一、主题式网络爬虫设计方案(15分)
1.主题式网络爬虫名称 爬取新浪网热搜
2.主题式网络爬虫爬取的内容与数据特征分析 爬取新浪网热搜排行榜、热度
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
本案例使用requests库获取网页数据,使用BeautifulSoup库解析页面内容,再使用pandas库把爬取的数据输出,并对数据可视化,最后进行小结;技术难点:爬取有用的数据,将有碍分析的数据剔除,回归直线。
二、主题页面的结构特征分析(15分)
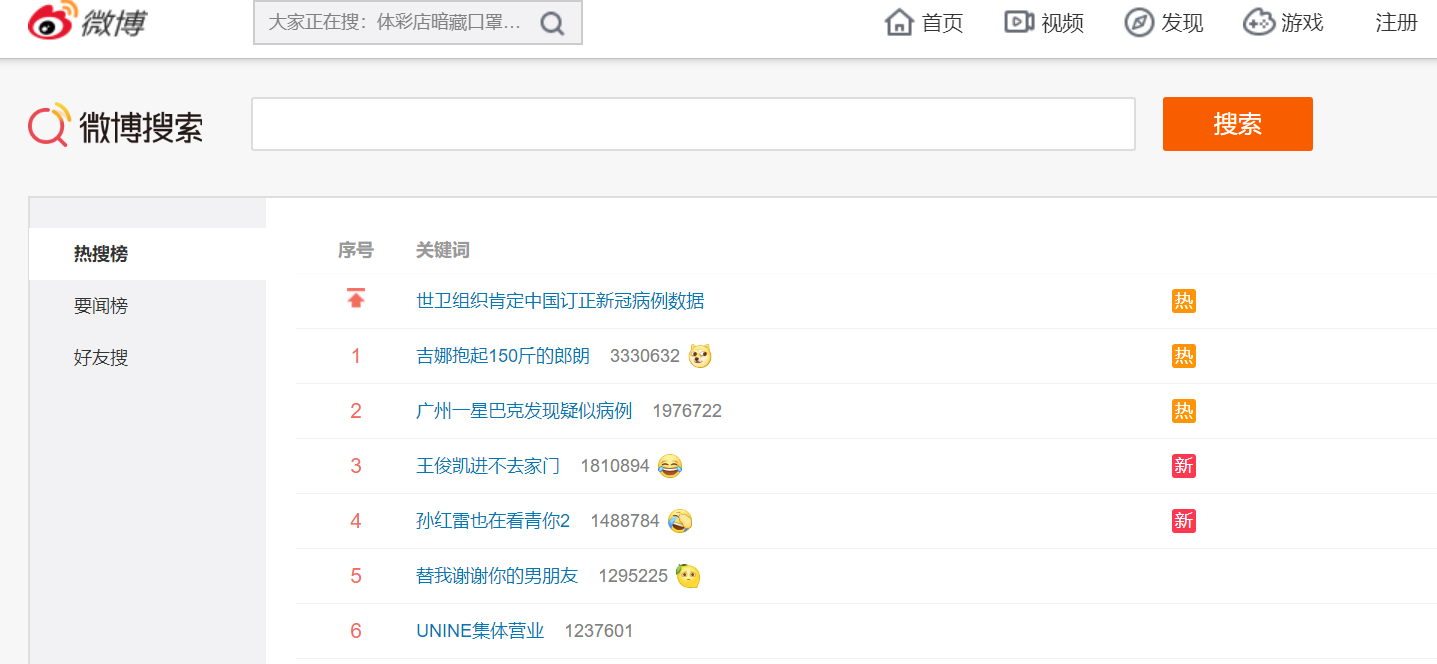
1.主题页面的结构特征
页面内容如下,本方案要爬取的是表格中的内容。
2.Htmls页面解析
通过F12,对页面进行检查,查看我们所需要爬取内容的相关代码。
