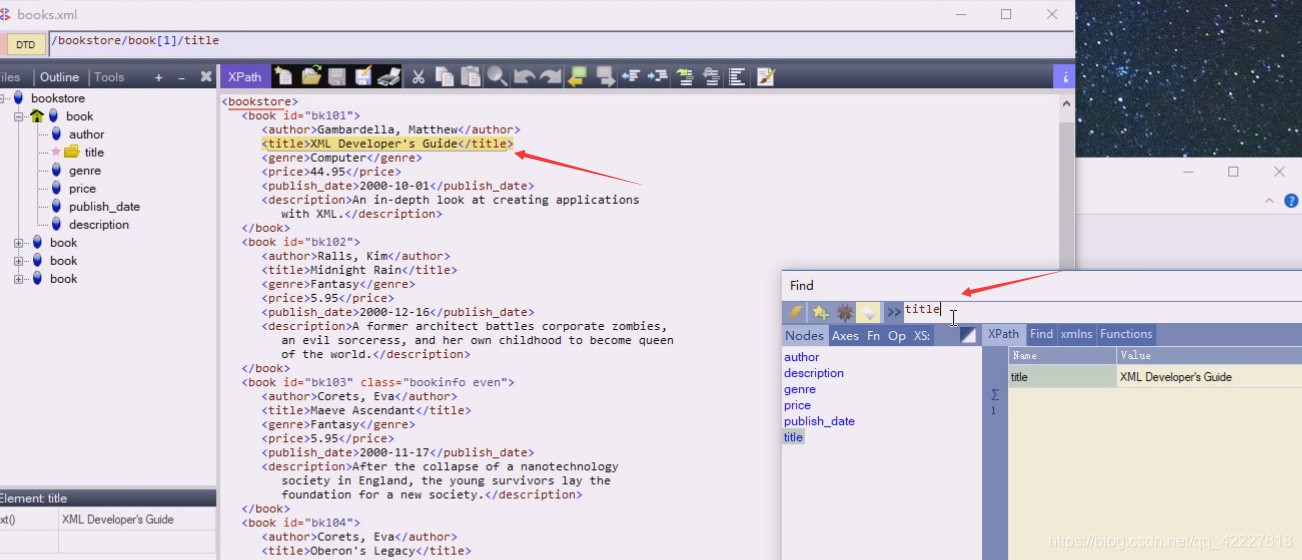
现在切到bookstore,有四个book儿子
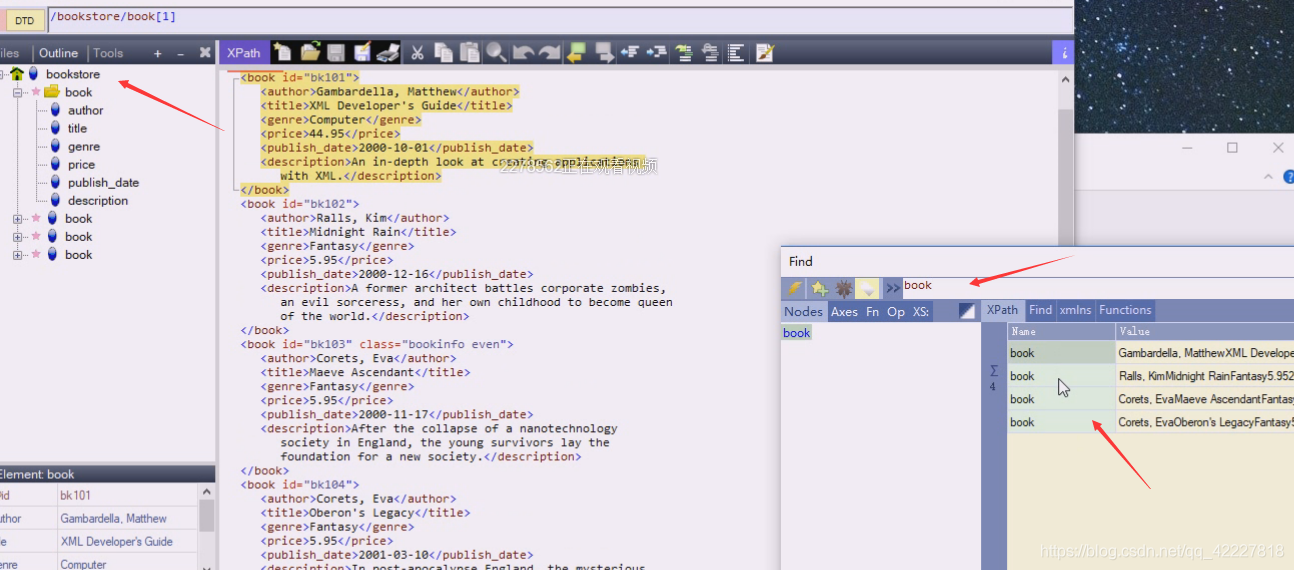
相当于写成当前节点下的book节点有哪些
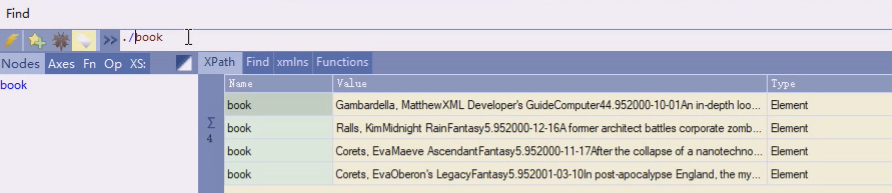
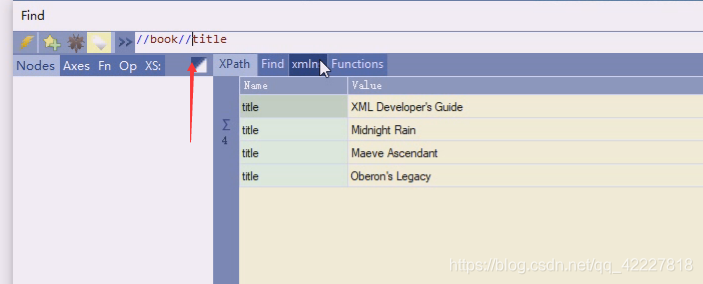
这样写跟当前节点无关,这里是从跟开始,忽略层次,任意一层找到title,4个book里就有4个title。最简单偷懒方法就是这么写,找到所有title
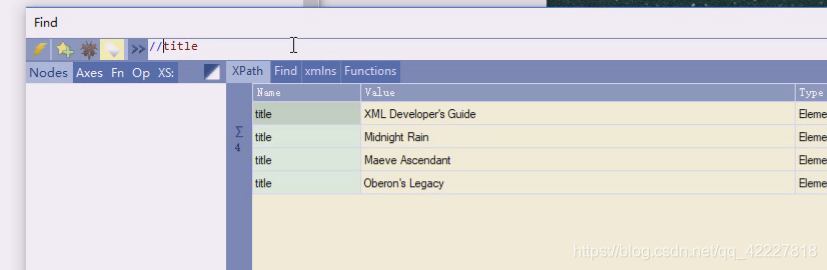
如果要找book下直接子有title,其他不管,//book从根开始的所有book
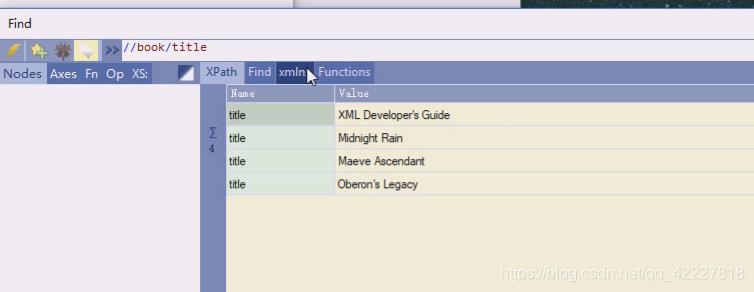
这就是book子孙节点的title,一般XPath结构是固定的,不然没办法写
这种是标签来选择
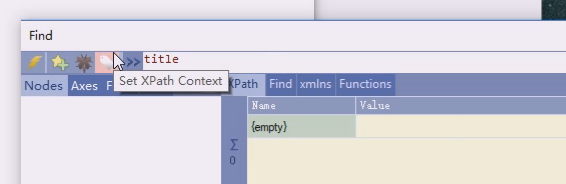
相对路径
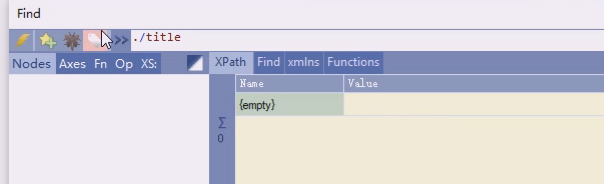
绝对路径

相对于当前节点所有title
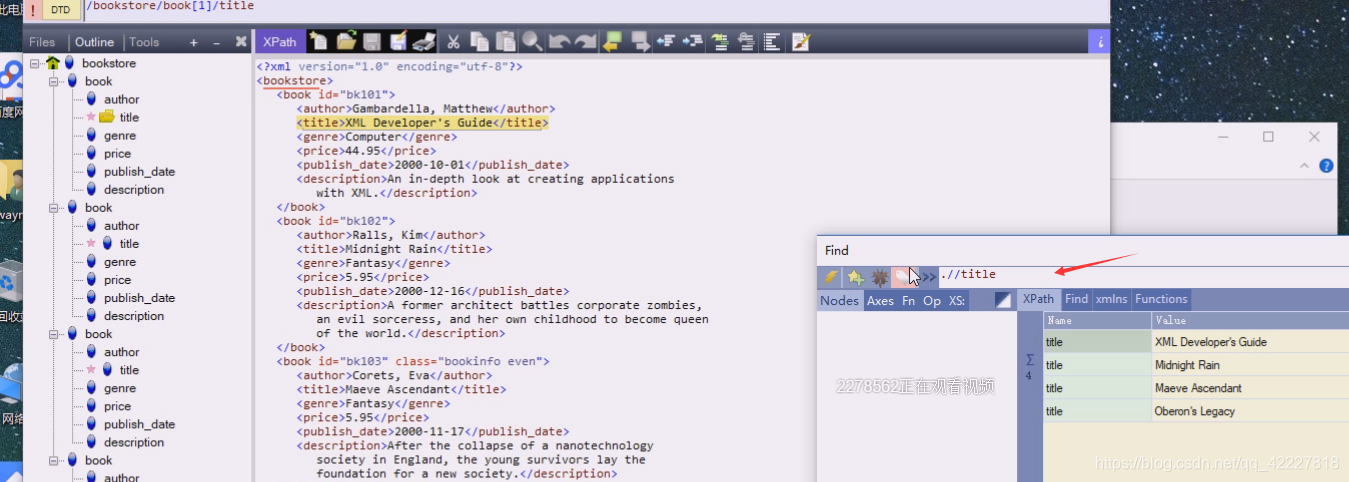
根下找book是找不到的

当前节点切到bookstore就可以找当前节点下的book下的title

从根开始,任意层次下的

从当前节点下的book任意层次下的title

属性name是class的
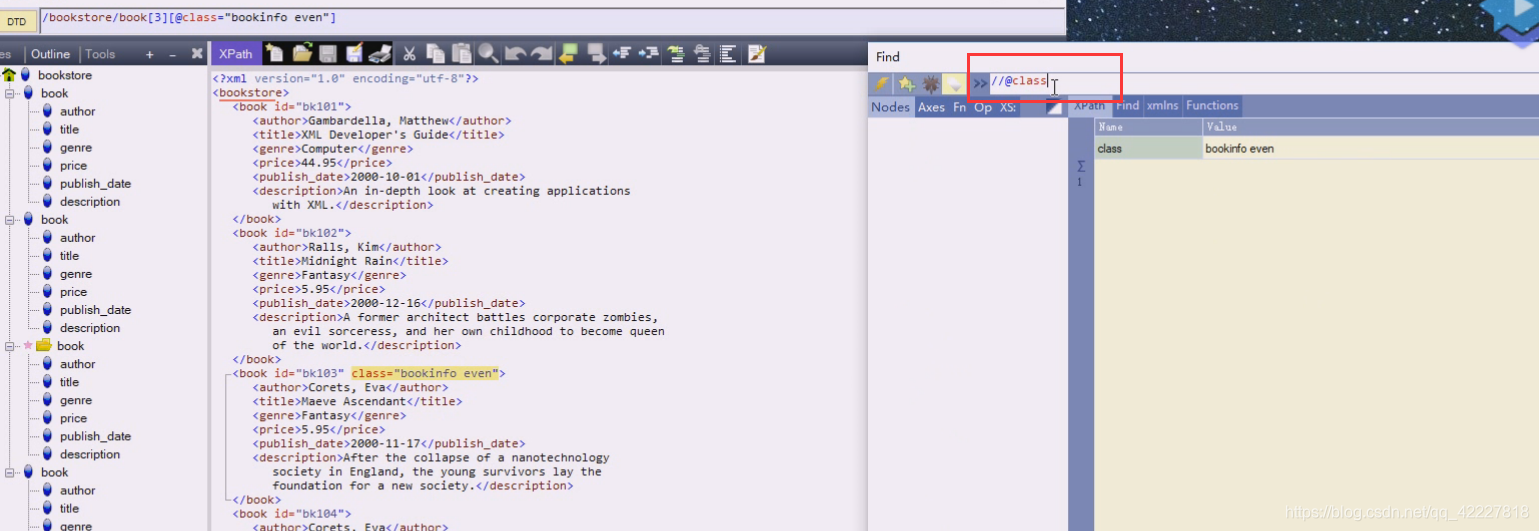
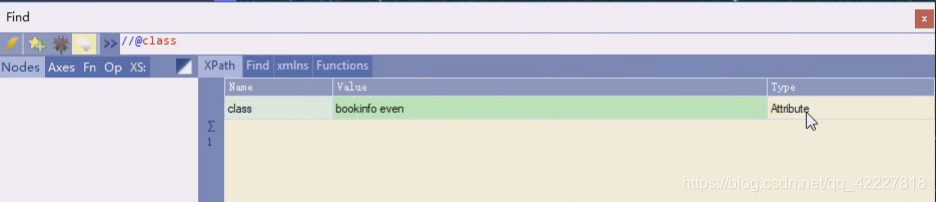
这里是attribute,说明是一个属性节点
属性一般都用任意节点下的什么东西,因为哪个标签上有属性是很难的定位
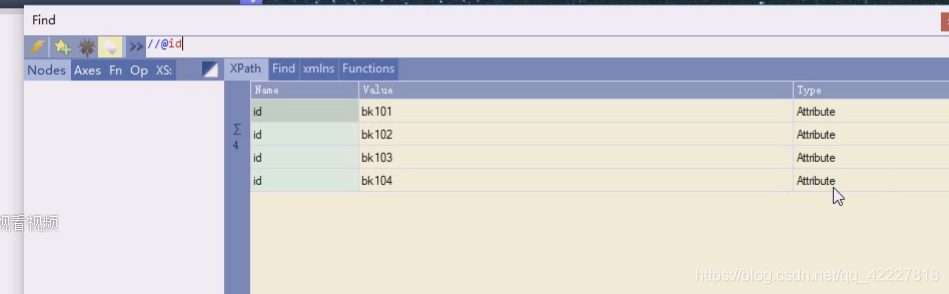
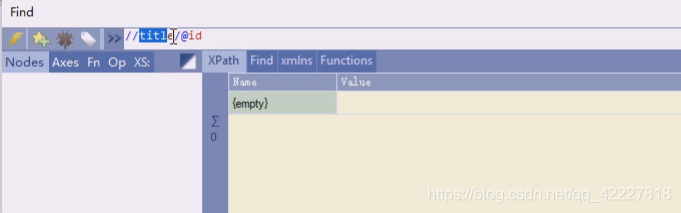
任意title下的id是没有的
所有的book有id的book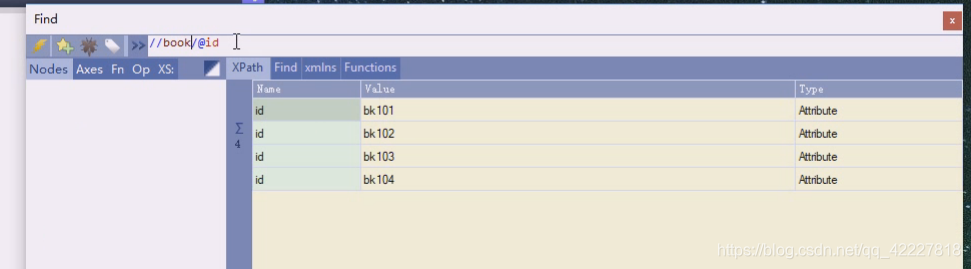
这里的删除就剩三个了
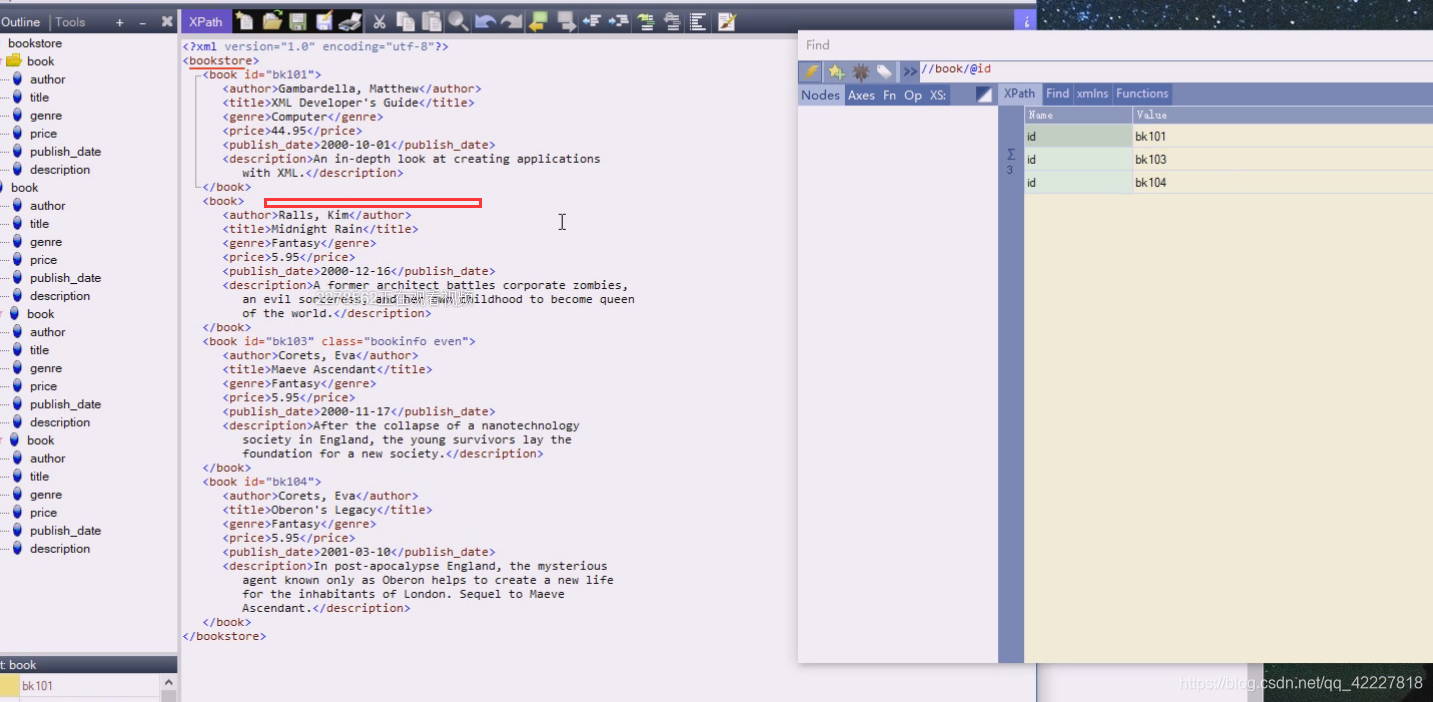
改回来就有了
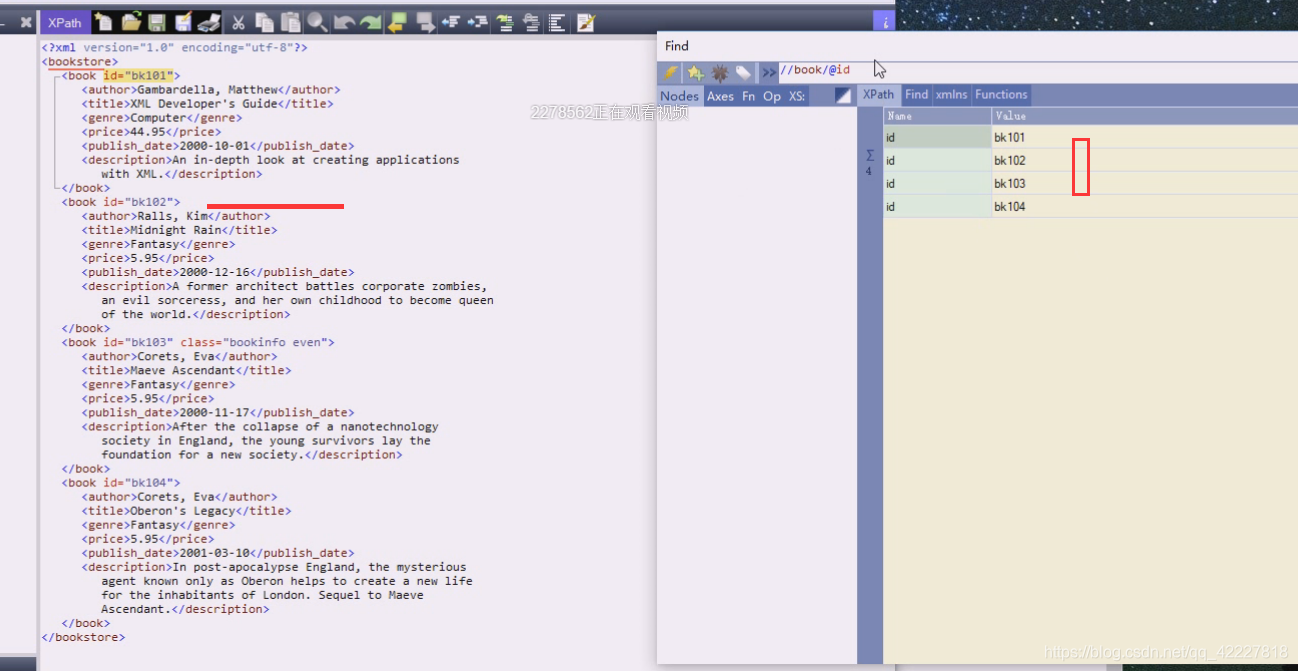
这种写法相当于匹配,所有book下属性是id的id是谁
返回的是属性节点类型
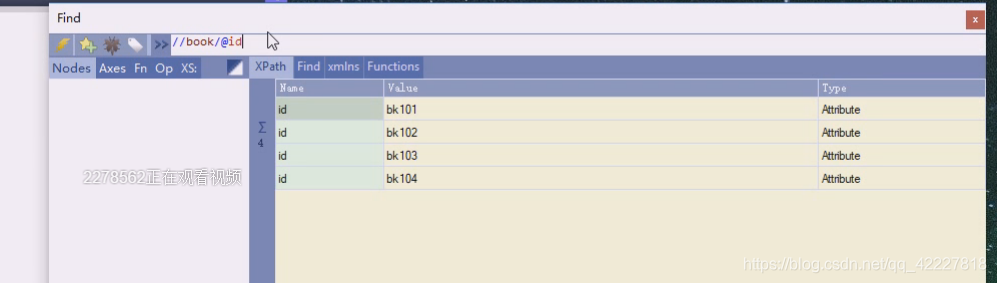
如果不写就是找book下的id标签
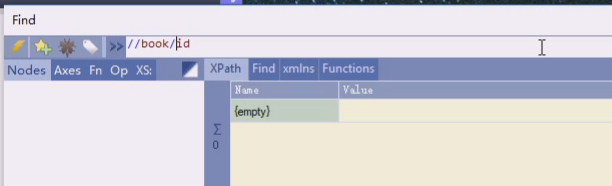
[]是谓语,谓语就是查询条件,这样相当于属性id必须有
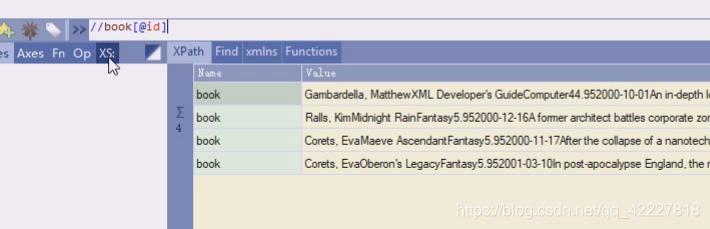
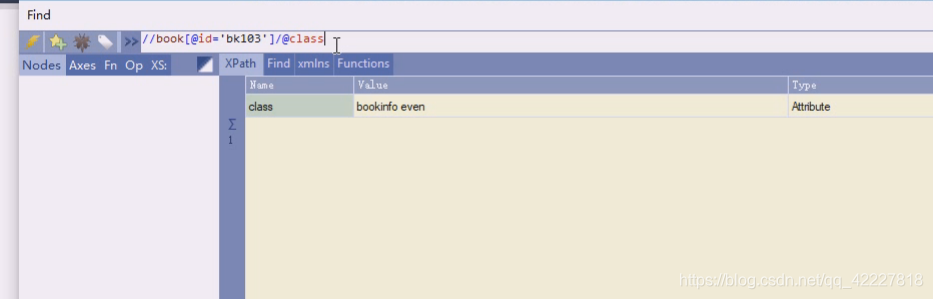
找class

还可以把属性的值写上


103就跑第三个上了
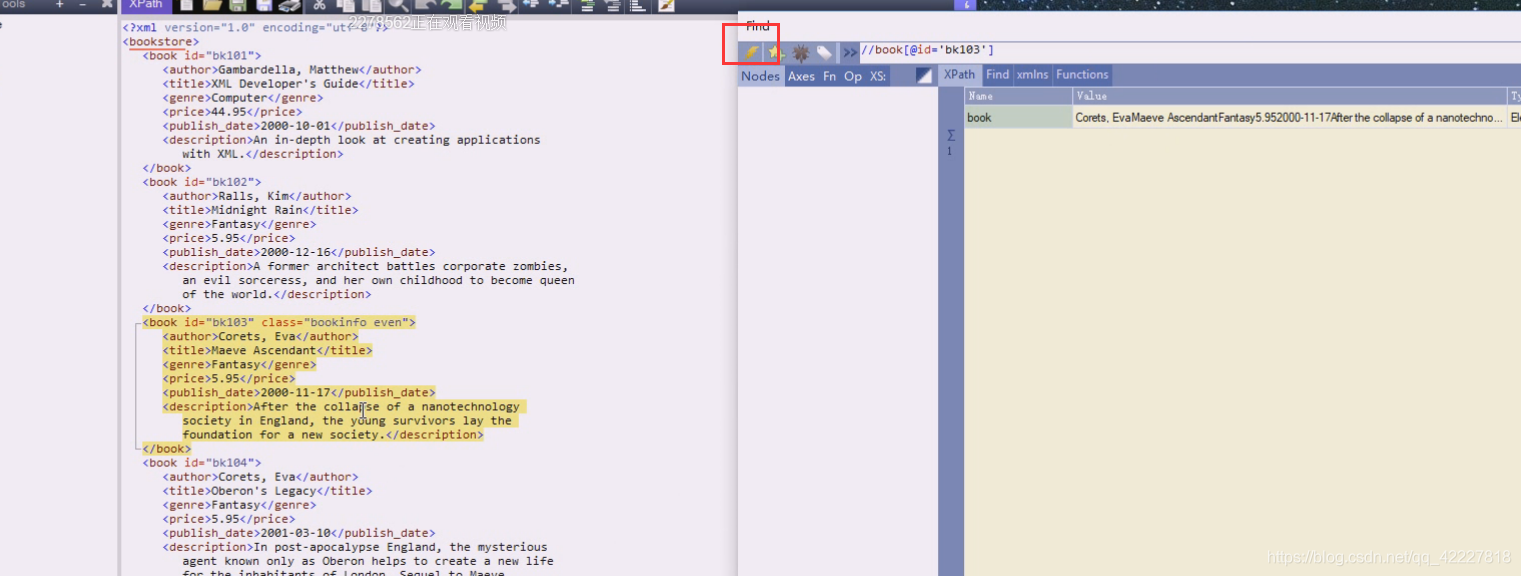
这个意思就是条件满足的book是谁
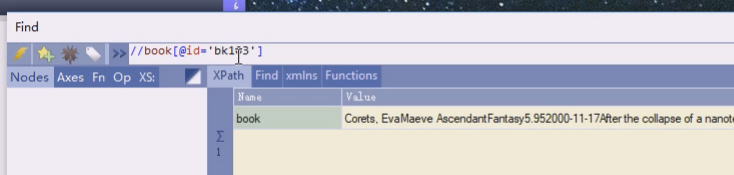
里面还可以当作数组看,第一个是谁,第二个是谁
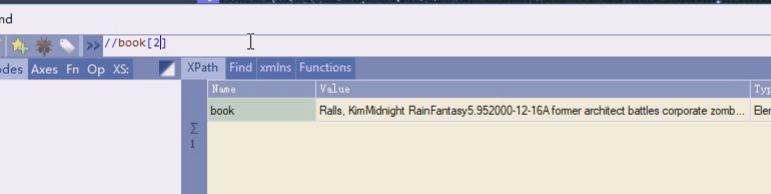

