本章我们使用一个高维线性回归的例子来做解决过拟合的问题。
相关公式:
,
服从均值为0标准差为0.01的正态分布。
PS:为了突出过拟合的现象,本章实验中所使用的数据一定是比较少的。例如 =20,同时把维度升高,即 =200。
L2范数正则化
线性模型就是将输入和模型相乘再加上偏移量。这里我们引入L2正则化方法,不仅仅在训练时最小化损失函数,主要最小化的是下面的方程:
直观上,L2范数正则化试图惩罚较大绝对值的参数,当
=0时,则未使用正则化,当模型测试时,也不要使用正则化。
下面进行代码的实现:
1、数据生成
true_w=nd.ones((num_inputs,1))*0.01 # 真实的w
true_b=0.05 #真实的b
# 生成训练和测试数据集
X=nd.random.normal(shape=(num_train+num_test,num_inputs))
y=nd.dot(X,true_w)
y+=0.01+nd.random.normal(shape=y.shape) #根据公式生成的数据集
X_train,X_test=X[:num_train,:],X[num_train:,:]
y_train,y_test=y[:num_train,:],y[num_train:,:]
2、数据读取
batch_size=10
def data_iter(num_example):
idx=list(range(num_example)) # 产生索引
random.shuffle(idx) # 打乱数据
for i in range(0,num_example,batch_size):
j=nd.array(idx[i:min(i+batch_size,num_example)])
yield nd.take(X_train,j),nd.take(y_train,j) # nd.take(x,j),从数据中取出相关索引的数据,并返回
3、参数初始化
def get_params(): #模型参数初始化
w=nd.random_normal(shape=(num_inputs,1))*0.1
b=nd.zeros(1,)
params=[w,b]
# 之后会不断训练更新w和b的值,所以我们要创建梯度来进行求导
for param in params: # 对w和b开辟一个临时空间
param.attach_grad()
return (w,b)
4、L2正则化
# 定义模型
def net(X,w,b):
return nd.dot(X,w)+b
# 损失函数定义
def loss_function(y_true,y_pre): # 常使用平方误差来衡量预测值和真实值之间的差距
return (y_pre-y_true.reshape(y_pre.shape))**2 # 把真实值与预测值的维度变成一样,否则会广播
# 优化
def SGD(params,lr):
for pa in params:
pa[:]=pa-lr*pa.grad # 参数沿着梯度的反方向走特定距离
def test(params,X,y):
return loss_function(net(X,*params),y).mean().asscalar()
5、训练
def train(lambd):
epochs = 5
lr = 0.001
train_loss=[]
test_loss = []
params=get_params()
for e in range(0, epochs):
for data, label in data_iter(num_train): # 读取第一个batch size看看
with ag.record():
output = net(data,*params)
(w,b)=params
loss = loss_function(label, output)+lambd*((w**2).sum()+b**2)
loss.backward() # 对loss求导
SGD(params, lr) # 沿着导数的反方向走是可以把loss变低的
train_loss.append(test(params,X_train,y_train))
test_loss.append(test(params,X_test,y_test))
plt.plot(train_loss)
plt.plot(test_loss)
plt.legend(["train","test"])
plt.show()
print('learned w[:10]:',params[0][:10],'learned b:',params[1])
print(train_loss)
print(test_loss)
当
=0时,模型的训练过程如下所示:
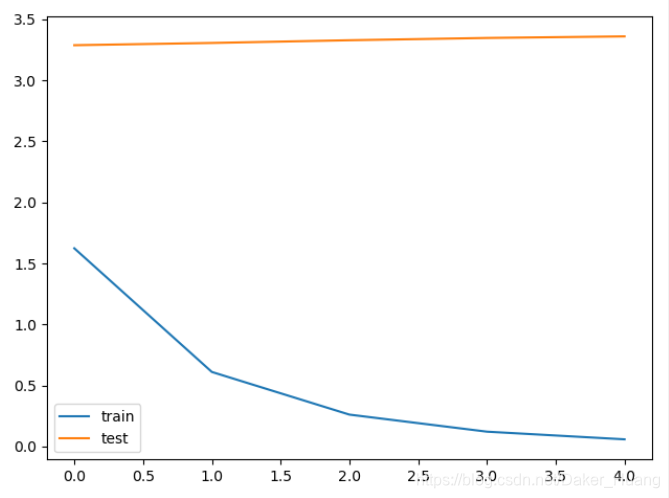
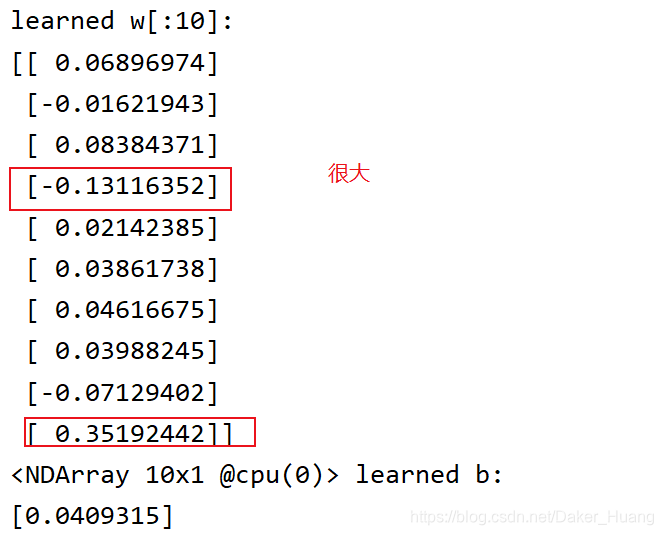
可以看到,train和test的曲线相差很大,模型严重过拟合。以下是更新的w和b:
使用惩罚项时:
