match函数
match:从开始的位置进行匹配。如果开始的位置没有匹配到。就直接失败了。
text = "hello"
ret = re.match("h",text)
print(ret.group())
search函数
在字符串中找到第一个满足条件的。
text = "hello"
ret = re.search("e",text)
print(ret.group())
group 分组
在正则表达式中,可以对过滤到的字符串进行分组。分组使用圆括号的方式。
group:和group(0)是等价的,返回的是整个满足条件的字符串。
groups:返回的匹配分组的tuple。索引从1开始。
group(1):返回的是第一个子组,可以传入多个
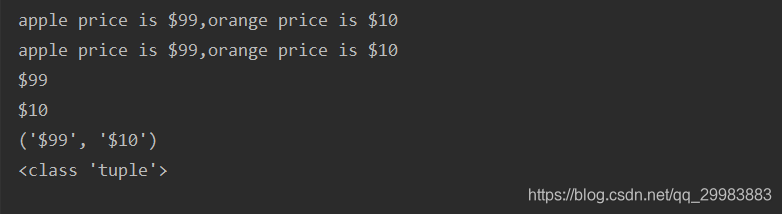
text = "apple price is $99,orange price is $10"
ret = re.search(r".*(\$\d+).*(\$\d+)",text)
print(ret.group())
print(ret.group(0))
print(ret.group(1))
print(ret.group(2))
print(ret.groups())
print(type(ret.groups()))
执行结果如下
findall函数
找出所有满足条件的,返回的是一个列表
text = "apple price is $99,orange price is $10"
ret = re.findall("\d.",text)
print(ret)
执行结果如下

sub函数
用来替换字符串。将匹配到的字符串替换为其他字符串
text = 'apple price $99 orange price $88'
ret = re.sub('\d+','100',text)
print(ret)
执行结果

split函数
使用正则表达式来分割字符串
text = "hello world ni hao"
ret = re.split('\W',text)
print(ret)
执行结果

compile函数
对于一些经常要用到的正则表达式,可以使用compile进行编译,后期再使用的时候可以直接拿过来用,执行效率会更快
text = "the number is 20.50"
r = re.compile(r"""
\d+ # 小数点前面的数字
\.? # 小数点
\d* # 小数点后面的数字
""",re.VERBOSE)
ret = re.search(r,text)
print(ret.group())
执行结果如下