book下的title
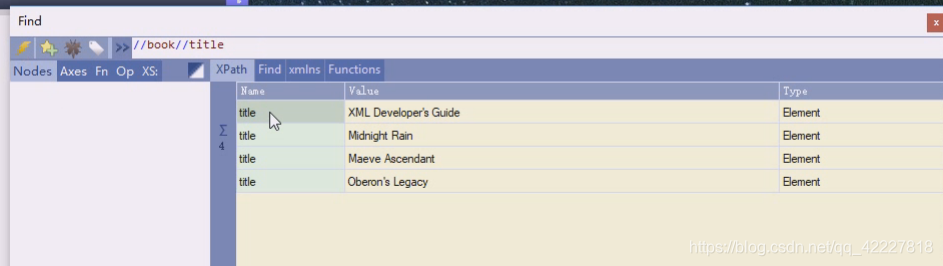
找第一个可以
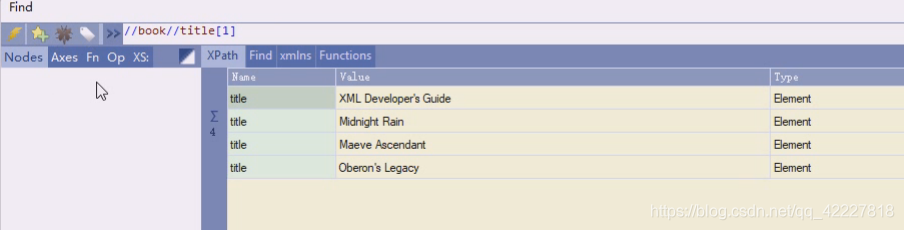
比如选第三个下的title
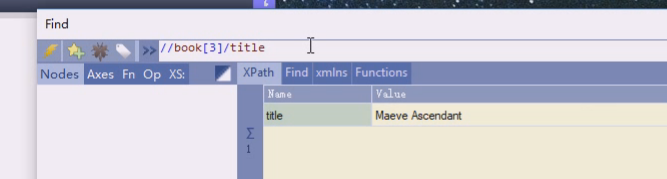
这种写序号的方式很少用,对于一个很大的xml,不可能自己去数第几个,节点很多,要定位到其中的一个,应该用特征而不是序号,因为节点是可以插入的,真的定位可以用某个book的id来定位
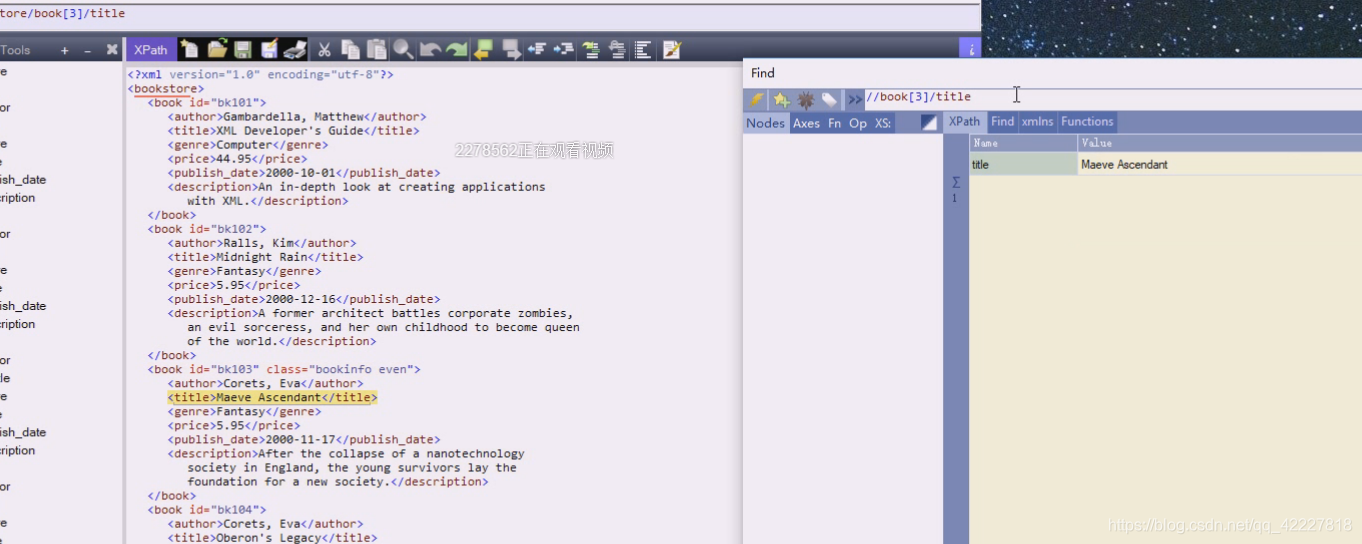
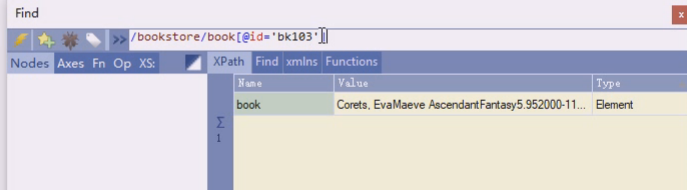
用属性来定位
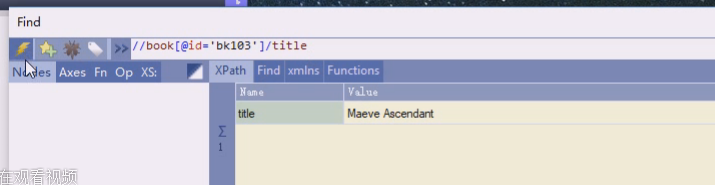
这样是即把id做条件,又作为一个显示的东西,id=bk103的book,的id属性值是多少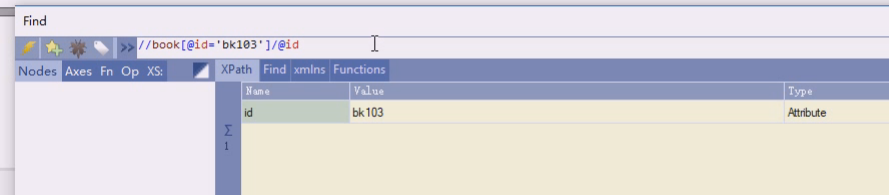
通过id可以做唯一的定位,看其他 属性,price,title这样
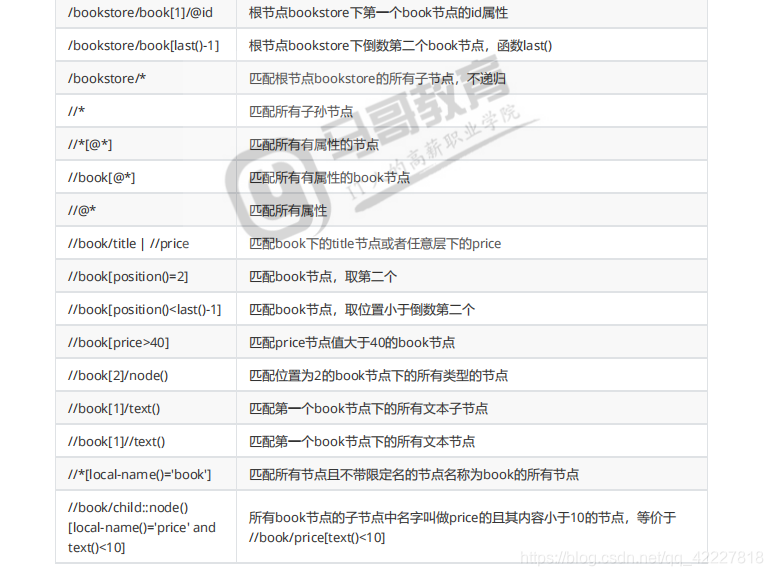
