- 在网络爬虫爬取的过程,在待爬取的URL列表中,可能有很多URL地址,那么这些URL地址,爬虫应该先爬取哪个,后爬取哪个呢?在通用网络爬虫中,虽然爬取的顺序并不是那么重要,但是在其他很多爬虫中,比如聚焦网络爬虫中,爬取的顺序非常重要,而爬取的顺序,一般由爬行策略决定。
- 爬行策略主要有深度优先爬行策略、广度优先爬行策略、大站优先策略、反链策略、其他爬行策略等。
网站图:
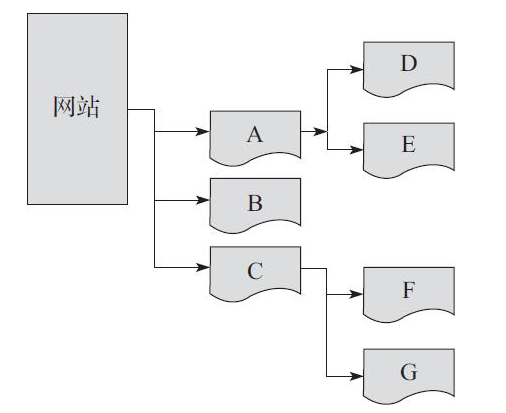
深度优先:
- 爬取一个网页,然后将这个网页的下层链接依次深入爬取完再返回上一层进行爬取。
- 爬行顺序可以是:A→D→E→B→C→F→G。
广度优先:
- 首先会爬取同一层次的网页,将同一层次的网页全部爬取完后,在选择下一个层次的网页去爬行
- 爬行顺序可以是:A→B→C→D→E→F→G。
大站爬行策略:
- 按对应网页所属的站点进行归类,如果某个网站的网页数量多,那么我们则将其称为大站,按照这种策略,网页数量越多的网站越大,然后,优先爬取大站中的网页URL地址。
反链策略:
- 一个网页的反向链接数,指的是该网页被其他网页指向的次数
- 哪个网页的反链数量越多,则哪个网页将被优先爬取(考虑可靠的反链数)
网页更新策略:
- 网页更新策略主要有3种:用户体验策略、历史数据策略、聚类分析策略等,
用户体验策略:
- 大部分用户都只会关注排名靠前的网页,所以,在爬虫服务器资源有限的情况下,爬虫会优先更新排名结果靠前的网页。
历史数据策略:
- 爬取中会保留对应网页的多个历史版本,并进行对应分析,依据这多个历史版本的内容更新、搜索质量影响、用户体验等信息,来确定对这些网页的爬取周期。
聚类分析策略:
- 共性进行相应分析,将共性较多的聚为一类
- 聚类分析算法运用
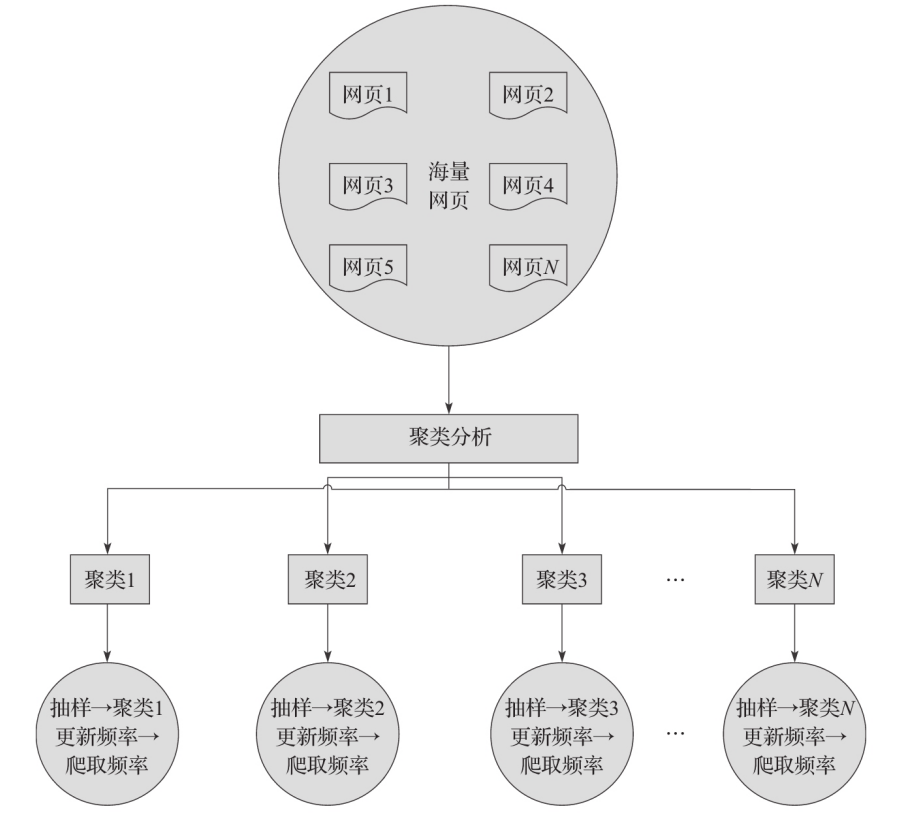
- 1)首先,经过大量的研究发现,网页可能具有不同的内容,但是一般来说,具有类似属性的网页,其更新频率类似。这是聚类分析算法运用在爬虫网页的更新上的一个前提指导思想。
- 2)有了1中的指导思想后,我们可以首先对海量的网页进行聚类分析,在聚类之后,会形成多个类,每个类中的网页具有类似的属性,即一般具有类似的更新频率。
- 3)聚类完成后,我们可以对同一个聚类中的网页进行抽样,然后求该抽样结果的平均更新值,从而确定对每个聚类的爬行频率。
网页分析算法:
1.基于用户行为的网页分析算法
- 依据用户对这些网页的访问行为,对这些网页进行评价,比如,依据用户对该网页的访问频率、用户对网页的访问时长、用户的单击率等信息对网页进行综合评价。
2.基于网络拓扑的网页分析算法
