- 正则表达式在各种语言中基本都通用
- 正则表达式就是找到我们需要数据的一种规则
python使用正则表达式

正则表达式
1.匹配单个字符
| 字符 |
功能 |
| . |
匹配任意1个字符(除了\n) |
| [ ] |
匹配[ ]中列举的字符 |
| \d |
匹配数字,即0-9 |
| \D |
匹配非数字,即不是数字 |
| \s |
匹配空白,即 空格,tab键 |
| \S |
匹配非空白 |
| \w |
匹配单词字符,即a-z、A-Z、0-9、_/中文 |
| \W |
匹配非单词字符 |

2.匹配多个字符
- 匹配多个字符,匹配的是次数,需要和其它字符或匹配结合使用
| 字符 |
功能 |
| * |
匹配前一个字符出现0次或者无限次,即可有可无 |
| + |
匹配前一个字符出现1次或者无限次,即至少有1次 |
| ? |
匹配前一个字符出现1次或者0次,即要么有1次,要么没有 |
| {m} |
匹配前一个字符至少出现m次 |
| {m,n} |
匹配前一个字符出现从m到n次 |

re.match(r".*", 待匹配字符, re.S)这样就可以匹配到换行符,re.S叫做旗标
3.判断开头结尾
- 开头结尾必须全匹配上
- match默认会判断开头,但是不会判断结尾
1>小练习:判断变量名是否合法
name = input("请输入变量名")
re.match(r"^[a-zA-Z_][a-zA-Z0-9_]*$", name)
2>小练习:判断是否是身份证号
UID = input("请输入变量名")
re.match(r"\d{17}[01X]$", UID)
3>小练习:判断是否是邮箱
email = input("请输入变量名")
re.match(r"^[a-zA-Z0-9]+@[a-zA-Z0-9]+\.[a-zA-Z0-9]+$", email)
4.分组
email = input("请输入变量名")
re.match(r"^[a-zA-Z0-9]+@(163|126|qq)\.com$", email)
| 字符 |
功能 |
| | |
匹配左右任意一个表达式 |
| (ab) |
将括号中字符作为一个分组 |
| \num |
引用分组num匹配到的字符串 |
| (?P) |
分组起别名 |
| (?P=name) |
引用别名为name分组匹配到的字符串 |
- 在组 当中取数据:(取出的是小括号里,正则匹配到的值)
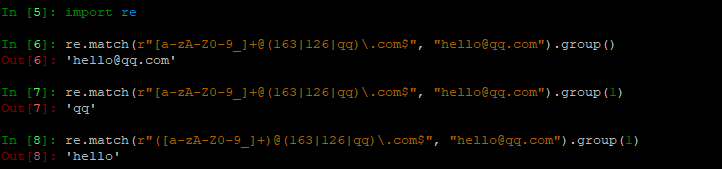
- 取出匹配的组值
\num

- 给分组取名
(?P<name>),取用别名(?P=name)

4.re的高级用法
- 前面的用法是通用的,后面的用法是python专用的(其它语言也可能有)
search
- match是从头开始匹配,search是任意位置开始匹配,只取第一个匹配到的位置
findall
- findall可以匹配到所有匹配的位置,返回一个列表
sub
re.sub(r"待替换", "替换为", "待匹配的字符串")
def add1(temp):
"""加一函数"""
num_str = temp.group()
num = int(num_str) + 1
return str(num)
ret = re.sub(r"\d+", add1, "998")
print(ret)
split
re.split(r";|:","一个;两个:三个")
5.小项目:清洗数据
- 从网上Down下一段网站的部分源码(我是去Boss直聘Down下了阿里的职位描述)

- 分析一波:清洗掉标签,可以用sub

- 效果:

