ES总览
目录
- 为什么选择ElasticSearch
- es名词解释
- master
- 概念解析
1、为什么选择ElasticSearch
- 数据库对于模糊查询以及分布式查询很困难, 而我们使用ES做一个全文索引,将经常查询的商品的某些字段,比如说商品名,描述、价格还有id这些字段我们放入我们索引库里,可以提高查询速度。
- 为了解决单机lucene数据存储量有限,以及lucene 分布式操作困难问题,采用elasticsearch,实现全文检索,倒序索引,分布式模糊查询操作,并且可以对存储数据进行备份。ES经常被用作文档数据库,这主要得益于塔的分布式特性和实时搜索能力。
总体来说,ES具有如下特点:
1.一个分布式的实时文档存储引擎,每个字段都可以被索引与搜索
2.一个分布式实时分析搜索引擎,支持各种查询和聚合操作
3.能胜任上百个服务节点的扩展,并可以支持PB级别的结构化或者非结构化数据
2、elsticsearch名词理解
集群:一个或多个节点(服务器)的集合,它们共同保存数据,并提供所有节点联合索引和搜索功能。
节点:集群中的单个服务器
索引:ElasticSearch存放数据的地方,可以将索引理解为MongoDB集合。
文档:类似于关系数据库中的行,但是每个文档可以具有不同的字段,不过通用字段应该具有相同的数据类型
类型:Elaticsearch 6.x版本中已经只允许一个索引下只有一个type
映射:字段数据类型包括text, byte, integer, long, float, double, boolean, date (格式包含"2018-10-01", 或"2018/10/01 12:10:30"),如果你的文档内容很大,而其中某个字段的内容有需要经常获取,可以设置mappings,将该字段的内容单独存储。
PUT my_index
{
"mappings": {
"_doc": {
"properties": {
"title": {
"type": "text",
"store": true
}
}
}
}
}
倒排索引: 倒排索引是搜索引擎的核心。搜索引擎的主要目标实在查找发生搜索条件的文档时提供快速搜索。
分片:因为Elasticsearch是一个分布式搜索引擎,所以索引通常被分割成分布在多个节点上的被称为分片的元素。分片的数量是需要创建索引的时候就需要设置的,而且设置之后不能更改(可扩充,代价高),一个结点可以有多个分片。
副本:副本是分片的副本, 保证集群数据的高可用,同时增加集群并发处理查询请求的能力。
3、MASTER
1. 介绍
master节点,负责保存和更新集群的一些元数据信息,之后同步到所有节点,所以每个节点都需要保存全量的元数据信息:配置信息, 节点信息, tempate设置, mapping, 分词器, 别名。
2. RPC在ES中的应用
ES选master是ZenDiscovery模块负责的,(ping)节点之间通过RPC来发现标记,单播模块包含一个主机列表以控制哪些节点需要ping通。(注:(1)master节点的职责主要包括集群、节点和索引的管理,不负责文档级别的管理 (2)data节点可以关闭http功能)
远程调用:
- Call ID映射:函数调用