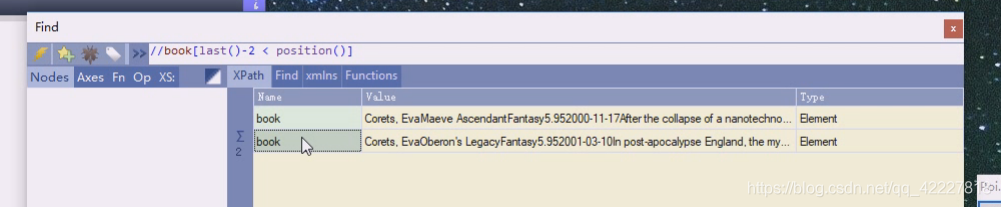
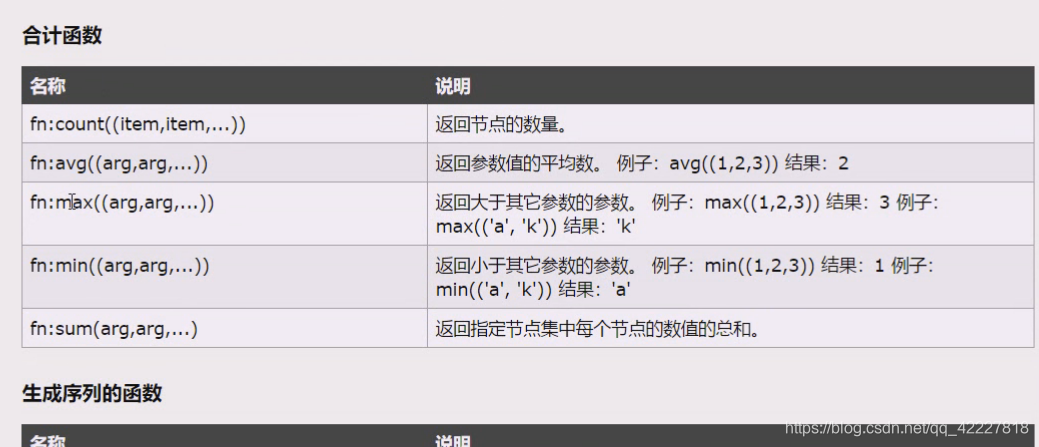
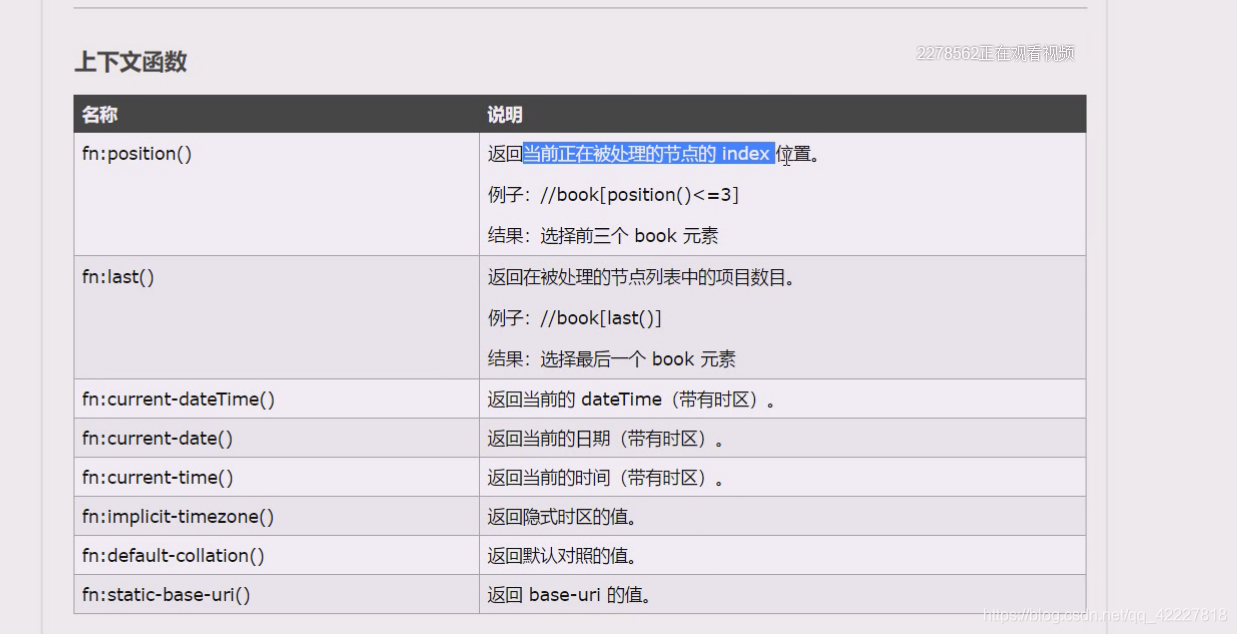
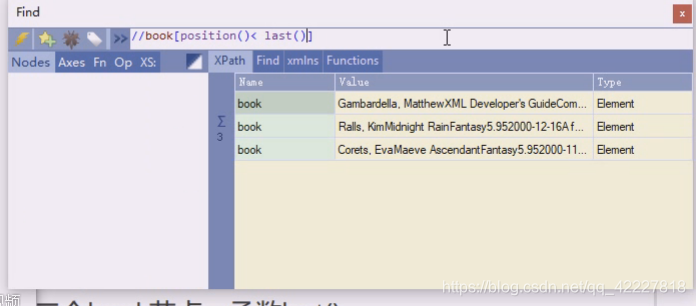
这是属于函数,常用的就是last和position这两个
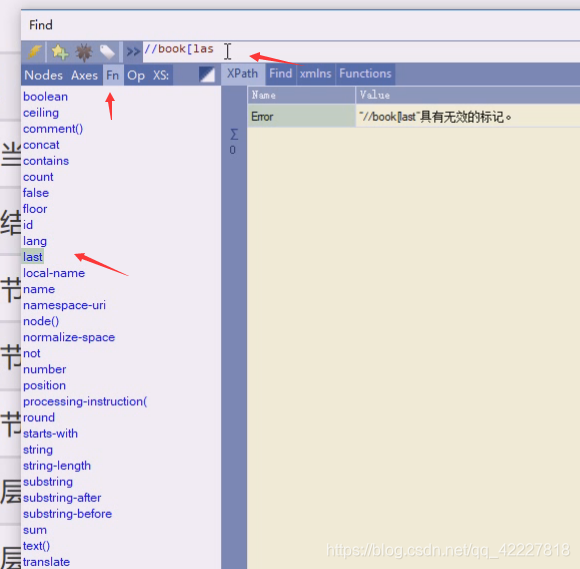
last是最后一个
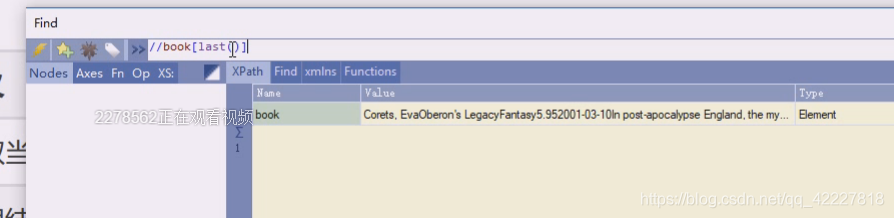
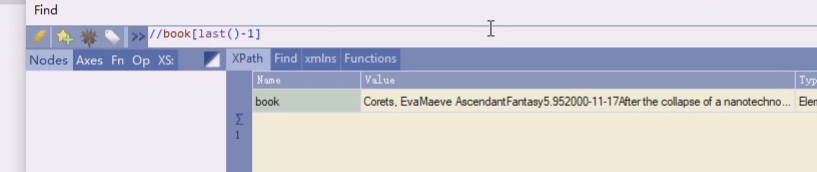
倒数第二个last()-1
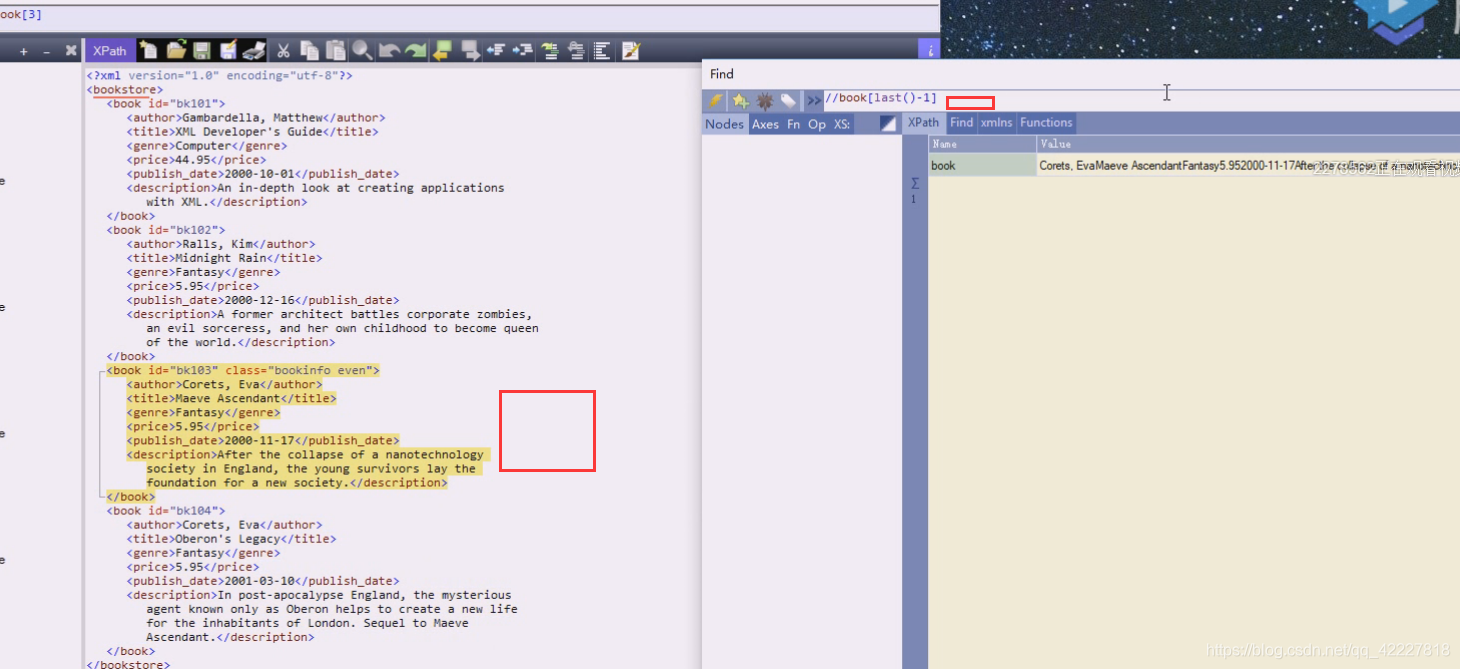
last()-2,这样是一个固定值,在这里last相当于是个4
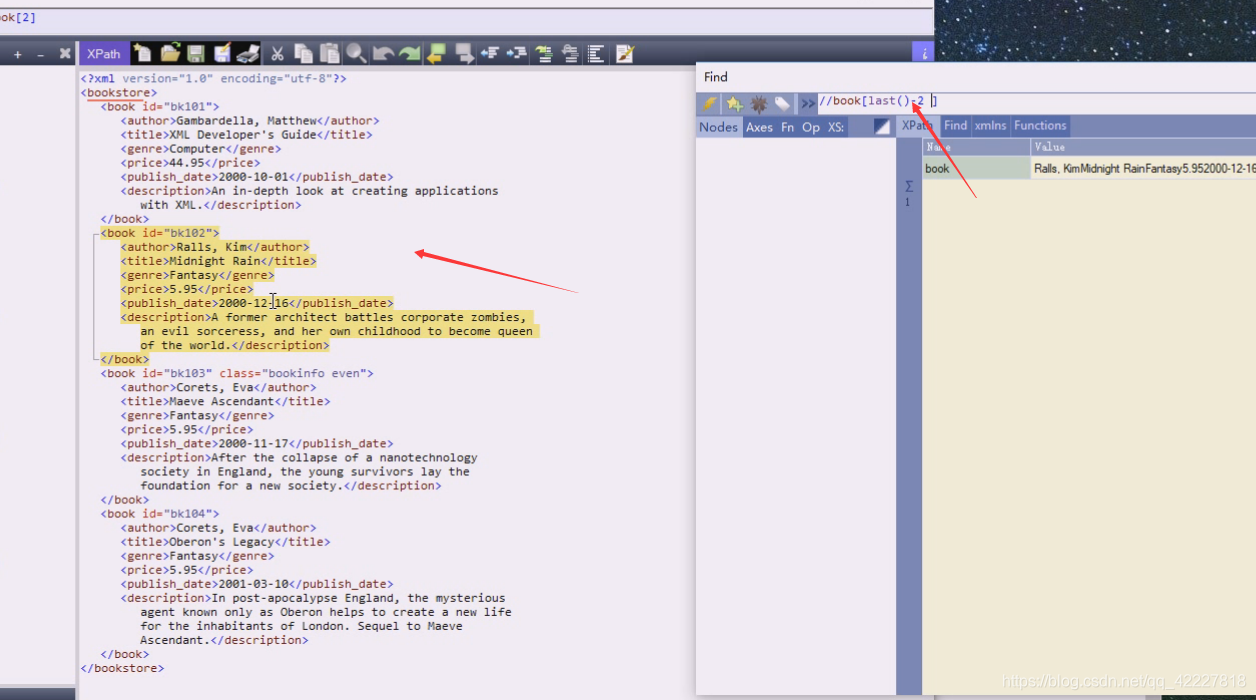
position指的是位置上的号码,也就是显示的是他们两个值的比较,比较后得到的一个值

这些都是函数
返回当前节点的名称
聚合函数
position返回正在处理的index的位置
要求position小于3
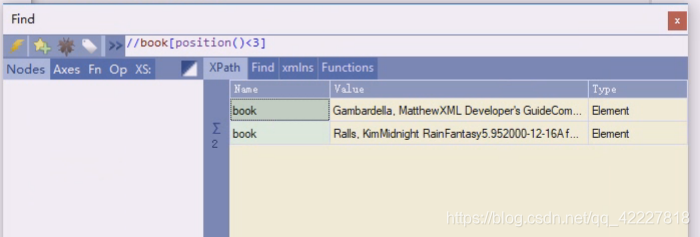
小于3的只有 1,2
小于last,last是4,就是1,2,3,这一块中括号里也是条件
bookstore下面的所有,这个所有并不能突破对斜杠的定义,就是4个book
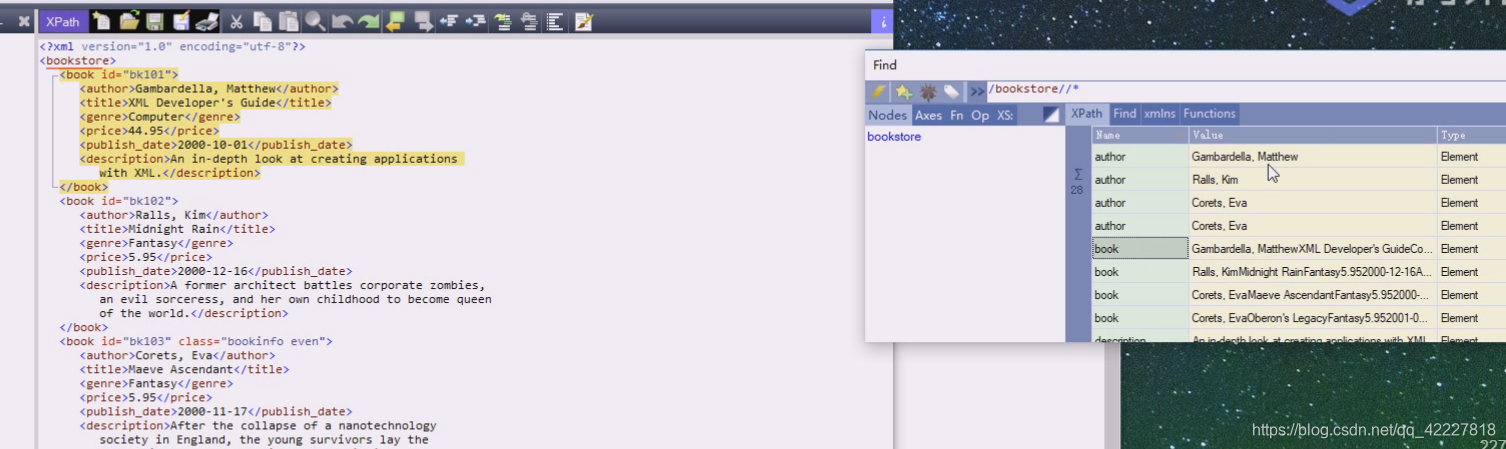
双斜杠,就是在bookstore下的所有的节点,选的都是标签,所有的element
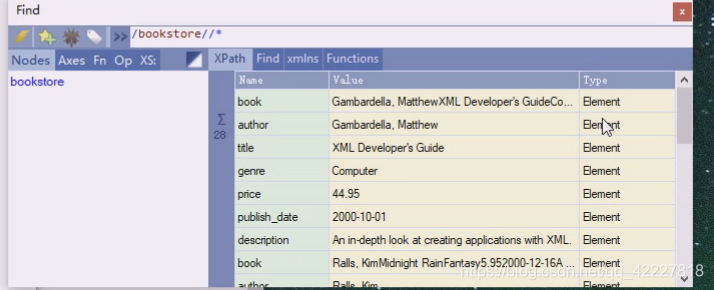
也就是bookstore下 的所有子孙节点
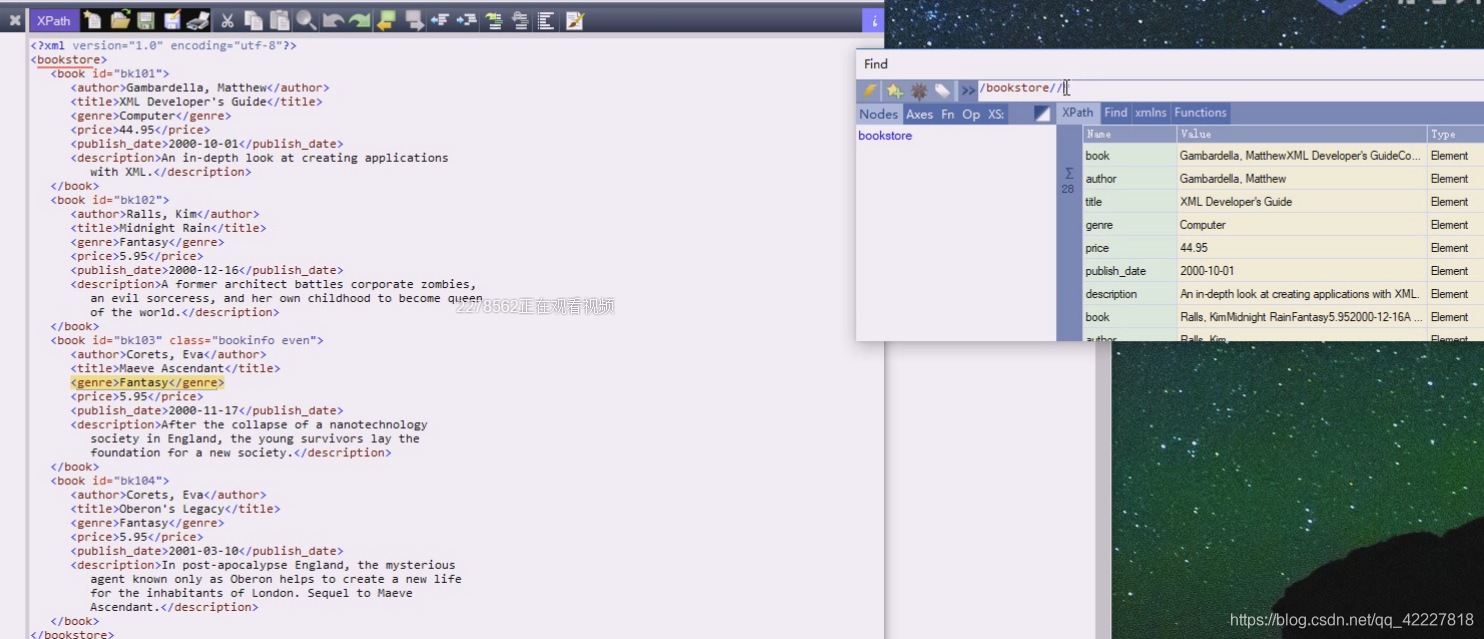
加@,就是子孙的所有属性节点
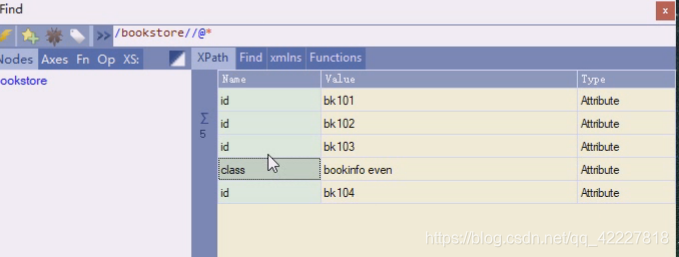
bookstore下有4个book
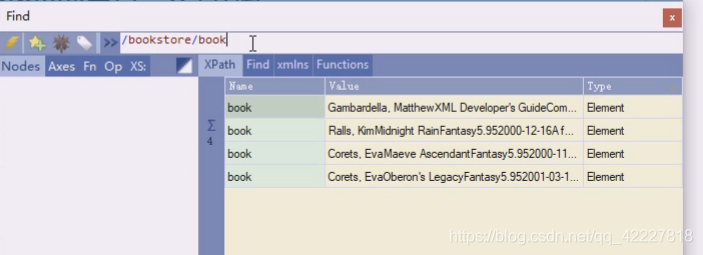
[]谓语可以加条件,条件可以用属性来写
看看能不能选底下的子节点来判断,现在是有price的都有谁
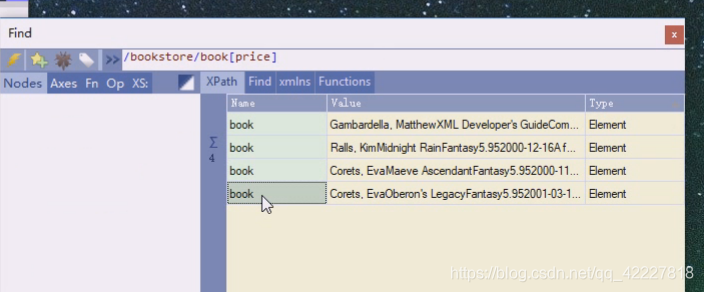
price都是数字
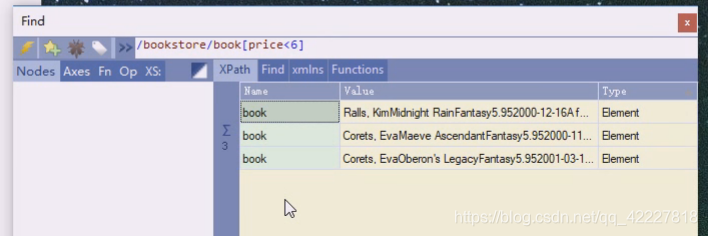
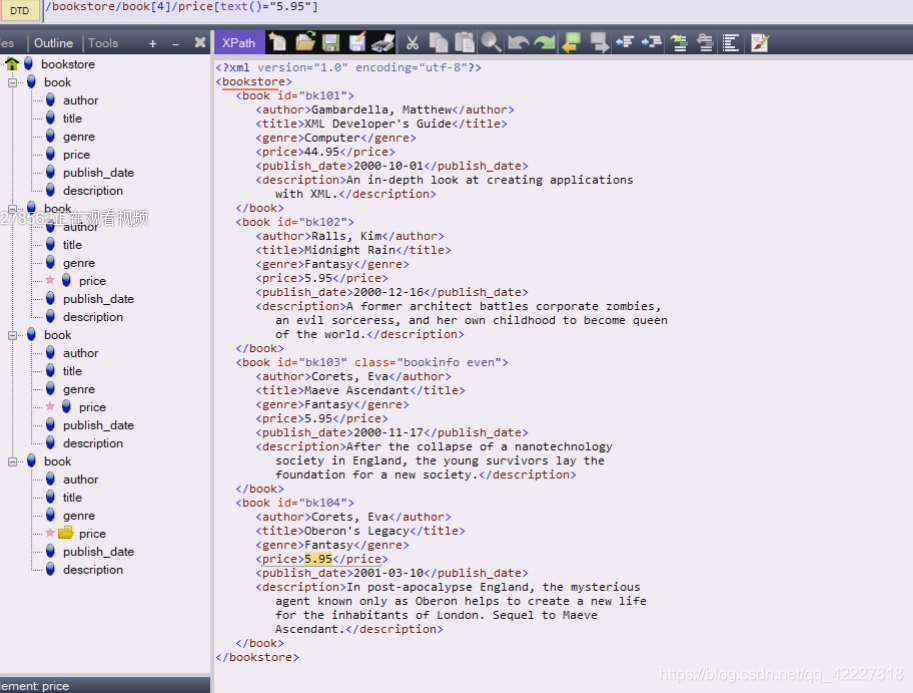
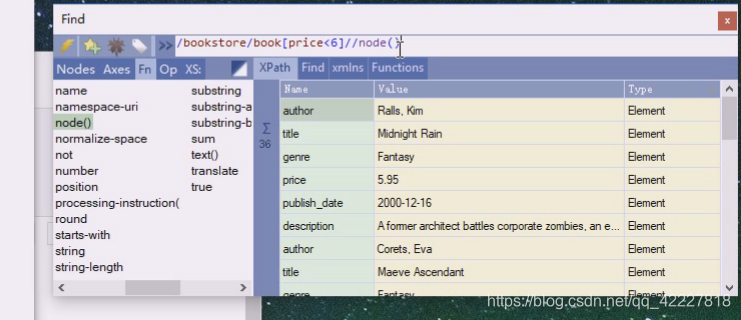
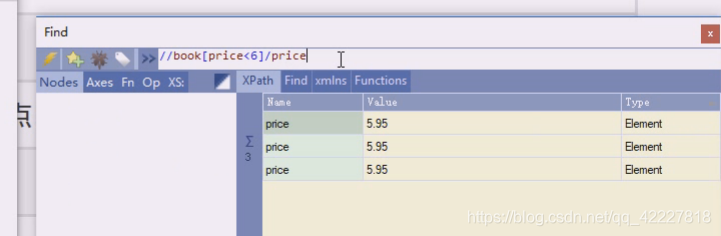
price小于6
这相当于在前面的基础上再往下问一层,有哪些节点
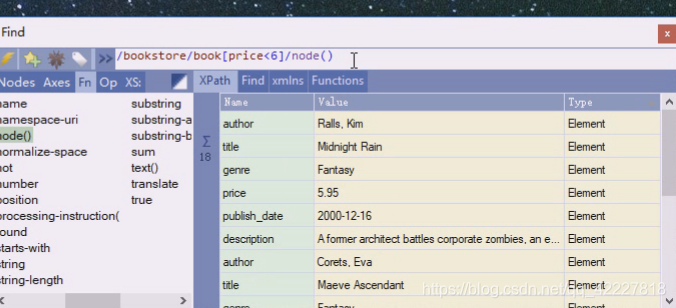
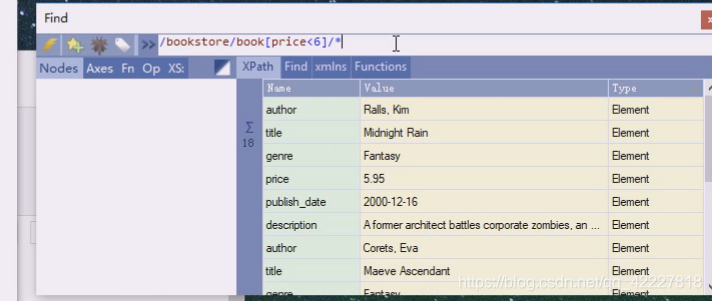
加个*号也一样
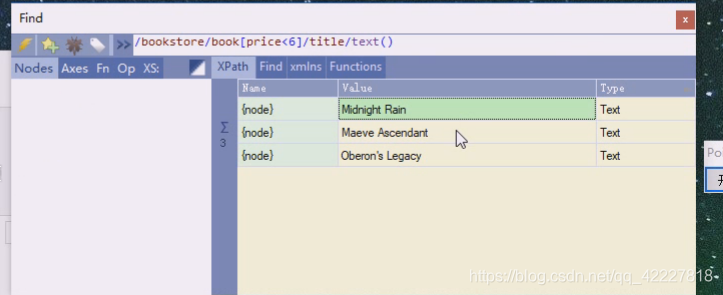
三个title,意思是加个小于6 的所有节点有没有直接节点title,title里面的文本是什么
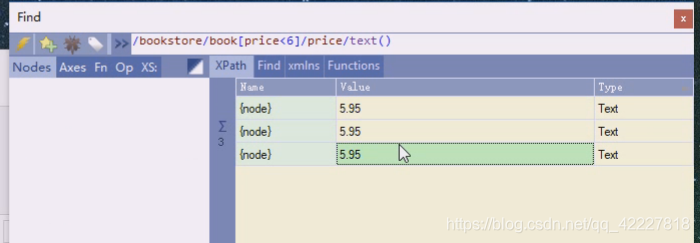
改成price就全是价格,因为我们非常在意标签内有什么文字,我们用子节点属性,特性锁定一个标签,定位一个标签后,会在里面去读取文本的内容,这个内容才是我们真正想要爬取的内容
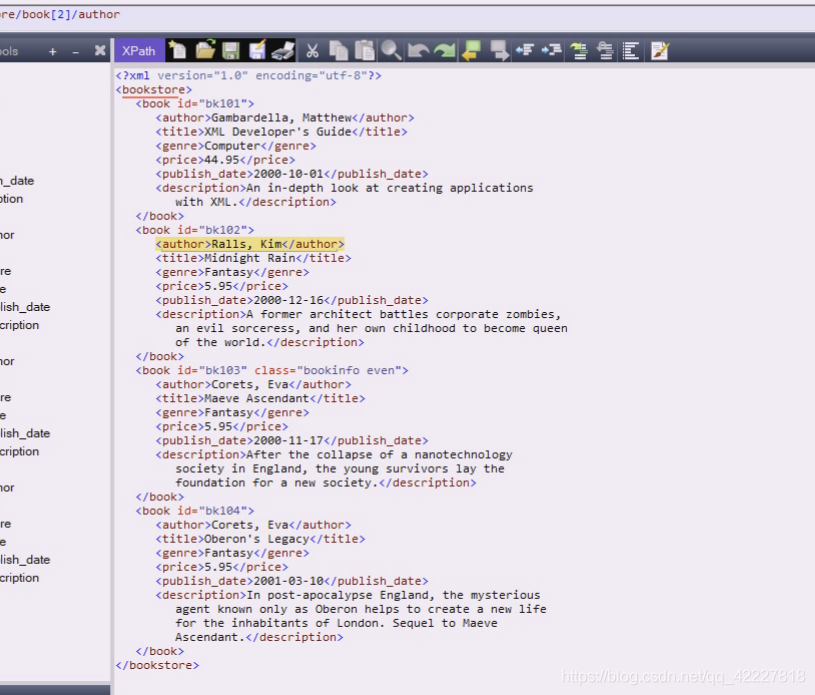
*现在就是选择符合条件的所有book下(102,103,,104),里面只有文本,星号代表所有的标签
所以如果要所有文本,直接写text就行了,这个text是它子里面的文本,现在book子里面就不是文本
所以要用//两个斜杠找任意层次下的
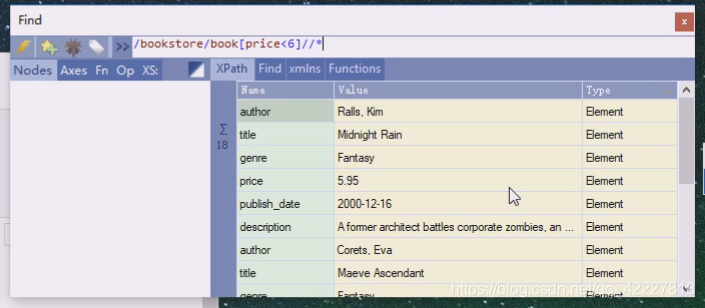
上下两个是相当的
任意层次下找到所有文本节点

