前言
今天我们学习网络的损失部分,众所周知损失是网络参数调节的关键,损失函数的好坏是一个网络的关键,让我们先了解一下CTPN的损失组成:
CTPN 的 loss 分为三部分:
Ls:预测每个 anchor 是否包含文本区域的classification loss;
Lv:文本区域中每个 anchor 的中心y坐标cy 与高度h 的regression loss;
Lo:文本区域两侧 anchor 的中心x坐标cx 的regression loss。
目标函数是分类损失和回归损失的和,分类损失采用交叉熵,回归损失采用Smooth L1。
Ls_cls = nn.CrossEntropyLoss()
Lv_reg = nn.SmoothL1Loss()
Lo_reg = nn.SmoothL1Loss()
总的损失函数如下:
Ls 为传统的 softmax_cross_entropy_loss,其中,i 表示预测的所有pn_anchor中的第 i 个, ,Ns 为归一化参数,表示 pn_anchor 的数量。
Lv 使用的 smooth_L1_loss,v为判断有文本的pn_anchor,其中,j 表示 IoU>0.5 的所有 pn_anchor 中的第 j 个,Nv 为归一化参数,表示和 groudtruth 的 vertical IOU>0.5 的 pn_anchor 的数量。λ1 为多任务的平衡参数,λ1=1.0。
Lo 只针对位于在文本区域的左边界和右边界的pn_anchor,可以理解为文本框边缘优化。文本框检测中边缘部分的预测并不准确,CTPN就用这个偏移量来精修边缘。
Faster R-CNN 和 SSD 中使用 Smooth L1 Loss 的原因
相比于L1损失函数,在训练后期梯度值更小,可以收敛得更快。
相比于L2损失函数,对离群点、异常值不敏感,梯度变化相对更小,避免梯度爆炸
分别对应三个 输出结果:
分类预测(1, 2k, h/16, w/16)
垂直坐标预测(anchor的h和cy)(1, 2k, h/16, w/16)
水平坐标预测(anchor的x)(1, 1k, h/16, w/16)
下面然你给我们看一下代码:
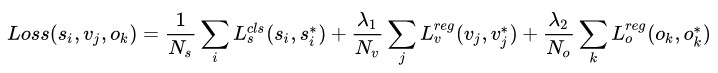
def loss(bbox_pred, cls_pred, bbox, im_info):
rpn_data = anchor_target_layer(cls_pred, bbox, im_info, "anchor_target_layer")
# classification loss
# transpose: (1, H, W, A x d) -> (1, H, WxA, d)
cls_pred_shape = tf.shape(cls_pred)
cls_pred_reshape = tf.reshape(cls_pred, [cls_pred_shape[0], cls_pred_shape[1], -1, 2])
rpn_cls_score = tf.reshape(cls_pred_reshape, [-1, 2])
rpn_label = tf.reshape(rpn_data[0], [-1])
# ignore_label(-1)
fg_keep = tf.equal(rpn_label, 1)
rpn_keep = tf.where(tf.not_equal(rpn_label, -1))
rpn_cls_score = tf.gather(rpn_cls_score, rpn_keep)
rpn_label = tf.gather(rpn_label, rpn_keep)
rpn_cross_entropy_n = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=rpn_label, logits=rpn_cls_score)
# box loss
rpn_bbox_pred = bbox_pred
rpn_bbox_targets = rpn_data[1]
rpn_bbox_inside_weights = rpn_data[2]
rpn_bbox_outside_weights = rpn_data[3]
rpn_bbox_pred = tf.gather(tf.reshape(rpn_bbox_pred, [-1, 4]), rpn_keep) # shape (N, 4)
rpn_bbox_targets = tf.gather(tf.reshape(rpn_bbox_targets, [-1, 4]), rpn_keep)
rpn_bbox_inside_weights = tf.gather(tf.reshape(rpn_bbox_inside_weights, [-1, 4]), rpn_keep)
rpn_bbox_outside_weights = tf.gather(tf.reshape(rpn_bbox_outside_weights, [-1, 4]), rpn_keep)
rpn_loss_box_n = tf.reduce_sum(rpn_bbox_outside_weights * smooth_l1_dist(
rpn_bbox_inside_weights * (rpn_bbox_pred - rpn_bbox_targets)), reduction_indices=[1])
rpn_loss_box = tf.reduce_sum(rpn_loss_box_n) / (tf.reduce_sum(tf.cast(fg_keep, tf.float32)) + 1)
rpn_cross_entropy = tf.reduce_mean(rpn_cross_entropy_n)
model_loss = rpn_cross_entropy + rpn_loss_box
regularization_losses = tf.get_collection(tf.GraphKeys.REGULARIZATION_LOSSES)
total_loss = tf.add_n(regularization_losses) + model_loss
tf.summary.scalar('model_loss', model_loss)
tf.summary.scalar('total_loss', total_loss)
