
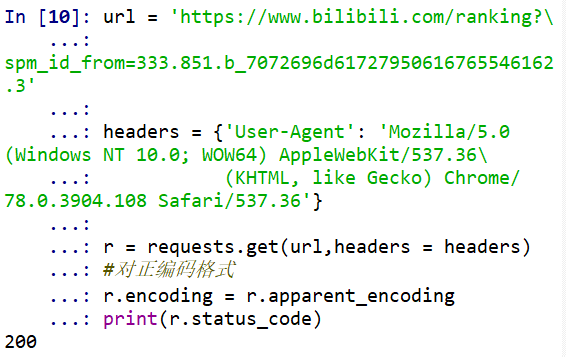
在网页目标点击鼠标右键进行元素审查

#获取网页链接
url = 'https://www.bilibili.com/ranking?spm_id_from=333.851.b_7072696d61727950616765546162.3'
#获取头部信息
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36(KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'}
r = requests.get(url,headers = headers)
#对正编码格式
r.encoding = r.apparent_encoding
print(r.status_code)
#然后使用BeautifulSoup对其进行解析
soup = BeautifulSoup(html,'lxml')
#定义列表储存各类信息
a = [] #储存标题
b = [] #储存人气
c = [] #储存排名
d = [] #储存播放量
#爬取片面
for name in soup.select('a[class="title"]')[:20]:
a.append(name.get_text().strip())
#爬取人气
for div in soup.select('div[class="pts"]')[:20]:
b.append(div.get_text().strip())
#爬取排名
for li in soup.select('div[class="num"]')[:20]:
lis = li.text
c.append(lis)
#爬取播放量
for i in soup.select('div[class="detail"]')[:20]:
for k in i.select('span[class="data-box"]')[:1]:
d.append(k.text)
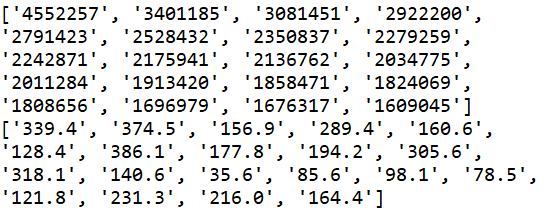
print(a,b,c,d)

#从图中看出人气值和播放量带有中文
#可用re正则表达式处理
fine = re.compile('(\d+)综合得分')
b = re.findall(fine,str(b))
#print(b)
fins = re.compile('(\d+\.\d+)万')
d = re.findall(fins,str(d))
#print(d)
#然后用pandas对数据进行处理
index_list=['人气','播放量','片名']
columns_list = c
df = pd.DataFrame([b,d,a],index = index_list ,columns = columns_list)
df = df.T #使用T进行转置
print(df)

#数据永久化
df.to_excel('bilibili.xlsx')

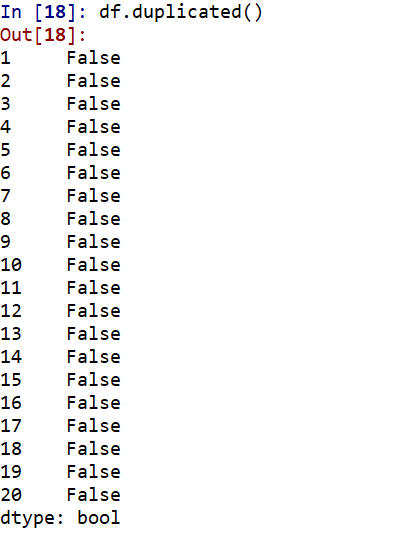
#查找重复值
df.duplicated()
#看是否有重复值可用 df = df.drop_duplicates() 删除
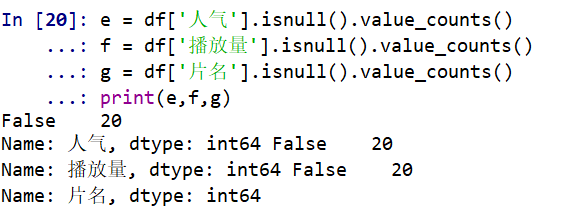
#空值与缺失值处理
#对数据进行可视化
plt.rcParams['font.sans-serif'] = ['SimHei'] #始中文显示
plt.bar(a,b)
plt.show()
plt.scatter(a,b)
plt.plot(a,b)
plt.show()

完整代码
import requests
from bs4 import BeautifulSoup
import re
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
#from pylab import *
url = 'https://www.bilibili.com/ranking?\
spm_id_from=333.851.b_7072696d61727950616765546162.3'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36\
(KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'}
r = requests.get(url,headers = headers)
#对正编码格式
r.encoding = r.apparent_encoding
print(r.status_code)
html = r.text
soup = BeautifulSoup(html,'lxml')
#print(soup.prettify())
a = [] #储存标题
b = [] #储存人气
c = [] #储存排名
d = [] #储存播放量
#爬取片面
for name in soup.select('a[class="title"]')[:20]:
a.append(name.get_text().strip())
#爬取人气
for div in soup.select('div[class="pts"]')[:20]:
b.append(div.get_text().strip())
#爬取排名
for li in soup.select('div[class="num"]')[:20]:
lis = li.text
c.append(lis)
#爬取播放量
for i in soup.select('div[class="detail"]')[:20]:
for k in i.select('span[class="data-box"]')[:1]:
d.append(k.text)
#print(a,b,c,d)
#print(b)
#正则表达式爬取的人气值去中文
fine = re.compile('(\d+)综合得分')
b = re.findall(fine,str(b))
#print(b)
fins = re.compile('(\d+\.\d+)万')
d = re.findall(fins,str(d))
#print(d)
index_list=['人气','播放量','片名']
columns_list = c
df = pd.DataFrame([b,d,a],index = index_list ,columns = columns_list)
df = df.T
#print(df)
#数据永久化
#df.to_excel('bilibili.xlsx')
#查看重复值
df.duplicated()
#删除重复值
df = df.drop_duplicates()
#空值与缺失值处理
e = df['人气'].isnull().value_counts()
f = df['播放量'].isnull().value_counts()
g = df['片名'].isnull().value_counts()
#print(e,f,g)
plt.rcParams['font.sans-serif'] = ['SimHei'] #始中文显示
plt.bar(a,b)
plt.show()
plt.scatter(a,b)
plt.plot(a,b)
plt.show()
由于数据太大显示目视的差别
总结
爬取数据时要要确保数据可行