train(3) # 不使用惩罚项
结果:
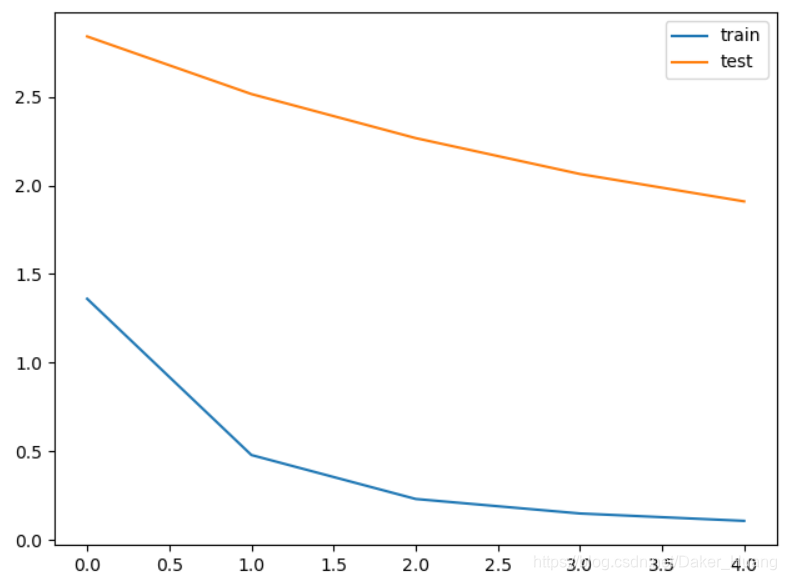
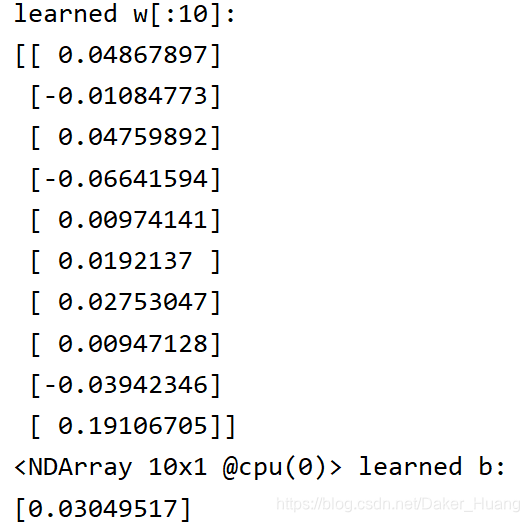
附上所有源码:
扫描二维码关注公众号,回复:
11016789 查看本文章

import mxnet.ndarray as nd
import mxnet.autograd as ag
import mxnet.gluon as gn
import matplotlib.pyplot as plt
import random
num_train=20
num_test=100
num_inputs=200
'''生成数据集'''
true_w=nd.ones((num_inputs,1))*0.01 # 真实的w
true_b=0.05 #真实的b
# 生成训练和测试数据集
X=nd.random.normal(shape=(num_train+num_test,num_inputs))
y=nd.dot(X,true_w)
y+=0.01+nd.random.normal(shape=y.shape) #根据公式生成的数据集
X_train,X_test=X[:num_train,:],X[num_train:,:]
y_train,y_test=y[:num_train,:],y[num_train:,:]
'''---数据读取---'''
# 定义一个函数让它每批次读取数据(batch_size)
batch_size=10
def data_iter(num_example):
idx=list(range(num_example)) # 产生索引
random.shuffle(idx) # 打乱数据
for i in range(0,num_example,batch_size):
j=nd.array(idx[i:min(i+batch_size,num_example)])
yield nd.take(X_train,j),nd.take(y_train,j) # nd.take(x,j),从数据中取出相关索引的数据,并返回
def get_params(): #模型参数初始化
w=nd.random_normal(shape=(num_inputs,1))*0.1
b=nd.zeros(1,)
params=[w,b]
# 之后会不断训练更新w和b的值,所以我们要创建梯度来进行求导
for param in params: # 对w和b开辟一个临时空间
param.attach_grad()
return (w,b)
'''--------L2范数正则化----------'''
# 定义模型
def net(X,w,b):
return nd.dot(X,w)+b
# 损失函数定义
def loss_function(y_true,y_pre): # 常使用平方误差来衡量预测值和真实值之间的差距
return (y_pre-y_true.reshape(y_pre.shape))**2 # 把真实值与预测值的维度变成一样,否则会广播
# 优化
def SGD(params,lr):
for pa in params:
pa[:]=pa-lr*pa.grad # 参数沿着梯度的反方向走特定距离
def test(params,X,y):
return loss_function(net(X,*params),y).mean().asscalar()
def train(lambd):
epochs = 5
lr = 0.001
train_loss=[]
test_loss = []
params=get_params()
for e in range(0, epochs):
for data, label in data_iter(num_train): # 读取第一个batch size看看
with ag.record():
output = net(data,*params)
(w,b)=params
loss = loss_function(label, output)+lambd*((w**2).sum()+b**2)
loss.backward() # 对loss求导
SGD(params, lr) # 沿着导数的反方向走是可以把loss变低的
train_loss.append(test(params,X_train,y_train))
test_loss.append(test(params,X_test,y_test))
plt.plot(train_loss)
plt.plot(test_loss)
plt.legend(["train","test"])
plt.show()
print('learned w[:10]:',params[0][:10],'learned b:',params[1])
print(train_loss)
print(test_loss)
# train(0) # 不使用惩罚项
train(3) # 使用惩罚项