tf.summary.scalar('rpn_cross_entropy', rpn_cross_entropy)
tf.summary.scalar('rpn_loss_box', rpn_loss_box)
return total_loss, model_loss, rpn_cross_entropy, rpn_loss_box
anchor_target_layer()
rpn_labels 产生anchor的标签
rpn_bbox_targets 预测的矩形框
rpn_bbox_inside_weights 内部权重,前景为1,背景为0,不关心也是0
rpn_bbox_outside_weights 外部权重,前景是1,背景是0,用于平衡分类和回归损失的比重
这里函数是用来获取rpn相关数据,函数的编写我们在后面单独一篇来谈。
rpn_data = anchor_target_layer(cls_pred, bbox, im_info, "anchor_target_layer")
# classification loss
# transpose: (1, H, W, A x d) -> (1, H, WxA, d)
cls_pred_shape = tf.shape(cls_pred)
cls_pred_reshape = tf.reshape(cls_pred, [cls_pred_shape[0], cls_pred_shape[1], -1, 2])
rpn_cls_score = tf.reshape(cls_pred_reshape, [-1, 2])
rpn_label = tf.reshape(rpn_data[0], [-1])
# ignore_label(-1)
fg_keep = tf.equal(rpn_label, 1)
rpn_keep = tf.where(tf.not_equal(rpn_label, -1))
rpn_cls_score = tf.gather(rpn_cls_score, rpn_keep)
rpn_label = tf.gather(rpn_label, rpn_keep)
rpn_cross_entropy_n = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=rpn_label, logits=rpn_cls_score)
tf.shape帮助我们产生一个和预测框分类概率值同样的shape,然后将shape重置最后生成最终的分类概率,然后取出rpn数据的第一位作为rpn的标签,然后fg_keep = tf.equal(rpn_label, 1) ,rpn_keep =tf.where(tf.not_equal(rpn_label, -1)) 这里是取出rpn中标签为1的作为前景,部位-1的作为正负样本。获取正负样本的标签,最后利用正负样本的标签和分数计算出交叉熵损失作为分类损失。
rpn_bbox_pred = bbox_pred
rpn_bbox_targets = rpn_data[1]
rpn_bbox_inside_weights = rpn_data[2]
rpn_bbox_outside_weights = rpn_data[3]
rpn_bbox_pred = tf.gather(tf.reshape(rpn_bbox_pred, [-1, 4]), rpn_keep) # shape (N, 4)
rpn_bbox_targets = tf.gather(tf.reshape(rpn_bbox_targets, [-1, 4]), rpn_keep)
rpn_bbox_inside_weights = tf.gather(tf.reshape(rpn_bbox_inside_weights, [-1, 4]), rpn_keep)
rpn_bbox_outside_weights = tf.gather(tf.reshape(rpn_bbox_outside_weights, [-1, 4]), rpn_keep)
rpn_loss_box_n = tf.reduce_sum(rpn_bbox_outside_weights * smooth_l1_dist(
rpn_bbox_inside_weights * (rpn_bbox_pred - rpn_bbox_targets)), reduction_indices=[1])
rpn_loss_box = tf.reduce_sum(rpn_loss_box_n) / (tf.reduce_sum(tf.cast(fg_keep, tf.float32)) + 1)
rpn_cross_entropy = tf.reduce_mean(rpn_cross_entropy_n)
model_loss = rpn_cross_entropy + rpn_loss_box
regularization_losses = tf.get_collection(tf.GraphKeys.REGULARIZATION_LOSSES)
total_loss = tf.add_n(regularization_losses) + model_loss
tf.summary.scalar('model_loss', model_loss)
tf.summary.scalar('total_loss', total_loss)
tf.summary.scalar('rpn_cross_entropy', rpn_cross_entropy)
tf.summary.scalar('rpn_loss_box', rpn_loss_box)
首先获取box的标记信息gt,其中相同的是正样本为1,负样本为0,然后获取回归损失的两个参数,根据刚才的标签获得相应的文本框信息和gt信息,根据标签修改参数,然后计算正样本的smooth_l1损失,分别求分类损失和回归损失的平均值,求出模型损失,注意一下,这里没有计算第三种损失,也就是x轴上的偏移。
regularization_losses = tf.get_collection(tf.GraphKeys.REGULARIZATION_LOSSES)
这里可能有点费解但是很多算法可能都有,这是正则化方法用来防止过拟合。最后加成总损失返回。
最后
这部分就是损失函数了,还有一点没讲,后面会讲到这里推荐一篇前辈的文章帮助理解https://zhuanlan.zhihu.com/p/77883736在此向各位前辈致以诚挚敬意。
