1.one-hot编码
- 给每个词分配一个数字ID,如“爸爸”=1=[010],“妈妈”=2=[001]
- 缺点(1)高维度,稀疏(2)词之间相互独立,无法表示词之间的语义
2.分布式表示
(1)基于矩阵的分布表示
- 词的相似度转换为向量的空间距离
- Global Vector模型
(2)基于聚类的分布表示
(3)基于神经网络的分布表示----词向量/词嵌入
- word embedding词嵌入空间
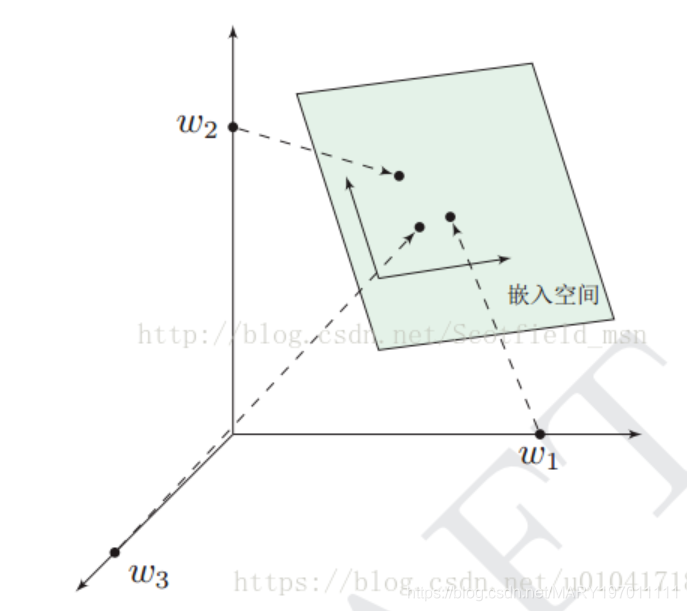
- 把one-hot的向量空间映射到低维、浮点数表示的向量空间中。


- 3.一般使用别人训练好的词向量,使用的语料库领域相同的。
3.word embedding代码
(1)安装gensim
gensim是处理word embeddings的python包
pip install gensim
(2)下载预训练好的词向量
google新闻训练的word2vec模型,Google Drive link:Google news Word2Vec
# Install the PyDrive wrapper & import libraries.
# This only needs to be done once per notebook.
!pip install -U -q PyDrive
from pydrive.auth import GoogleAuth
from pydrive.drive import GoogleDrive
from google.colab import auth
from oauth2client.client import GoogleCredentials
# Authenticate and create the PyDrive client.
# This only needs to be done once per notebook.
auth.authenticate_user()
gauth = GoogleAuth()
gauth.credentials = GoogleCredentials.get_application_default()
drive = GoogleDrive(gauth)
file_id = '0B7XkCwpI5KDYNlNUTTlSS21pQmM'
downloaded = drive.CreateFile({'id':file_id})
downloaded.FetchMetadata(fetch_all=True)
downloaded.GetContentFile(downloaded.metadata['title'])
(3)加载预训练的词向量
预训练的词向量里不包含停用词
from gensim.models.keyedvectors import KeyedVectors
gensim_model = KeyedVectors.load_word2vec_format(
'GoogleNews-vectors-negative300.bin', binary=True, limit=300000)
print('hello =', gensim_model['hello'])

(4)找相似词
gensim_model.most_similar(positive=['January'])
#组合词找相似词
gensim_model.most_similar(positive=['nature', 'science'])
#使用数学运算,寻找类似词
gensim_model.most_similar(positive=['king', 'woman'], negative=['man'])
