微信公众号原文链接
网易数读是一个数据新闻可视化栏目,致力于提供轻量化的阅读体验。其内容往往是结合时下新闻热点将相关数据可视化处理,并以精致的图文形式呈现出来。
举个栗子,大家感受一下人家的风格:
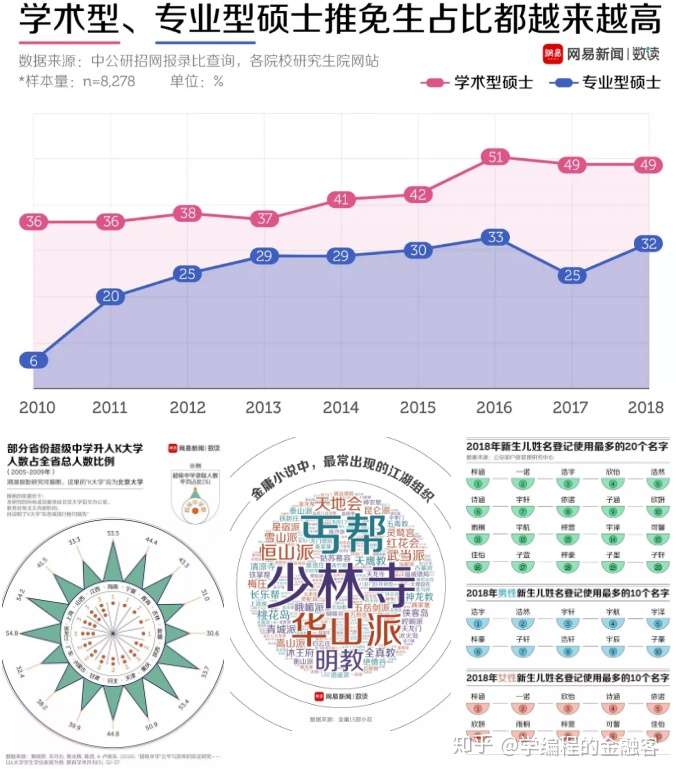
图片来源:网易数读
小笨聪觉得他们做的图表还是很美观清晰新颖的,就想全部下载下来学习学习。一张张手动下载好费事儿,嗯,人生苦短,我用 Python !
单张图片下载很简单,可以利用 requests 库的 get 请求,然后利用Response对象的content属性,将图片保存为二进制形式。即用下面5行代码就搞定:
import requests
url = 'http://cms-bucket.ws.126.net/2019/02/02/81b9ebced7514e66b4e969bab19af69c.png'
response = requests.get(url)
with open('2018百家姓.jpg', 'wb') as f:
f.write(response.content)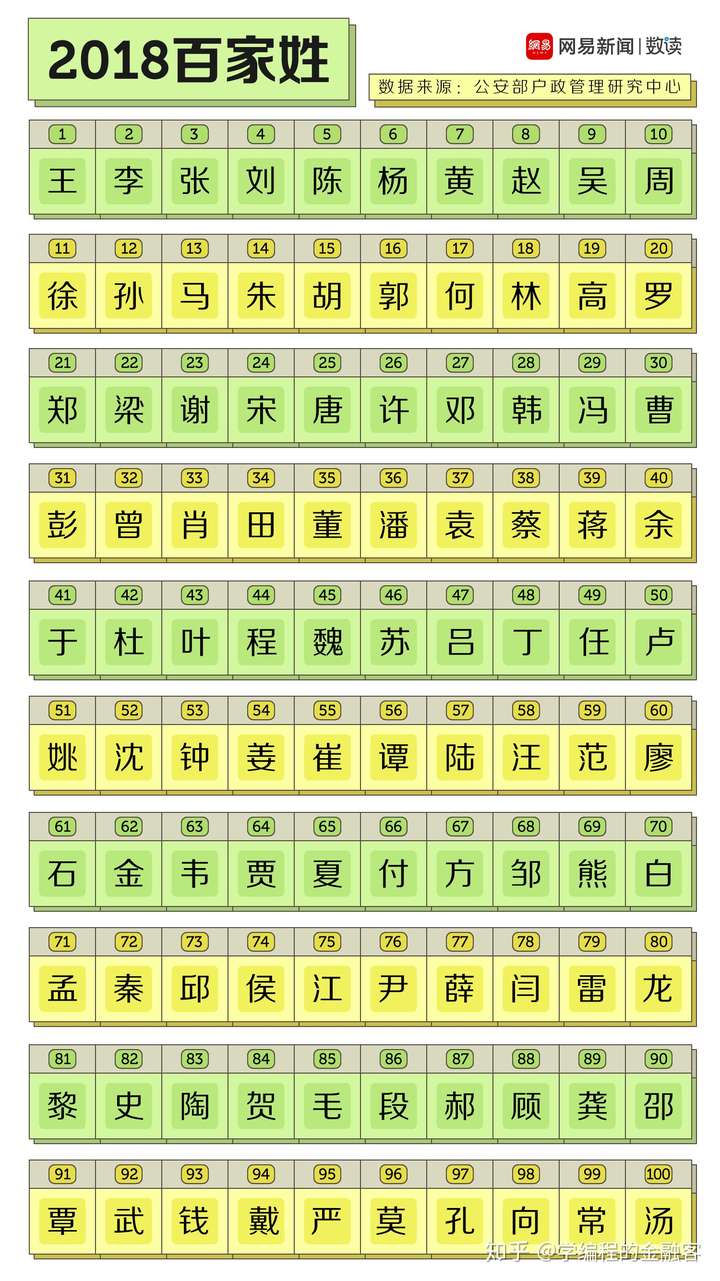
这个方法也是初学 requests 库时都会学到的;并且,只要修改 url ,任意图片都可以下载。 但我们的目标是下载网易数读的所有图片,这时该怎么写呢?
1.requests获取网页内容
requests库是python里的爬虫利器,小笨聪前面的几篇文章都有它的身影。对于想要快速学习的伙伴,我给大家推荐一个链接:
https://cuiqingcai.com/5517.html(崔庆才个人博客)
https://2.python-requests.org//zh_CN/latest/index.html(官方文档)
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
}
def get_page_index():
url = 'http://data.163.com/special/datablog/'
try:
response = requests.get(url,headers = headers)
if response.status_code == 200:
return response.text
# print(response.text) # 测试网页内容是否提取成功
except RequestException:
print('网页请求失败')
return None
def get_page_detail(item):
url = item.get('url')
try:
response = requests.get(url,headers = headers)
if response.status_code == 200:
# print(url) #测试url ok
return response.text
except RequestException:
print('网页请求失败')
return None2.解析网页内容
通过上面方法可以获取到 html 内容,接下来解析 html 字符串内容,从中提取出网页内的图片 url。解析和提取 url 的方法有很多种,常见的有5种,分别是:正则表达式、Xpath、BeautifulSoup、CSS、PyQuery。这里小笨聪采用了 BeautifulSoup。
def parse_page_index(html):
pattern = re.compile(r'"url":"(.*?)".*?"title":"(.*?)".*?"img":"(.*?)".*?"time":"(.*?)".*?"comment":(.*?),',re.S)
items = re.findall(pattern,html)
# print(items)
for item in items:
yield{
'url':item[0],
'title':item[1],
'img':item[2],
'time':item[3],
'comment':item[4][1:-1]
}
def parse_page_detail2(html):
soup = BeautifulSoup(html,'lxml')
items = soup.select('p > a > img')
# print(len(items))
title = soup.h1.string
for i in range(len(items)):
pic = items[i].attrs['src']
yield{
'title':title,
'pic':pic,
'num':i # 图片添加编号顺序
}
3.下载并保存图片
提取出的网址是一个 dict 字典,通过 dict 的 get 方法调用里面的键和值。然后建立文件夹存放已经过编号的图片。
def save_pic(pic):
title = pic.get('title')
title = re.sub('[\/:*?"<>|]','-',title)
url = pic.get('pic')
# 设置图片编号顺序
num = pic.get('num')
if not os.path.exists(title):
os.mkdir(title)
# 获取图片url网页信息
response = requests.get(url,headers = headers)
try:
# 建立图片存放地址
if response.status_code == 200:
file_path = '{0}\{1}.{2}' .format(title,num,'jpg')
# 文件名采用编号方便按顺序查看,而未采用哈希值md5(response.content).hexdigest()
if not os.path.exists(file_path):
# 开始下载图片
with open(file_path,'wb') as f:
f.write(response.content)
print('该图片已下载完成',title)
else:
print('该图片%s 已下载' %title)
except RequestException as e:
print(e,'图片获取失败')
return None4.下载结果
随便点一个看看:


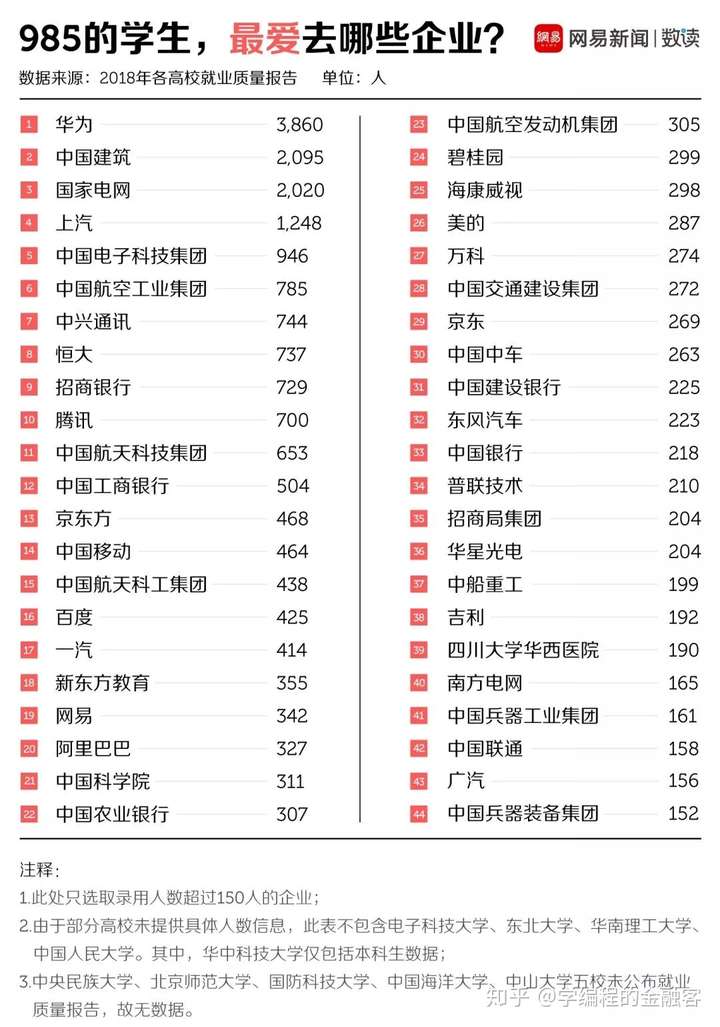
图片来源:网易数读
以上就是本次爬取网易数读图片的过程。
微信公众号“学编程的金融客”后台回复“网易数读”即可获得源码。(禁止商用,否则后果自负。本文所用图片侵删。)
往期推荐
1.流浪地球影评
2.北上广深租房图鉴
3.图虫网美女
4.猪小屁视频
5.拉勾网数据
你的点赞和关注就是对我最大的支持!
保存扫码关注公众号呗