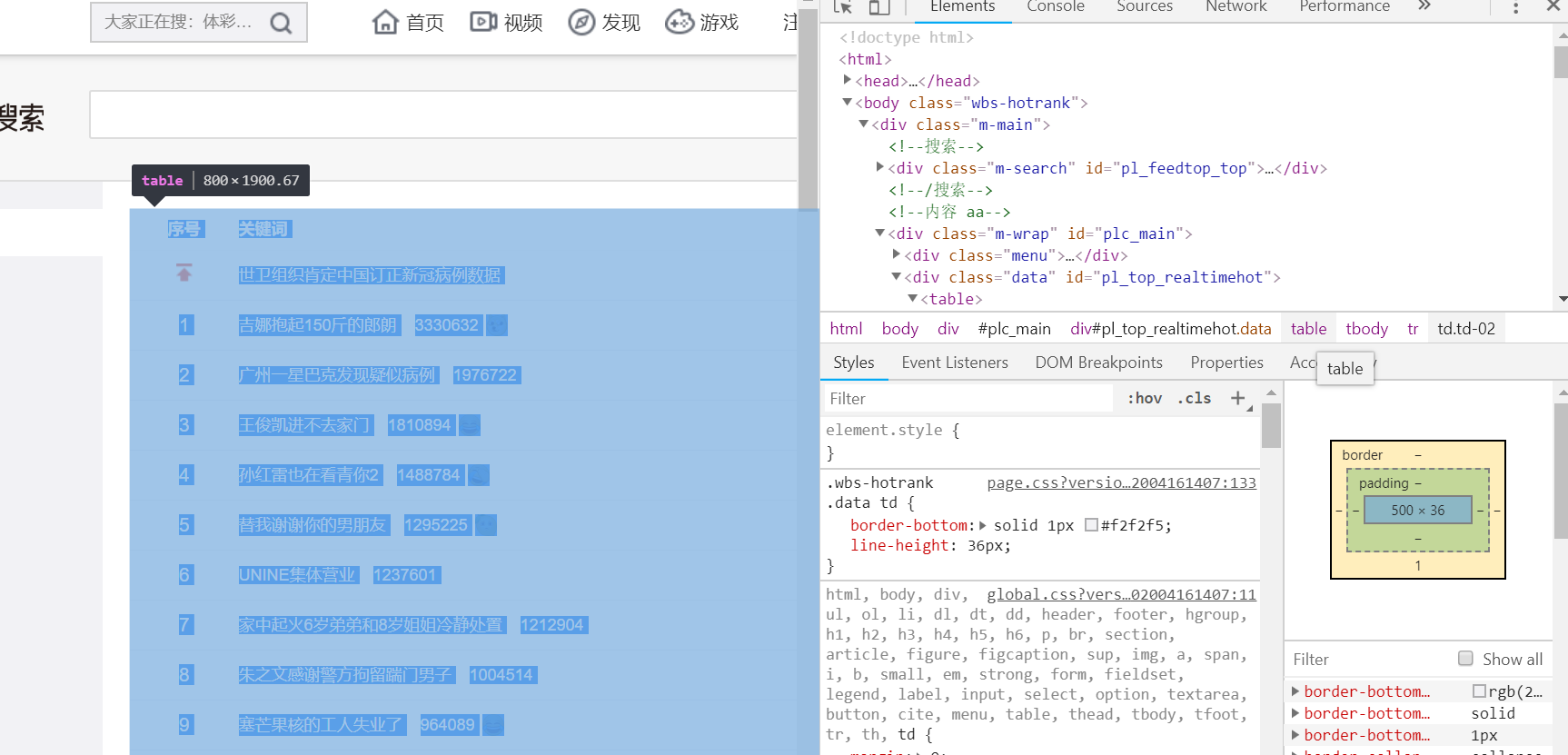

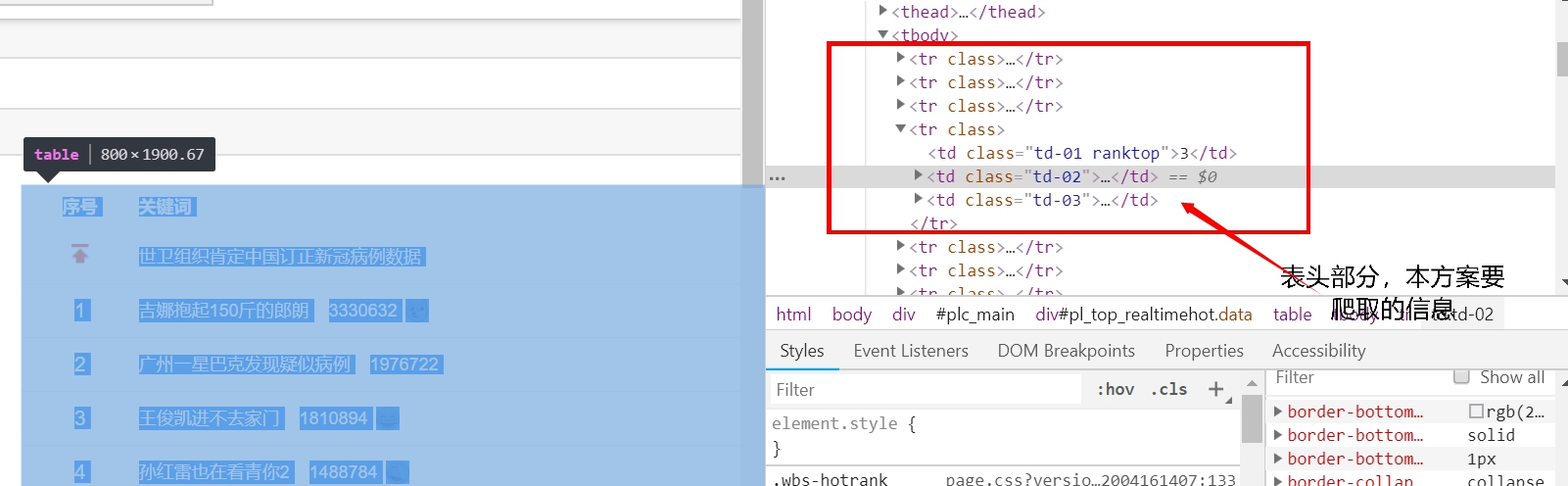
3.节点(标签)查找方法与遍历方法
三、网络爬虫程序设计(60分)
1.数据爬取与采集(20)
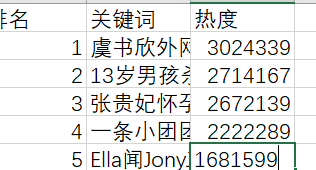
爬取的数据

提取前五存入Excel
2.对数据进行清洗和处理(10)

结果:

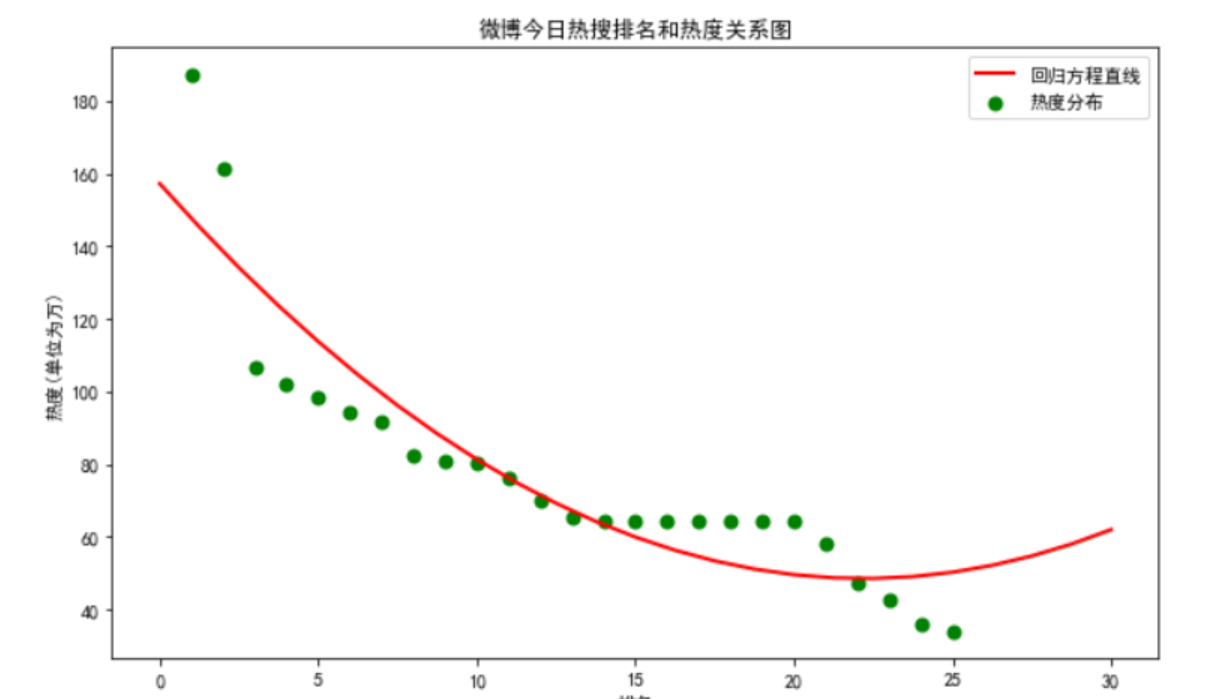
3.数据分析与可视化

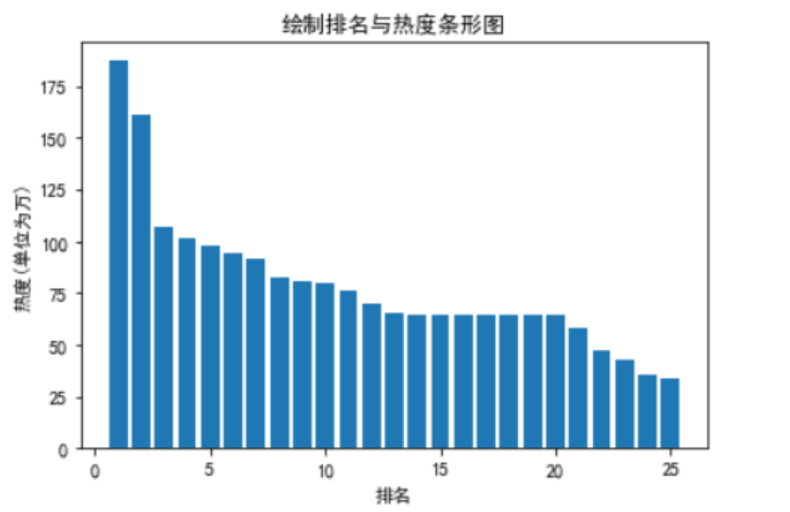

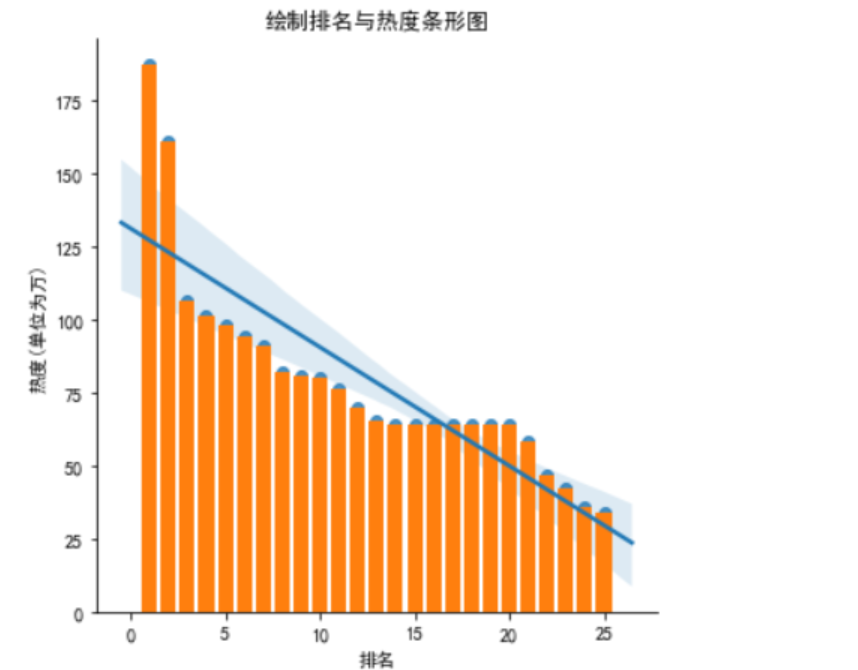

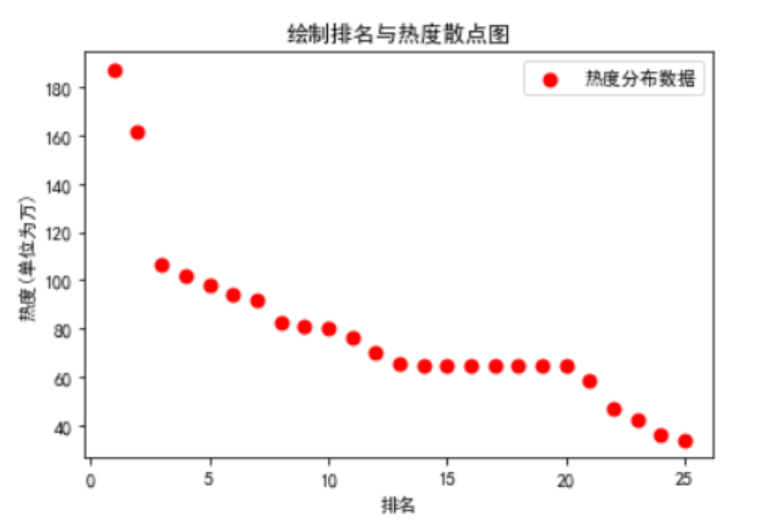