node()跟*星号是一样的,是返回的所有元素节点,其实就是标签节点

写XPath,用text取里面内容是必须会的


这是根/下任意层次的所有节点
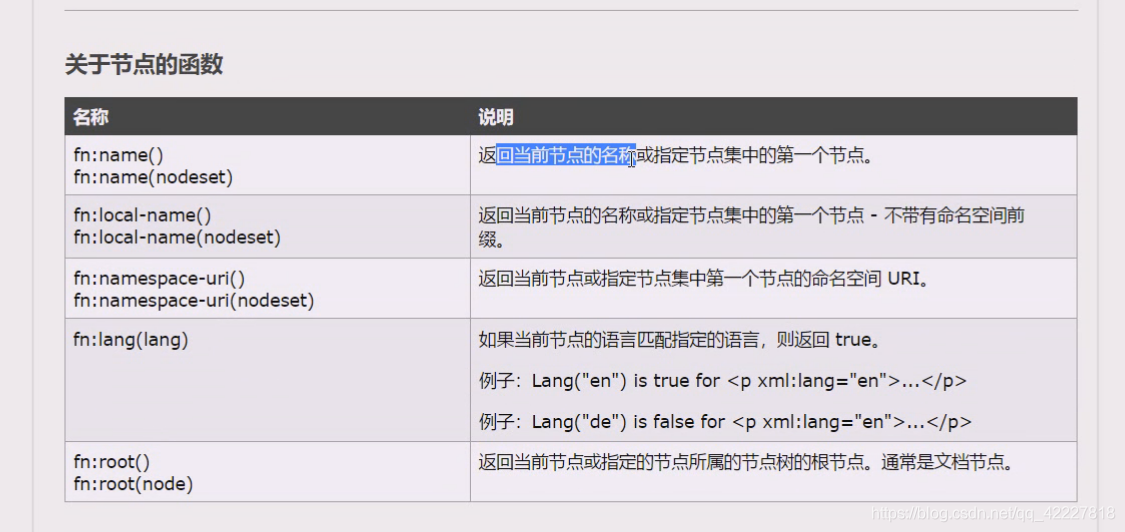
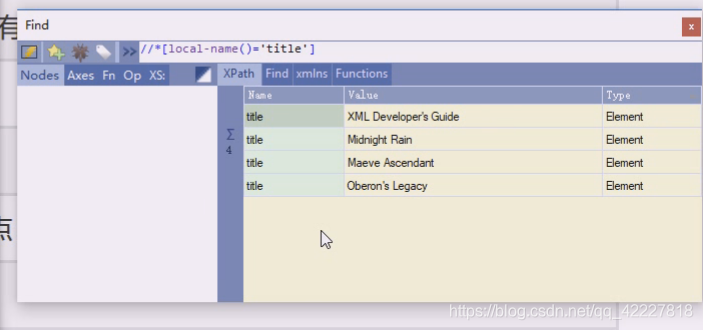
满足一个谓语,local-name,这个意思就是他们有名字,每个标签都有名字
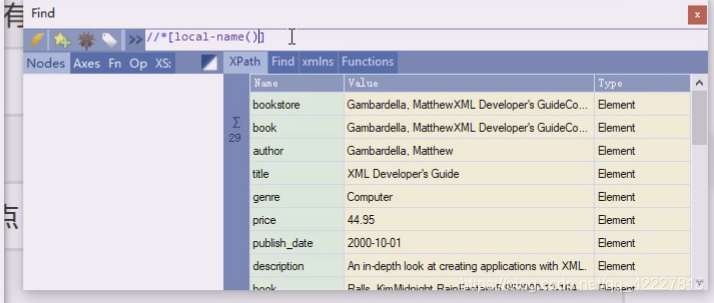
让它的名字等于title,所有的标签,自己名字等于title的
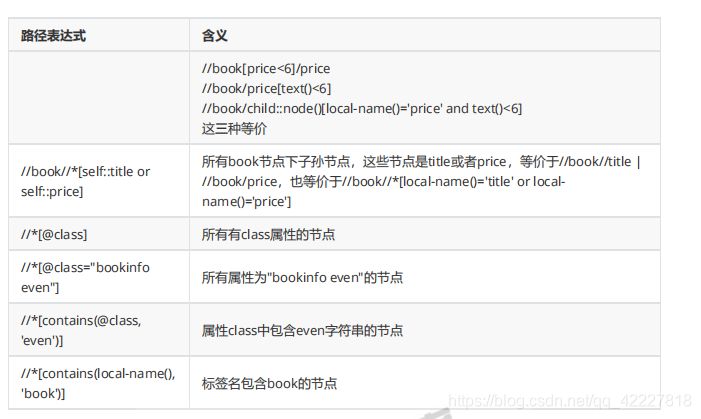
这个更复杂

