测试数据可以让你评估你的分类器或回归在独立数据集上的性能,还能帮助你避免过度拟合
在sklearn中训练/测试分离
sklearn链接:http://scikit-learn.org/stable/modules/cross_validation.html
加载数据集以适应线性SVM:
from sklearn import datasets from sklearn.svm import SVC iris = datasets.load_iris() features = iris.data labels = iris.target快速地采样一个训练集,同时支持40%的数据来测试(评估)我们的分类器:
#将数据集拆分为训练和测试集 from sklearn.model_selection import train_test_split features_train, features_test, labels_train, labels_test = cross_validation.train_test_split(iris.data,iris.target,test_size = 0.4,random_state=0) clf = SVC(kernel="linear", C=1.) clf.fit(features_train, labels_train) print clf.score(features_test, labels_test)
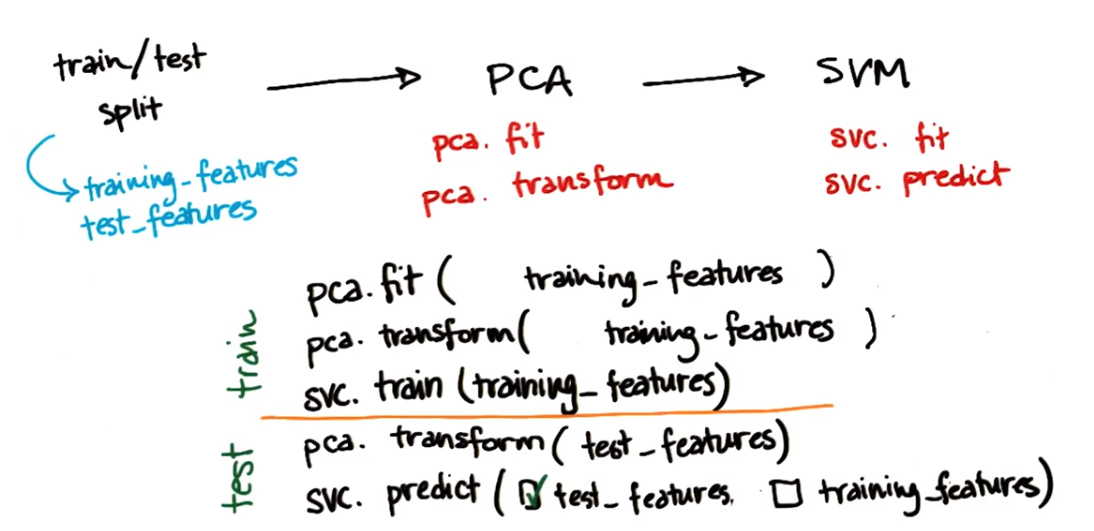
何处使用训练数据,何处使用测试数据
流程:首先将全部数据分为训练数据集和测试数据集,接下来使用PCA一种特征转换选出一些主成分,将其放入支持向量机一种分类方法svc
1. pca.fit(training_features)在训练特征中找到主成分
2. pca.transform(training_features)使用发现的fit将数据实际转化为新的主成分表示
3. svc.train(training_features) 训练支持向量机分类器
4. pca.transform(test_features)
因为没有再次调用pca.fit,因此将使用在训练数据中发现的主成分表示我的测试特征,如果此时使用测试特征重新拟合PCA,是不正确的
5. svc.predict(test_features)
支持向量机对测试数据集进行预测
练习:K折交叉验证
两个集合最大化——尽可能多的训练集数据点以获得最佳学习效果,尽可能多的测试集数据项来获得最佳验证,此时为了寻找折中点涉及到交叉验证
基本要点:将训练数据评分到相同大小的k个容器内,例如200个训练数据点,10个容器,则每个容器20个训练数据点,在k折交叉验证中,你将运行k此单独的学习试验,在每次实验中,你将从这k个子集中挑选一个作为验证集,剩下k-1个容器放在一起作为训练集,然后训练你的机器学习算法,再再验证集上验证性能,交叉验证中的要点是这个操作会运行k次,然后将k次试验的测试结果取平均值
>>> import numpy as np
>>> from sklearn.model_selection import KFold
>>> X = ["a", "b", "c", "d"]
>>> kf = KFold(n_splits=2)
>>> for train, test in kf.split(X):
... print("%s %s" % (train, test))
[2 3] [0 1]
[0 1] [2 3]
train=训练集中使用的所有数据点的索引值的集合,test=测试集使用的所有索引值
sklearn中的K折CV
#!/usr/bin/python
import sys
from time import time
from sklearn.cross_validation import KFold
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.feature_selection import SelectPercentile,f_classif
from sklearn.naive_bayes import GaussianNB
from sklearn.metrics import accuracy_score
sys.path.append("../tools/")
from email_preprocess_kfold import preprocess
clf = GaussianNB()
t0 = time()
authors,word_data = preprocess()
kf = KFold(len(authors),2)
for train_indices,test_indices in kf:
#make training and testing datasets
features_train = [word_data[ii] for ii in train_indices]
features_test = [word_data[ii] for ii in test_indices]