- 基于网络拓扑的网页分析算法是依靠网页的链接关系、结构关系、已知网页或数据等对网页进行分析的一种算法,所谓拓扑,简单来说即结构关系的意思。
- 细分为3种类型:基于网页粒度的分析算法、基于网页块粒度的分析算法、基于网站粒度的分析算法。
网页粒度分析算法:
PageRank算法
- 根据网页之间的链接关系对网页的权重进行计算,并可以依靠这些计算出来的权重,对网页进行排名。
基于网页块粒度的分析算法
- 基于网页块粒度的分析算法,也是依靠网页间链接关系进行计算的,但计算规则有所不同。
- 一个网页中通常会包含多个超链接,但一般其指向的外部链接中并不是所有的链接都与网站主题相关,或者说,这些外部链接对该网页的重要程度是不一样的,所以若要基于网页块粒度进行分析,则需要对一个网页中的这些外部链接划分层次,不同层次的外部链接对于该网页来说,其重要程度不同。这种算法的分析效率和准确率,会比传统的算法好一些。
基于网站粒度的分析算法
- 会划分站点的层次和等级,而不再具体地计算站点下的各个网页的等级。相对于基于网页粒度的算法来说,则更加简单高效,但是会带来一些缺点,比如精确度不如基于网页粒度的分析算法精确。
3.基于网页内容的网页分析算法
- 基于网页内容的网页分析算法中,会依据网页的数据、文本等网页内容特征,对网页进行相应的评价。
身份识别:
- 爬虫对网页爬取的过程中,爬虫必然需要访问对应的网页,正规的爬虫一般会告诉对应网页的网站站长其爬虫身份。网站的管理员则可以通过爬虫告知的身份信息对爬虫的身份进行识别
- 一般爬虫在对网页进行爬取访问的时候,会通过HTTP请求中的User Agent字段告知自己的身份信息
- 一般爬虫访问一个网站的时候,首先会根据该站点下的Robots.txt文件来确定可爬取的网页范围,Robots协议是需要网络爬虫共同遵守的协议,对于一些禁止的URL地址,网络爬虫则不应爬取访问。
- 如果爬虫在爬取某一个站点时陷入死循环,造成该站点的服务压力过大,如果有正确的身份设置,那么该站点的站长则可以想办法联系到该爬虫方,然后停止对应的爬虫程序。
- 有些爬虫会伪装成其他爬虫或浏览器去爬取网站,以获得一些额外数据,或者有些爬虫,会无视Robots协议的限制而任意爬取。
爬虫实现技术:
开发网络爬虫的语言有很多,常见的语言有:Python、Java、PHP、Node.JS、C++、Go语言等。
- Python:爬虫框架非常丰富,并且多线程的处理能力较强,并且简单易学、代码简洁,优点很多。
- Java:适合开发大型爬虫项目。
- PHP:后端处理很强,代码很简洁,模块也较丰富,但是并发能力相对来说较弱。
- Node.JS:支持高并发与多线程处理。
- C++:运行速度快,适合开发大型爬虫项目,成本较高。
- Go语言:同样高并发能力非常强。