- 序列化和反序列化:参数传递 本地参数->字节流->目标格式
- 网络传输:TCP协议
3.选取策略
如果集群中存在master,认可该master,加入集群
如果集群中不存在master,从具有master资格的节点中选id最小的节点作为master
4. 脑裂
脑裂通常会出现在集群环境中,比如ElasticSearch、Zookeeper集群,而这些集群环境有一个统一的特点,就是它们有一个大脑,比如ElasticSearch集群中有Master节点,Zookeeper集群中有Leader节点。脑裂一旦出现,会导致集群的状态出现不一致,导致数据错误甚至丢失。
ES避免脑裂的策略:过半原则,可以在ES的集群配置中添加一下配置,避免脑裂的发生
4.概念解析
-
translog:写入ES的数据首先被写入translog, 该文件持久化到磁盘,保证服务器宕机的时候数据不会丢失。
- 同步写入:每次写入请求执行后,translog在fsync到磁盘之后,才会给客户端返回成功
- 异步写入:写入请求缓存在内存中,每经过固定时间之后才会fsync到磁盘中。
-
refresh:经过固定的时间,或者手动触发之后,将内存中的数据构建索引生成segment(每次refresh的时候,都会在文件系统缓冲区中生成一个segment),写入文件系统缓冲区。
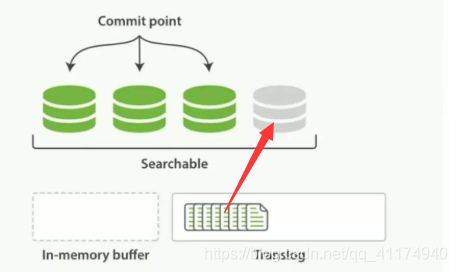
-
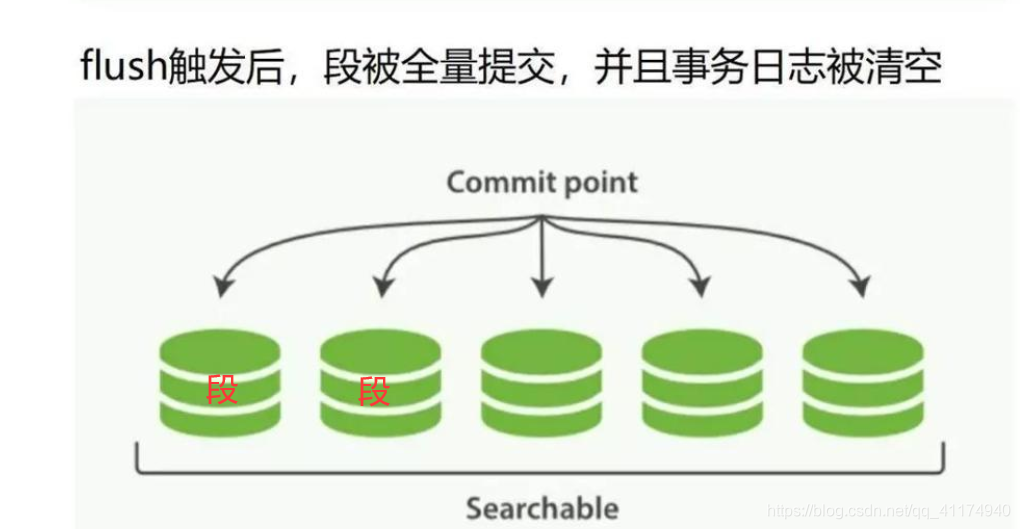
commit/flush:超过固定时间,或者translog文件过大的时候,触发flush操作:
- 内存的buffer被清空,相当于一次refresh
- 文件系统缓冲区中所有segment刷新到磁盘
- 启动或重新打开一个索引的过程中使用这个提交点来判断哪些segment隶属于当前分片
- 将一个包含所有段列表的新的提交点写入磁盘
- 删除旧的translog,开启新的translog
-
merge:refresh时间短 ——> flush时间长——>segment数量多——>
-
segment数目太多会带来较大的麻烦。 每一个segment都会消耗文件句柄、内存和cpu运行周期。
-
每个搜索请求都必须轮流检查每个segment,所以segment越多,搜索也就越慢。
-
版本控制:通过添加版本号的乐观锁机制保证高并发的时候,数据更新不会出现线程安全的问题,避免数据更新被覆盖之类的异常出现。
-
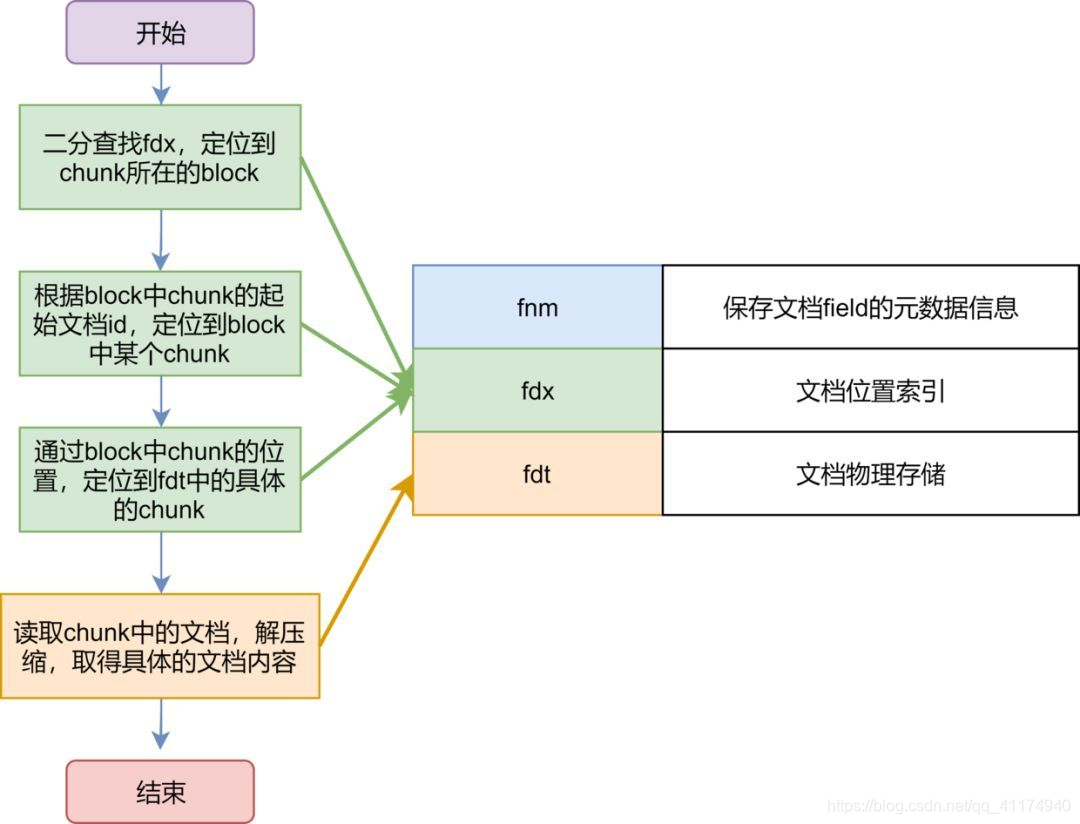
文档查询:
fdt(压缩数据) ——> chunk ——> fdx ——> block(1024个chunk) ——> fnm
 扫描二维码关注公众号,回复: 10988074 查看本文章
扫描二维码关注公众号,回复: 10988074 查看本文章
-
倒排索引:
-
小技巧
重建索引或者批量想ES写历史数据的时候,写之前先关闭副本,写入完成之后,再开启副本。
ES默认用文档id进行路由,所以通过文档id进行查询会更快,因为能直接定位到文档所在的分片,否则需要查询所有的分片。
使用ES自己生成的文档id写入更快,因为ES不需要验证一次自定义的文档id是否存在。