author_train = [authors[ii] for ii in train_indices]
author_test = [authors[ii] for ii in test_indices]
#TFIDF and feature selection
vectorizer = TfidfVectorizer(sublinear_tf=True,max_df=0.5,stop_words='english')
features_train_transformed = vectorizer.fit_transform(features_train)
features_test_transformed = vectorizer.transform(features_test)
selector = SelectPercentile(f_classif,percentile=10)
selector.fit(features_train_transformed,author_train)
features_train_transformed = selector.transform(features_train_transformed).toarray()
features_test_transformed = selector.transform(features_test_transformed).toarray()
clf.fit(features_train_transformed, author_train)
print "training time:", round(time()-t0, 3), "s"
t0 = time()
pred = clf.predict(features_train_transformed)
print "predicting time:", round(time()-t0, 3), "s"
acc = accuracy_score(pred, author_test)
print 'accuracy:',round(acc,3)
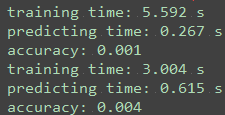
从中可以看出精确度出现了严重问题,为了查找问题,输入几个print语句
for train_indices,test_indices in kf:
#make training and testing datasets
-snip-
author_test = [authors[ii] for ii in test_indices]
print train_indices
print authors_train
print authors_test
-snip-
print train_indices
查看训练数据集中的所有事件指数是否存在 所有某一特定的事件类型最后都属于训练数据集,而所有另一特定的事件类型最后都属于测试数据集 这种情况,如果存在这种情况,针对一种类型事件的训练不会对另一事件进行分类有帮助
print authors_train
打印出训练数据集中所有事件的标签
print authors_test
打印出测试数据集中的作者,来查看训练数据集和测试数据集中的事件是否有某些重要的区别
事件顺序并没有打乱,只是从中间切割成两部分,导致用属于所有某一特定的事件类型做训练集训练,去分类属于另一特定事件类型的测试集


sklearn KFold的工作原理将数据划分为大小相同的K部分,不会对事件进行任何类型的乱排序。因此如果你的数据里的表现方式是,尤其是类别上存在某些模式,然后这些模式会反映在大量的特定的标签中,最终会体现在验证的特定折上
通过一些参数的调整即可获得最佳性能的,使用某种猜测然后检验的方法调整这些参数,可以使用交叉验证自动执行很多这类测试,并选择可以实现最佳性能的参数调整方式。如下
sklearn中的GridSearchCV
GridSearchCV 用于系统地遍历多种参数组合,通过交叉验证确定最佳效果参数。它的好处是,只需增加几行代码,就能遍历多种组合。
from sklearn.model_selection import GridSearchCV
from sklearn.svm import SVC
parameters = {'kernel':('linear', 'rbf'), 'C':[1, 10]}
svr = svm.SVC()
clf = grid_search.GridSearchCV(svr, parameters)
clf.fit(iris.data, iris.target)
逐行进行说明。
parameters = {'kernel':('linear', 'rbf'), 'C':[1, 10]}
参数字典以及他们可取的值。在这种情况下,他们在尝试找到 kernel(可能的选择为 'linear' 和 'rbf' )和 C(可能的选择为1和10)的最佳组合。
这时,会自动生成一个不同(kernel、C)参数值组成的“网格”:
| ('rbf', 1) | ('rbf', 10) |
|---|---|
| ('linear', 1) | ('linear', 10) |