一元二次回归直线
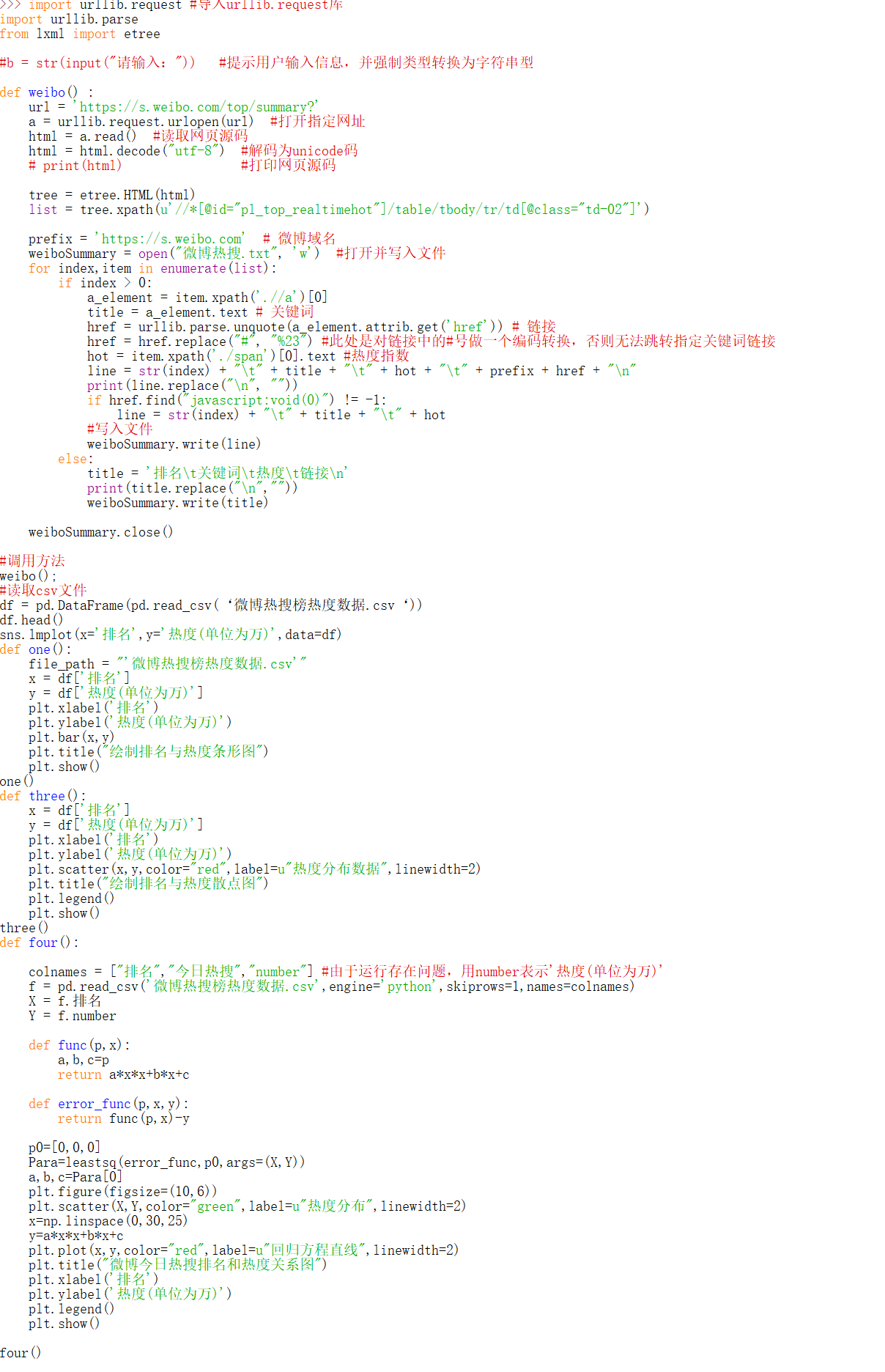
完整代码
四、结论(10分)
1.经过对主题数据的分析与可视化, 可以得到哪些结论?
经过对数据的分析,可以观察到热搜的排名及热度
2.对本次程序设计任务完成的情况做一个简单的小结。
对于细节知识的缺乏,实践存在很多问题,可视化通过查阅才得出,要学的东西还很多,希望自己保持求学的态度,继续前行