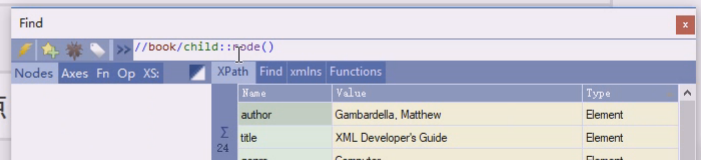
node代表节点,然后光有孩子没用+上node,等于 所有的孩子节点
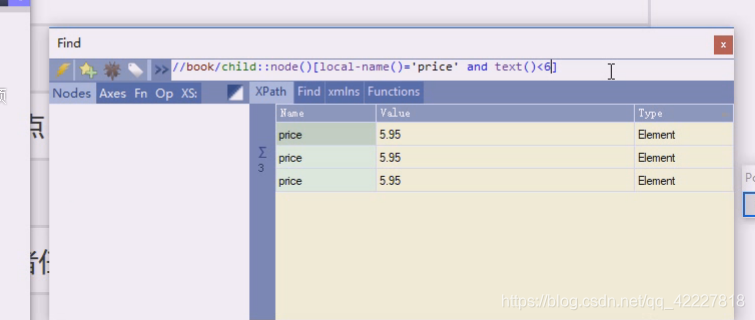
加一个谓语,让它你名字等于price

and就是,所有的孩子节点,还必须有文本才可以,就是它的价格小于6才可以
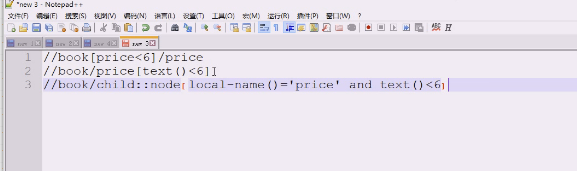
上面的就等价于下面的
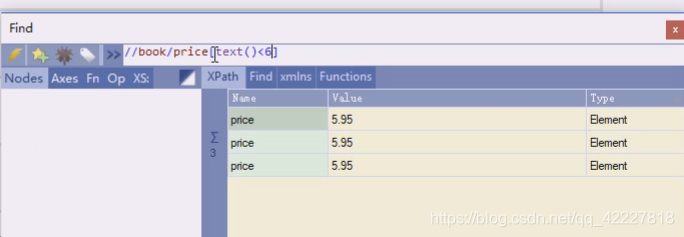
还可以这么写
三种写法
第一种book条件是什么,第一种你写的price,返回的类型就是节点
第二个book直接price要求内容小于6,虽然有条件,返回的还是节点
第三种就比较麻烦。node,返回的还是节点
每一种后面加个text返回就是文本 了,text包含不包含内容可以用python来做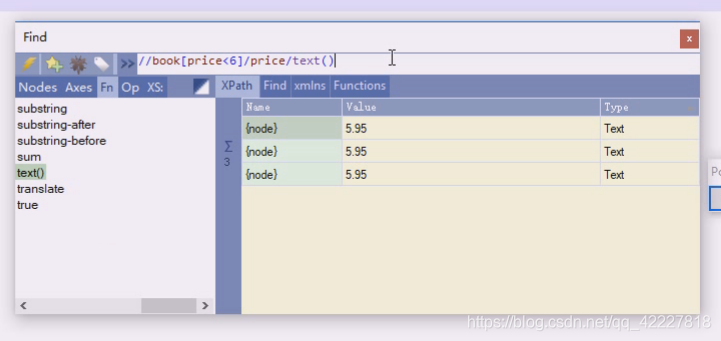
我们先要把数据用XPath过滤的差不多了,然后再用python处理

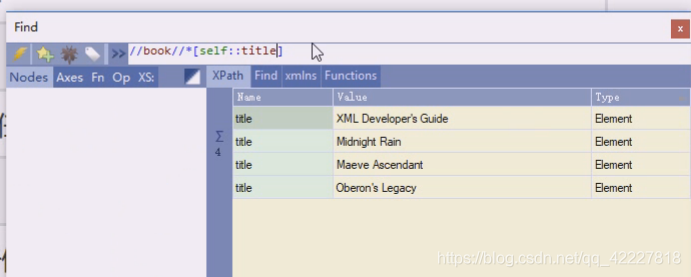
self是指节点本身title,

book节点下所有节点
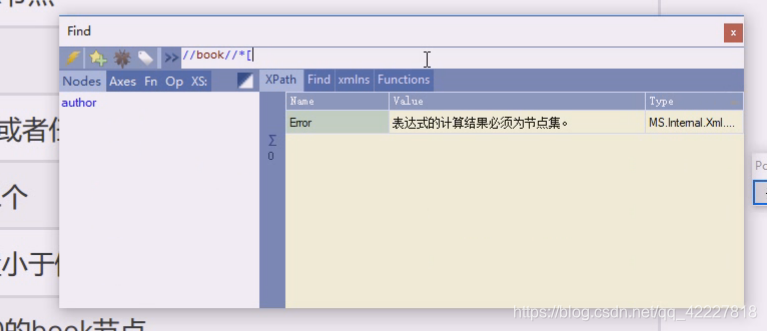
加上条件,这里就把title拿到了,就是self是title的,下面就可以条件了
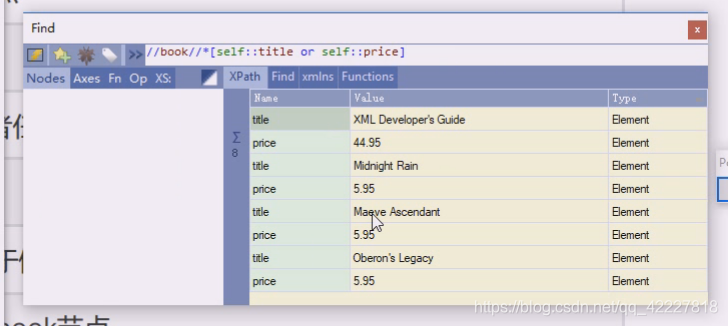
title和price都拿回来了。轴可以不用
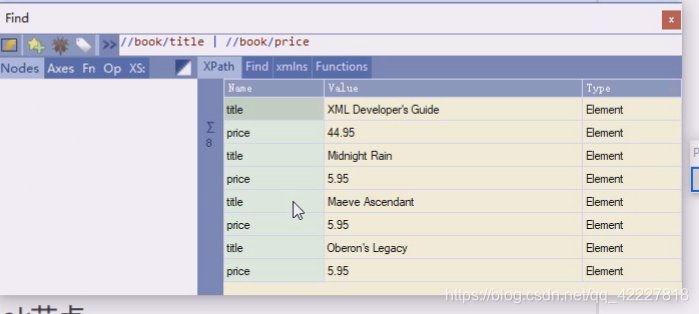
或者用这种方式来写
用local-name就写起来太累

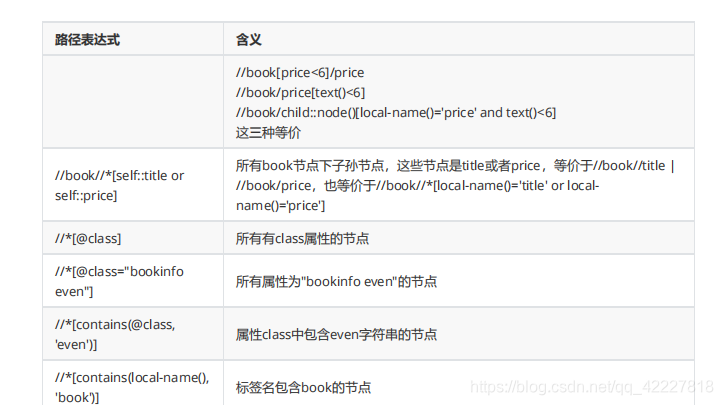
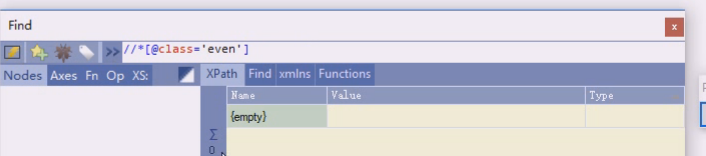
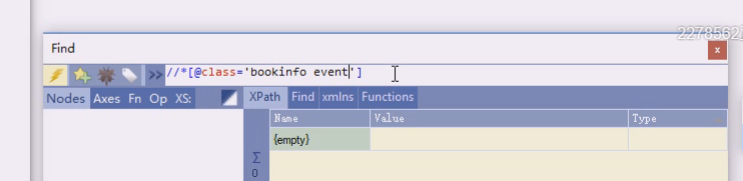
所有节点中条件是class,这个class特别之处在于两个class
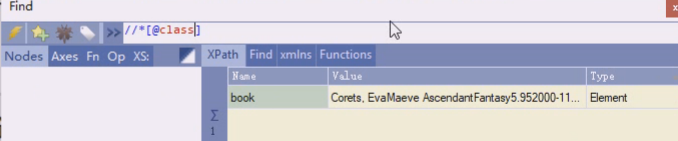
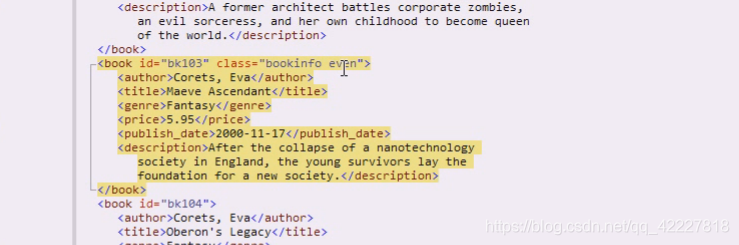
这是两个class,在样式表里,两个class相当于任何一种都可以作用于它。比如一个显示bookinfo的样式,另一个控制奇偶行

单独等于bookinfo就不行
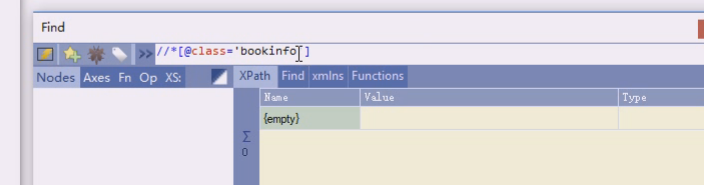
一般原文写成什么样,你就需要什么样子
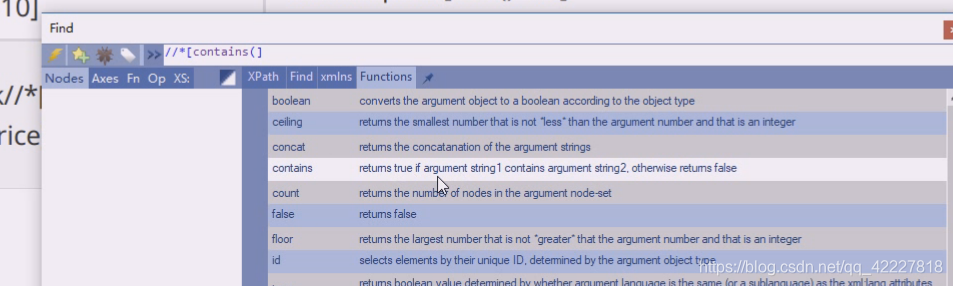
@class其实可以当做一个变量,这里有函数,contains包含,是个两参

看看local-name,能不能嵌套,包含book就选出来了,这是函数嵌套,local-name会返回当前名字
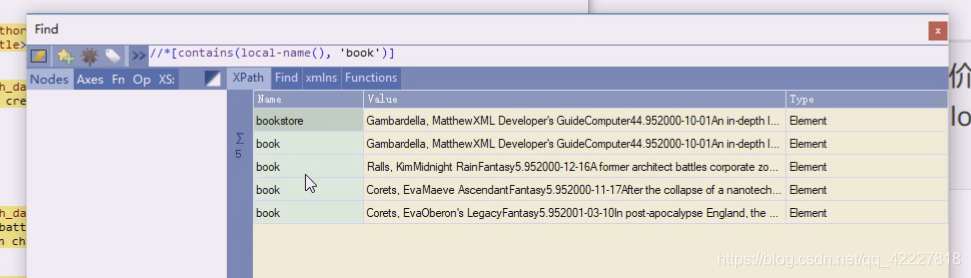
前面加@符号才能表示属性,要取当前名称需要借助函数local-name

XPath就要用这种表达式来解决问题,用这些函数来定位想要的标签以及从标签中提取想要的文本