各组合均用于训练 SVM,并使用交叉验证对表现进行评估。
svr = svm.SVC()
与创建分类器有点类似,但是请注意,“clf” 到下一行才会生成—这儿仅仅是在说采用哪种算法。另一种思考方法是,“分类器”在这种情况下不仅仅是一个算法,而是算法加参数值。请注意,这里不需对 kernel 或 C 做各种尝试;下一行才处理这个问题。
clf = grid_search.GridSearchCV(svr, parameters)
分类器创建。 传达算法 (svr) 和参数 (parameters) 字典来尝试,它生成一个网格的参数组合进行尝试。
clf.fit(iris.data, iris.target)
拟合函数现在尝试了所有的参数组合,并返回一个合适的分类器,自动调整至最佳参数组合。现在您便可通过 clf.best_params_ 来获得参数值。
练习:请参考特征脸方法代码。使用 GridSearchCV 调整了 SVM 的哪些参数?C、gamma
链接:http://scikit-learn.org/stable/auto_examples/applications/plot_face_recognition.html
param_grid = {'C': [1e3, 5e3, 1e4, 5e4, 1e5],
'gamma': [0.0001, 0.0005, 0.001, 0.005, 0.01, 0.1], }
迷你项目:
第一部分:
你将先开始构建想象得到的最简单(未经过验证的)POI 识别符。 本节课的初始代码 (validation/validate_poi.py) 相当直白——它的作用就是读入数据,并将数据格式化为标签和特征的列表。 创建决策树分类器(仅使用默认参数),在所有数据(你将在下一部分中修复这个问题!)上训练它,并打印出准确率。 这是一颗过拟合树。
0.989473684211
from sklearn.tree import DecisionTreeClassifier clf = DecisionTreeClassifier() clf.fit(features,labels) print clf.score(features,labels)
第二部分
现在,你将添加训练和测试,以便获得一个可靠的准确率数字。 使用 sklearn.cross_validation 中的 train_test_split 验证; 将 30% 的数据用于测试,并设置 random_state 参数为 42(random_state 控制哪些点进入训练集,哪些点用于测试;将其设置为 42 意味着我们确切地知道哪些事件在哪个集中; 并且可以检查你得到的结果)。更新后的准确率是多少?
0.724137931034
#!/usr/bin/python
import pickle
import sys
sys.path.append("../tools/")
from feature_format import featureFormat, targetFeatureSplit
data_dict = pickle.load(open("../final_project/final_project_dataset.pkl", "r") )
### first element is our labels, any added elements are predictor
### features. Keep this the same for the mini-project, but you'll
### have a different feature list when you do the final project.
features_list = ["poi", "salary"]
data = featureFormat(data_dict, features_list)
labels, features = targetFeatureSplit(data)
from sklearn.model_selection import train_test_split
features_train, features_test, labels_train, labels_test = train_test_split(features,labels,test_size=0.3,random_state=42)
### it's all yours from here forward!
from sklearn.tree import DecisionTreeClassifier
clf = DecisionTreeClassifier()
clf.fit(features_train,labels_train)
result = clf.predict(features_test)
from sklearn.metrics import accuracy_score
print accuracy_score(labels_test,result)
#print clf.score(features_test,labels_test)